 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning as Data: Representation-Computation Unity and Its Implementation in a Domain-Algebraic Inference Engine
Apr 13, 2026Every existing knowledge system separates storage from computation. We show this separation is unnecessary and eliminate it. In a standard triple is_a(Apple, Company), domain context lives in the query or the programmer's mind. In a CDC four-tuple is_a(Apple, Company, @Business), domain becomes a structural field embedded in predicate arity. Any system respecting arity automatically performs domain-scoped inference without external rules. We call this representation-computation unity (RCU). From the four-tuple structure, three inference mechanisms emerge: domain-scoped closure, typed inheritance, and write-time falsification via cycle detection per domain fiber. We establish RCU formally via four theorems. RCU is implementable. We present a working symbolic engine (2400 lines Python+Prolog) resolving four engineering issues: rule-data separation, shared-fiber handling, read-only meta-layer design, and intersective convergence. A central result: CDC domain-constrained inference is distinct from Prolog with a domain argument. Two case studies validate the engine. ICD-11 classification (1247 entities, 3 axes) shows fibers resolve multiple inheritance. CBT clinical reasoning shows generalization to temporal reasoning with session turn as ordered domain index. Multi-constraint queries realize CSP arc-consistency with complexity O(m (N/K)^2), confirming the domain lattice's sparsity governs performance. When domain is structural, data computes itself.
Domain-Contextualized Inference: A Computable Graph Architecture for Explicit-Domain Reasoning
Apr 06, 2026We establish a computation-substrate-agnostic inference architecture in which domain is an explicit first-class computational parameter. This produces domain-scoped pruning that reduces per-query search space from O(N) to O(N/K), substrate-independent execution over symbolic, neural, vector, and hybrid substrates, and transparent inference chains where every step carries its evaluative context. The contribution is architectural, not logical. We formalize the computational theory across five dimensions: a five-layer architecture; three domain computation modes including chain indexing, path traversal as Kleisli composition, and vector-guided computation as a substrate transition; a substrate-agnostic interface with three operations Query, Extend, Bridge; reliability conditions C1 to C4 with three failure mode classes; and validation through a PHQ-9 clinical reasoning case study. The computational theory including operational semantics, complexity bounds, monad structure, substrate transitions, and boundary conditions is the contribution of this paper.
Domain-constrained knowledge representation: A modal framework
Apr 02, 2026Knowledge graphs store large numbers of relations efficiently, but they remain weak at representing a quieter difficulty: the meaning of a concept often shifts with the domain in which it is used. A triple such as Apple, instance-of, Company may be acceptable in one setting while being misleading or unusable in another. In most current systems, domain information is attached as metadata, qualifiers, or graph-level organization. These mechanisms help with filtering and provenance, but they usually do not alter the formal status of the assertion itself. This paper argues that domain should be treated as part of knowledge representation rather than as supplementary annotation. It introduces the Domain-Contextualized Concept Graph (DCG), a framework in which domain is written into the relation and interpreted as a modal world constraint. In the DCG form (C, R at D, C'), the marker at D identifies the world in which the relation holds. Formally, the relation is interpreted through a domain-indexed necessity operator, so that truth, inference, and conflict checking are all scoped to the relevant world. This move has three consequences: ambiguous concepts can be disambiguated at the point of representation; invalid assertions can be challenged against their domain; cross-domain relations can be connected through explicit predicates. The paper develops this claim through a Kripke-style semantics, a compact predicate system, a Prolog implementation, and mappings to RDF, OWL, and relational databases. The contribution is a representational reinterpretation of domain itself. The central claim is that many practical failures in knowledge systems begin when domain is treated as external to the assertion. DCG addresses that by giving domain a structural and computable role inside the representation.
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
UniPLV: Towards Label-Efficient Open-World 3D Scene Understanding by Regional Visual Language Supervision
Dec 24, 2024We present UniPLV, a powerful framework that unifies point clouds, images and text in a single learning paradigm for open-world 3D scene understanding. UniPLV employs the image modal as a bridge to co-embed 3D points with pre-aligned images and text in a shared feature space without requiring carefully crafted point cloud text pairs. To accomplish multi-modal alignment, we propose two key strategies:(i) logit and feature distillation modules between images and point clouds, and (ii) a vison-point matching module is given to explicitly correct the misalignment caused by points to pixels projection. To further improve the performance of our unified framework, we adopt four task-specific losses and a two-stage training strategy. Extensive experiments show that our method outperforms the state-of-the-art methods by an average of 15.6% and 14.8% for semantic segmentation over Base-Annotated and Annotation-Free tasks, respectively. The code will be released later.
Empirical Bayesian Approaches for Robust Constraint-based Causal Discovery under Insufficient Data
Jun 16, 2022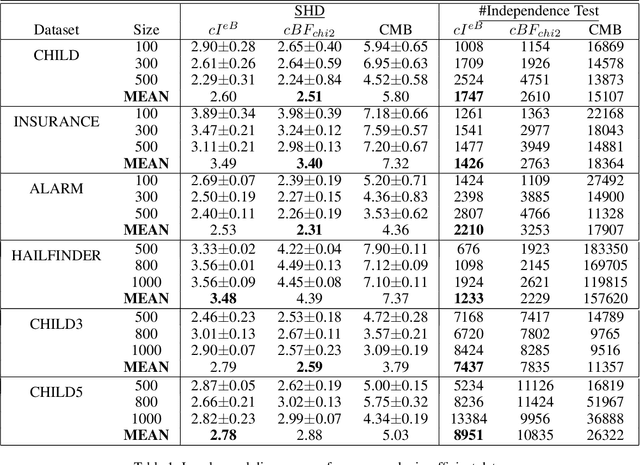
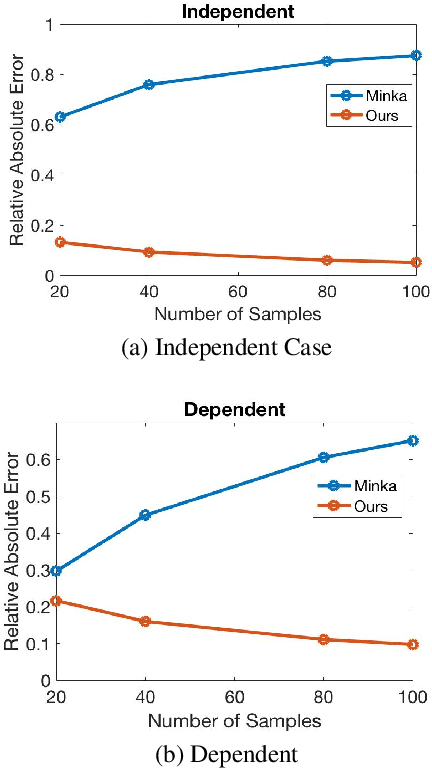
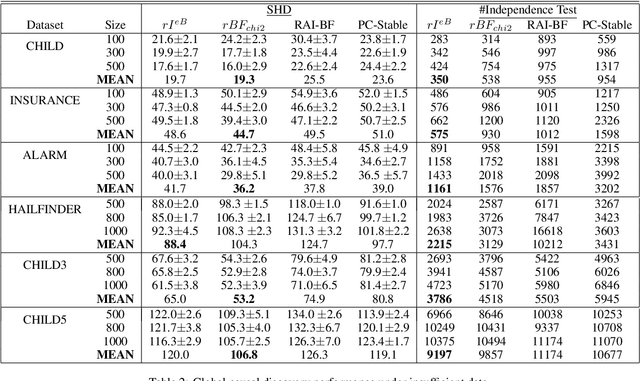
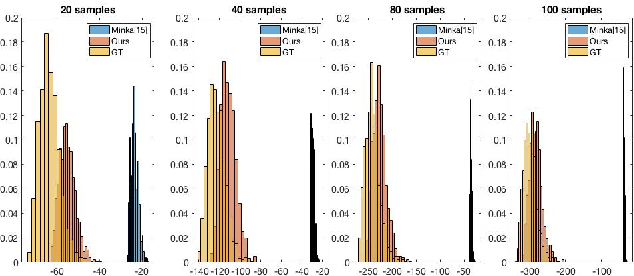
Causal discovery is to learn cause-effect relationships among variables given observational data and is important for many applications. Existing causal discovery methods assume data sufficiency, which may not be the case in many real world datasets. As a result, many existing causal discovery methods can fail under limited data. In this work, we propose Bayesian-augmented frequentist independence tests to improve the performance of constraint-based causal discovery methods under insufficient data: 1) We firstly introduce a Bayesian method to estimate mutual information (MI), based on which we propose a robust MI based independence test; 2) Secondly, we consider the Bayesian estimation of hypothesis likelihood and incorporate it into a well-defined statistical test, resulting in a robust statistical testing based independence test. We apply proposed independence tests to constraint-based causal discovery methods and evaluate the performance on benchmark datasets with insufficient samples. Experiments show significant performance improvement in terms of both accuracy and efficiency over SOTA methods.