 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel What Matters: Modality-Balanced and Difficulty-Aware Multimodal Active Learning
Mar 26, 2026Multimodal learning integrates complementary information from different modalities such as image, text, and audio to improve model performance, but its success relies on large-scale labeled data, which is costly to obtain. Active learning (AL) mitigates this challenge by selectively annotating informative samples. In multimodal settings, many approaches implicitly assume that modality importance is stable across rounds and keep selection rules fixed at the fusion stage, which leaves them insensitive to the dynamic nature of multimodal learning, where the relative value of modalities and the difficulty of instances shift as training proceeds. To address this issue, we propose RL-MBA, a reinforcement-learning framework for modality-balanced, difficulty-aware multimodal active learning. RL-MBA models sample selection as a Markov Decision Process, where the policy adapts to modality contributions, uncertainty, and diversity, and the reward encourages accuracy gains and balance. Two key components drive this adaptability: (1) Adaptive Modality Contribution Balancing (AMCB), which dynamically adjusts modality weights via reinforcement feedback, and (2) Evidential Fusion for DifficultyAware Policy Adjustment (EFDA), which estimates sample difficulty via uncertainty-based evidential fusion to prioritize informative samples. Experiments on Food101, KineticsSound, and VGGSound demonstrate that RL-MBA consistently outperforms strong baselines, improving both classification accuracy and modality fairness under limited labeling budgets.
CausalT5K: Diagnosing and Informing Refusal for Trustworthy Causal Reasoning of Skepticism, Sycophancy, Detection-Correction, and Rung Collapse
Feb 09, 2026LLM failures in causal reasoning, including sycophancy, rung collapse, and miscalibrated refusal, are well-documented, yet progress on remediation is slow because no benchmark enables systematic diagnosis. We introduce CausalT5K, a diagnostic benchmark of over 5,000 cases across 10 domains that tests three critical capabilities: (1) detecting rung collapse, where models answer interventional queries with associational evidence; (2) resisting sycophantic drift under adversarial pressure; and (3) generating Wise Refusals that specify missing information when evidence is underdetermined. Unlike synthetic benchmarks, CausalT5K embeds causal traps in realistic narratives and decomposes performance into Utility (sensitivity) and Safety (specificity), revealing failure modes invisible to aggregate accuracy. Developed through a rigorous human-machine collaborative pipeline involving 40 domain experts, iterative cross-validation cycles, and composite verification via rule-based, LLM, and human scoring, CausalT5K implements Pearl's Ladder of Causation as research infrastructure. Preliminary experiments reveal a Four-Quadrant Control Landscape where static audit policies universally fail, a finding that demonstrates CausalT5K's value for advancing trustworthy reasoning systems. Repository: https://github.com/genglongling/CausalT5kBench
Blur the Linguistic Boundary: Interpreting Chinese Buddhist Sutra in English via Neural Machine Translation
Sep 30, 2022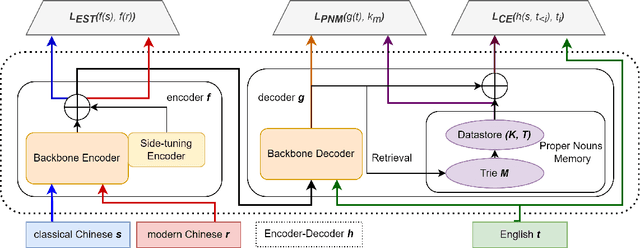
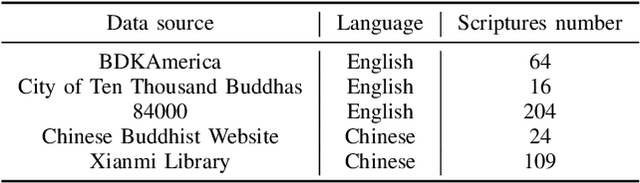

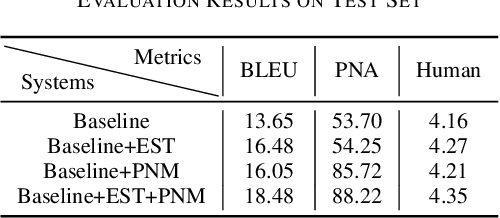
Buddhism is an influential religion with a long-standing history and profound philosophy. Nowadays, more and more people worldwide aspire to learn the essence of Buddhism, attaching importance to Buddhism dissemination. However, Buddhist scriptures written in classical Chinese are obscure to most people and machine translation applications. For instance, general Chinese-English neural machine translation (NMT) fails in this domain. In this paper, we proposed a novel approach to building a practical NMT model for Buddhist scriptures. The performance of our translation pipeline acquired highly promising results in ablation experiments under three criteria.