 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalT5K: Diagnosing and Informing Refusal for Trustworthy Causal Reasoning of Skepticism, Sycophancy, Detection-Correction, and Rung Collapse
Feb 09, 2026LLM failures in causal reasoning, including sycophancy, rung collapse, and miscalibrated refusal, are well-documented, yet progress on remediation is slow because no benchmark enables systematic diagnosis. We introduce CausalT5K, a diagnostic benchmark of over 5,000 cases across 10 domains that tests three critical capabilities: (1) detecting rung collapse, where models answer interventional queries with associational evidence; (2) resisting sycophantic drift under adversarial pressure; and (3) generating Wise Refusals that specify missing information when evidence is underdetermined. Unlike synthetic benchmarks, CausalT5K embeds causal traps in realistic narratives and decomposes performance into Utility (sensitivity) and Safety (specificity), revealing failure modes invisible to aggregate accuracy. Developed through a rigorous human-machine collaborative pipeline involving 40 domain experts, iterative cross-validation cycles, and composite verification via rule-based, LLM, and human scoring, CausalT5K implements Pearl's Ladder of Causation as research infrastructure. Preliminary experiments reveal a Four-Quadrant Control Landscape where static audit policies universally fail, a finding that demonstrates CausalT5K's value for advancing trustworthy reasoning systems. Repository: https://github.com/genglongling/CausalT5kBench
RAudit: A Blind Auditing Protocol for Large Language Model Reasoning
Jan 30, 2026Inference-time scaling can amplify reasoning pathologies: sycophancy, rung collapse, and premature certainty. We present RAudit, a diagnostic protocol for auditing LLM reasoning without ground truth access. The key constraint is blindness: the auditor evaluates only whether derivation steps support conclusions, enabling detection of trace-output inconsistency and, when latent competence exists, its recovery. RAudit measures process quality via CRIT-based reasonableness scores and varies critique formulation to study how social framing affects model response. We prove bounded correction and $O(\log(1/ε))$ termination. Experiments on mathematical reasoning (CAP-GSM8K) and causal judgment (CausalL2) reveal four mechanisms explaining model unreliability: (1) Latent Competence Suppression, where models derive correct answers then overwrite them under social pressure; (2) The False Competence Trap, where weaker judges mask sycophancy that stronger judges expose; (3) The Complexity-Vulnerability Tradeoff, where causal tasks induce more than 10 times higher sycophancy than mathematical tasks; and (4) Iatrogenic Critique, where authoritative correction harms weaker models. These findings challenge assumptions that capability implies robustness and that stronger feedback yields better outputs.
DRIVE: Dynamic Rule Inference and Verified Evaluation for Constraint-Aware Autonomous Driving
Aug 06, 2025Understanding and adhering to soft constraints is essential for safe and socially compliant autonomous driving. However, such constraints are often implicit, context-dependent, and difficult to specify explicitly. In this work, we present DRIVE, a novel framework for Dynamic Rule Inference and Verified Evaluation that models and evaluates human-like driving constraints from expert demonstrations. DRIVE leverages exponential-family likelihood modeling to estimate the feasibility of state transitions, constructing a probabilistic representation of soft behavioral rules that vary across driving contexts. These learned rule distributions are then embedded into a convex optimization-based planning module, enabling the generation of trajectories that are not only dynamically feasible but also compliant with inferred human preferences. Unlike prior approaches that rely on fixed constraint forms or purely reward-based modeling, DRIVE offers a unified framework that tightly couples rule inference with trajectory-level decision-making. It supports both data-driven constraint generalization and principled feasibility verification. We validate DRIVE on large-scale naturalistic driving datasets, including inD, highD, and RoundD, and benchmark it against representative inverse constraint learning and planning baselines. Experimental results show that DRIVE achieves 0.0% soft constraint violation rates, smoother trajectories, and stronger generalization across diverse driving scenarios. Verified evaluations further demonstrate the efficiency, explanability, and robustness of the framework for real-world deployment.
ALAS: A Stateful Multi-LLM Agent Framework for Disruption-Aware Planning
May 18, 2025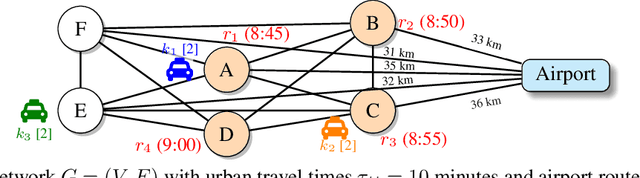

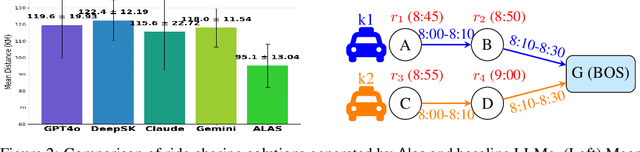
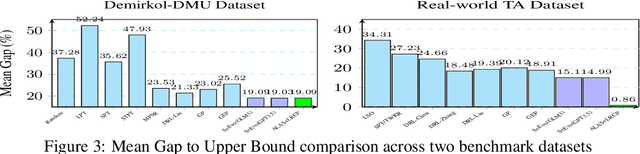
Large language models (LLMs) excel at rapid generation of text and multimodal content, yet they falter on transaction-style planning that demands ACID-like guarantees and real-time disruption recovery. We present Adaptive LLM Agent System (ALAS), a framework that tackles four fundamental LLM deficits: (i) absence of self-verification, (ii) context erosion, (iii) next-token myopia, and (iv) lack of persistent state. ALAS decomposes each plan into role-specialized agents, equips them with automatic state tracking, and coordinates them through a lightweight protocol. When disruptions arise, agents apply history-aware local compensation, avoiding costly global replanning and containing cascade effects. On real-world, large-scale job-shop scheduling benchmarks, ALAS sets new best results for static sequential planning and excels in dynamic reactive scenarios with unexpected disruptions. These gains show that principled modularization plus targeted compensation can unlock scalable and resilient planning with LLMs.
REALM-Bench: A Real-World Planning Benchmark for LLMs and Multi-Agent Systems
Feb 26, 2025This benchmark suite provides a comprehensive evaluation framework for assessing both individual LLMs and multi-agent systems in real-world planning scenarios. The suite encompasses eleven designed problems that progress from basic to highly complex, incorporating key aspects such as multi-agent coordination, inter-agent dependencies, and dynamic environmental disruptions. Each problem can be scaled along three dimensions: the number of parallel planning threads, the complexity of inter-dependencies, and the frequency of unexpected disruptions requiring real-time adaptation. The benchmark includes detailed specifications, evaluation metrics, and baseline implementations using contemporary frameworks like LangGraph, enabling rigorous testing of both single-agent and multi-agent planning capabilities. Through standardized evaluation criteria and scalable complexity, this benchmark aims to drive progress in developing more robust and adaptable AI planning systems for real-world applications.