 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalT5K: Diagnosing and Informing Refusal for Trustworthy Causal Reasoning of Skepticism, Sycophancy, Detection-Correction, and Rung Collapse
Feb 09, 2026LLM failures in causal reasoning, including sycophancy, rung collapse, and miscalibrated refusal, are well-documented, yet progress on remediation is slow because no benchmark enables systematic diagnosis. We introduce CausalT5K, a diagnostic benchmark of over 5,000 cases across 10 domains that tests three critical capabilities: (1) detecting rung collapse, where models answer interventional queries with associational evidence; (2) resisting sycophantic drift under adversarial pressure; and (3) generating Wise Refusals that specify missing information when evidence is underdetermined. Unlike synthetic benchmarks, CausalT5K embeds causal traps in realistic narratives and decomposes performance into Utility (sensitivity) and Safety (specificity), revealing failure modes invisible to aggregate accuracy. Developed through a rigorous human-machine collaborative pipeline involving 40 domain experts, iterative cross-validation cycles, and composite verification via rule-based, LLM, and human scoring, CausalT5K implements Pearl's Ladder of Causation as research infrastructure. Preliminary experiments reveal a Four-Quadrant Control Landscape where static audit policies universally fail, a finding that demonstrates CausalT5K's value for advancing trustworthy reasoning systems. Repository: https://github.com/genglongling/CausalT5kBench
Feature-level Rating System using Customer Reviews and Review Votes
Jul 18, 2020
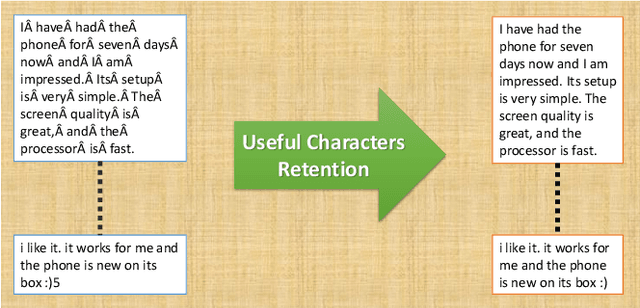
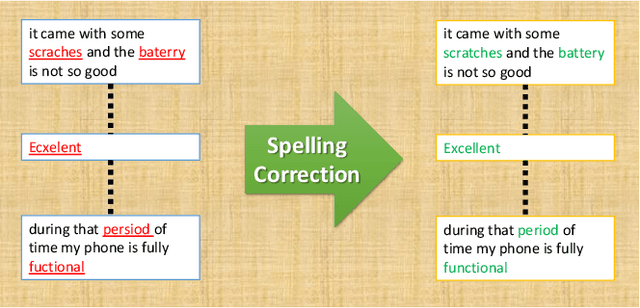

This work studies how we can obtain feature-level ratings of the mobile products from the customer reviews and review votes to influence decision making, both for new customers and manufacturers. Such a rating system gives a more comprehensive picture of the product than what a product-level rating system offers. While product-level ratings are too generic, feature-level ratings are particular; we exactly know what is good or bad about the product. There has always been a need to know which features fall short or are doing well according to the customer's perception. It keeps both the manufacturer and the customer well-informed in the decisions to make in improving the product and buying, respectively. Different customers are interested in different features. Thus, feature-level ratings can make buying decisions personalized. We analyze the customer reviews collected on an online shopping site (Amazon) about various mobile products and the review votes. Explicitly, we carry out a feature-focused sentiment analysis for this purpose. Eventually, our analysis yields ratings to 108 features for 4k+ mobiles sold online. It helps in decision making on how to improve the product (from the manufacturer's perspective) and in making the personalized buying decisions (from the buyer's perspective) a possibility. Our analysis has applications in recommender systems, consumer research, etc.