 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Real-world X-ray Security Inspection: A High-Quality Benchmark and Lateral Inhibition Module for Prohibited Items Detection
Aug 23, 2021
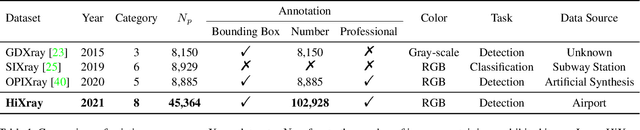
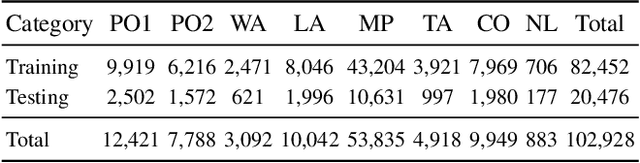

Prohibited items detection in X-ray images often plays an important role in protecting public safety, which often deals with color-monotonous and luster-insufficient objects, resulting in unsatisfactory performance. Till now, there have been rare studies touching this topic due to the lack of specialized high-quality datasets. In this work, we first present a High-quality X-ray (HiXray) security inspection image dataset, which contains 102,928 common prohibited items of 8 categories. It is the largest dataset of high quality for prohibited items detection, gathered from the real-world airport security inspection and annotated by professional security inspectors. Besides, for accurate prohibited item detection, we further propose the Lateral Inhibition Module (LIM) inspired by the fact that humans recognize these items by ignoring irrelevant information and focusing on identifiable characteristics, especially when objects are overlapped with each other. Specifically, LIM, the elaborately designed flexible additional module, suppresses the noisy information flowing maximumly by the Bidirectional Propagation (BP) module and activates the most identifiable charismatic, boundary, from four directions by Boundary Activation (BA) module. We evaluate our method extensively on HiXray and OPIXray and the results demonstrate that it outperforms SOTA detection methods.
A Comprehensive Evaluation Framework for Deep Model Robustness
Jan 24, 2021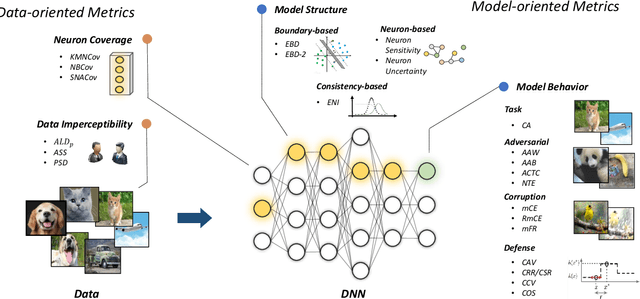
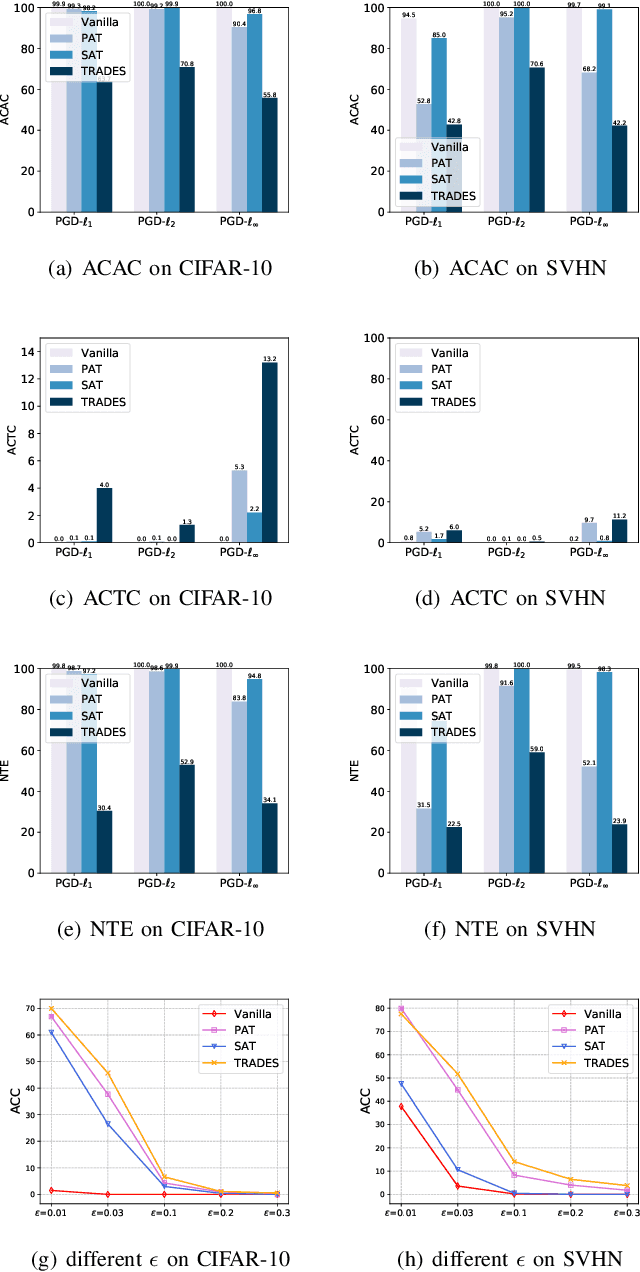
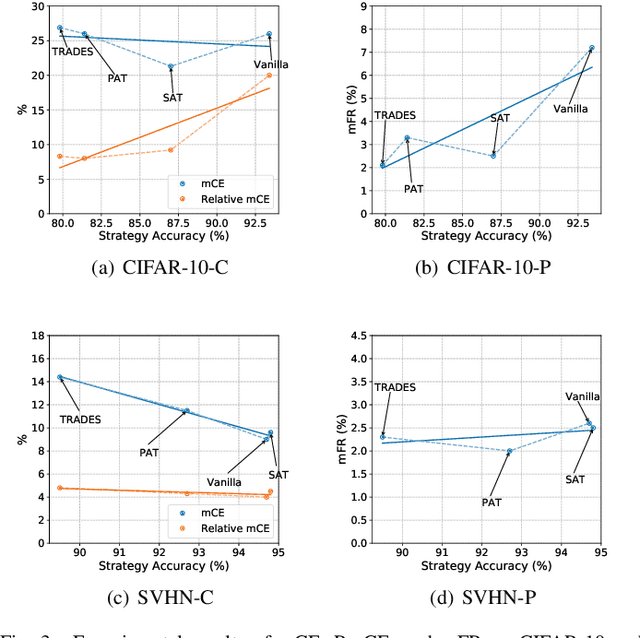
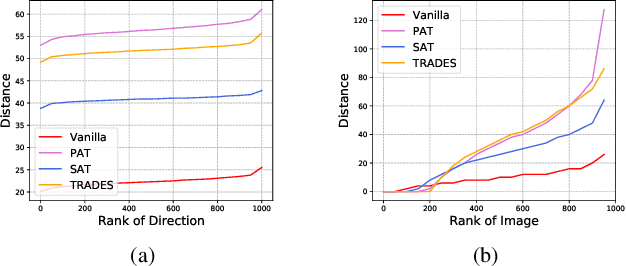
Deep neural networks (DNNs) have achieved remarkable performance across a wide area of applications. However, they are vulnerable to adversarial examples, which motivates the adversarial defense. By adopting simple evaluation metrics, most of the current defenses only conduct incomplete evaluations, which are far from providing comprehensive understandings of the limitations of these defenses. Thus, most proposed defenses are quickly shown to be attacked successfully, which result in the "arm race" phenomenon between attack and defense. To mitigate this problem, we establish a model robustness evaluation framework containing a comprehensive, rigorous, and coherent set of evaluation metrics, which could fully evaluate model robustness and provide deep insights into building robust models. With 23 evaluation metrics in total, our framework primarily focuses on the two key factors of adversarial learning (\ie, data and model). Through neuron coverage and data imperceptibility, we use data-oriented metrics to measure the integrity of test examples; by delving into model structure and behavior, we exploit model-oriented metrics to further evaluate robustness in the adversarial setting. To fully demonstrate the effectiveness of our framework, we conduct large-scale experiments on multiple datasets including CIFAR-10 and SVHN using different models and defenses with our open-source platform AISafety. Overall, our paper aims to provide a comprehensive evaluation framework which could demonstrate detailed inspections of the model robustness, and we hope that our paper can inspire further improvement to the model robustness.
Occluded Prohibited Items Detection: An X-ray Security Inspection Benchmark and De-occlusion Attention Module
May 26, 2020
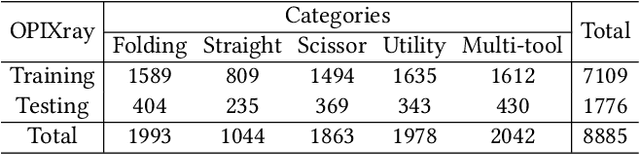
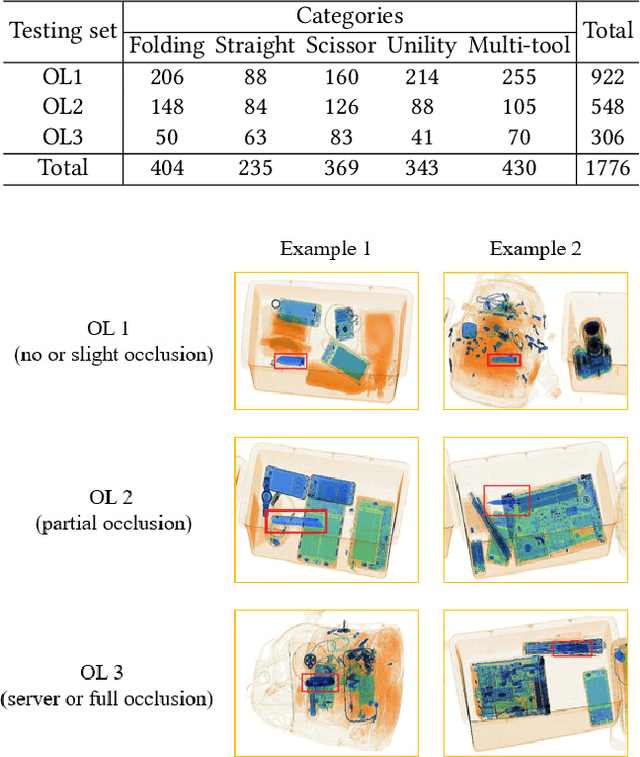
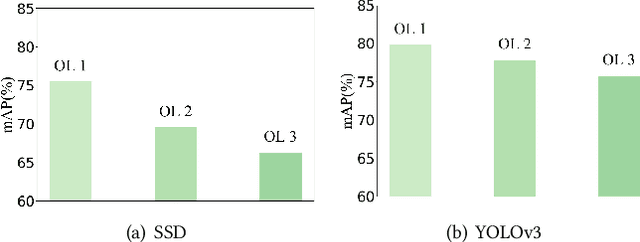
Security inspection often deals with a piece of baggage or suitcase where objects are heavily overlapped with each other, resulting in an unsatisfactory performance for prohibited items detection in X-ray images. In the literature, there have been rare studies and datasets touching this important topic. In this work, we contribute the first high-quality object detection dataset for security inspection, named Occluded Prohibited Items X-ray (OPIXray) image benchmark. OPIXray focused on the widely-occurred prohibited item "cutter", annotated manually by professional inspectors from the international airport. The test set is further divided into three occlusion levels to better understand the performance of detectors. Furthermore, to deal with the occlusion in X-ray images detection, we propose the De-occlusion Attention Module (DOAM), a plug-and-play module that can be easily inserted into and thus promote most popular detectors. Despite the heavy occlusion in X-ray imaging, shape appearance of objects can be preserved well, and meanwhile different materials visually appear with different colors and textures. Motivated by these observations, our DOAM simultaneously leverages the different appearance information of the prohibited item to generate the attention map, which helps refine feature maps for the general detectors. We comprehensively evaluate our module on the OPIXray dataset, and demonstrate that our module can consistently improve the performance of the state-of-the-art detection methods such as SSD, FCOS, etc, and significantly outperforms several widely-used attention mechanisms. In particular, the advantages of DOAM are more significant in the scenarios with higher levels of occlusion, which demonstrates its potential application in real-world inspections. The OPIXray benchmark and our model are released at https://github.com/OPIXray-author/OPIXray.
Adversarial Attacks for Embodied Agents
May 19, 2020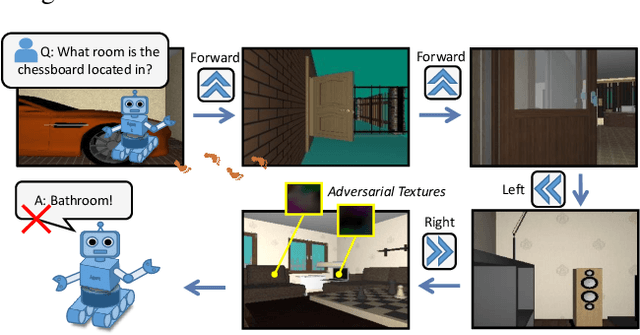
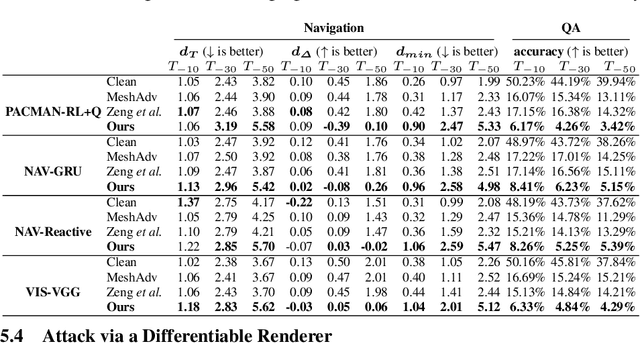
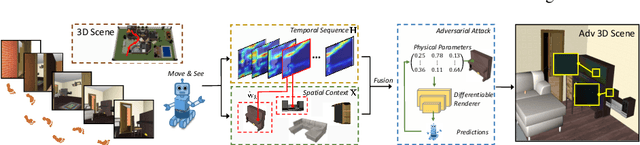

Adversarial attacks are valuable for providing insights into the blind-spots of deep learning models and help improve their robustness. Existing work on adversarial attacks have mainly focused on static scenes; however, it remains unclear whether such attacks are effective against embodied agents, which could navigate and interact with a dynamic environment. In this work, we take the first step to study adversarial attacks for embodied agents. In particular, we generate spatiotemporal perturbations to form 3D adversarial examples, which exploit the interaction history in both the temporal and spatial dimensions. Regarding the temporal dimension, since agents make predictions based on historical observations, we develop a trajectory attention module to explore scene view contributions, which further help localize 3D objects appeared with the highest stimuli. By conciliating with clues from the temporal dimension, along the spatial dimension, we adversarially perturb the physical properties (e.g., texture and 3D shape) of the contextual objects that appeared in the most important scene views. Extensive experiments on the EQA-v1 dataset for several embodied tasks in both the white-box and black-box settings have been conducted, which demonstrate that our perturbations have strong attack and generalization abilities.
Hierarchical Rule Induction Network for Abstract Visual Reasoning
Feb 17, 2020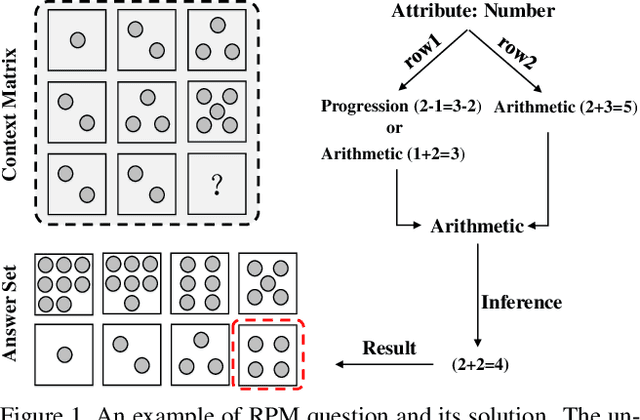
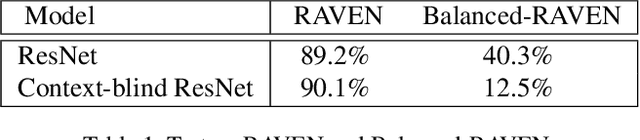
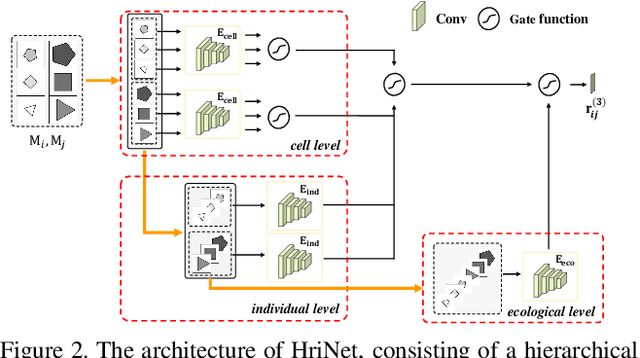

Abstract reasoning refers to the ability to analyze information, discover rules at an intangible level, and solve problems in innovative ways. Raven's Progressive Matrices (RPM) test is typically used to examine the capability of abstract reasoning. In the test, the subject is asked to identify the correct choice from the answer set to fill the missing panel at the bottom right of RPM (e.g., a 3$\times$3 matrix), following the underlying rules inside the matrix. Recent studies, taking advantage of Convolutional Neural Networks (CNNs), have achieved encouraging progress to accomplish the RPM test problems. Unfortunately, simply relying on the relation extraction at the matrix level, they fail to recognize the complex attribute patterns inside or across rows/columns of RPM. To address this problem, in this paper we propose a Hierarchical Rule Induction Network (HriNet), by intimating human induction strategies. HriNet extracts multiple granularity rule embeddings at different levels and integrates them through a gated embedding fusion module. We further introduce a rule similarity metric based on the embeddings, so that HriNet can not only be trained using a tuplet loss but also infer the best answer according to the similarity score. To comprehensively evaluate HriNet, we first fix the defects contained in the very recent RAVEN dataset and generate a new one named Balanced-RAVEN. Then extensive experiments are conducted on the large-scale dataset PGM and our Balanced-RAVEN, the results of which show that HriNet outperforms the state-of-the-art models by a large margin.
Region-wise Generative Adversarial ImageInpainting for Large Missing Areas
Sep 27, 2019

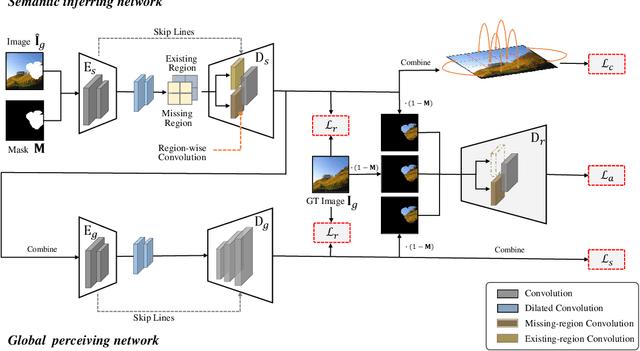
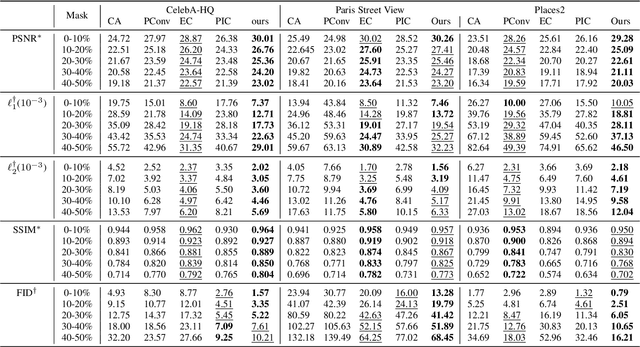
Recently deep neutral networks have achieved promising performance for filling large missing regions in image inpainting tasks. They usually adopted the standard convolutional architecture over the corrupted image, leading to meaningless contents, such as color discrepancy, blur and artifacts. Moreover, most inpainting approaches cannot well handle the large continuous missing area cases. To address these problems, we propose a generic inpainting framework capable of handling with incomplete images on both continuous and discontinuous large missing areas, in an adversarial manner. From which, region-wise convolution is deployed in both generator and discriminator to separately handle with the different regions, namely existing regions and missing ones. Moreover, a correlation loss is introduced to capture the non-local correlations between different patches, and thus guides the generator to obtain more information during inference. With the help of our proposed framework, we can restore semantically reasonable and visually realistic images. Extensive experiments on three widely-used datasets for image inpainting tasks have been conducted, and both qualitative and quantitative experimental results demonstrate that the proposed model significantly outperforms the state-of-the-art approaches, both on the large continuous and discontinuous missing areas.
Interpreting and Improving Adversarial Robustness with Neuron Sensitivity
Sep 16, 2019



Deep neural networks (DNNs) are vulnerable to adversarial examples where inputs with imperceptible perturbations mislead DNNs to incorrect results. Despite the potential risk they bring, adversarial examples are also valuable for providing insights into the weakness and blind-spots of DNNs. Thus, the interpretability of a DNN in adversarial setting aims to explain the rationale behind its decision-making process and makes deeper understanding which results in better practical applications. To address this issue, we try to explain adversarial robustness for deep models from a new perspective of neuron sensitivity which is measured by neuron behavior variation intensity against benign and adversarial examples. In this paper, we first draw the close connection between adversarial robustness and neuron sensitivities, as sensitive neurons make the most non-trivial contributions to model predictions in adversarial setting. Based on that, we further propose to improve adversarial robustness by constraining the similarities of sensitive neurons between benign and adversarial examples which stabilizes the behaviors of sensitive neurons in adversarial setting. Moreover, we demonstrate that state-of-the-art adversarial training methods improve model robustness by reducing neuron sensitivities which in turn confirms the strong connections between adversarial robustness and neuron sensitivity as well as the effectiveness of using sensitive neurons to build robust models. Extensive experiments on various datasets demonstrate that our algorithm effectively achieve excellent results.