 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePilotTTS: A Disciplined Modular Recipe for Competitive Speech Synthesis
May 27, 2026Building state-of-the-art text-to-speech (TTS) systems typically demands millions of hours of proprietary data and complex multi-stage architectures, creating substantial barriers for resource-constrained research teams. In this report, we present PilotTTS, a lightweight autoregressive TTS system that achieves competitive performance through minimalist architecture and rigorous data engineering. PilotTTS is trained on only 200K hours of data processed entirely with open-source tools. Specifically, our contributions are: (1) a reproducible multi-stage data processing pipeline covering quality assessment, label annotation, and filtering, and (2) a compact model architecture that employs Q-Former-based conditioning to decouple speaker identity from speaking style via cross-sample paired training. Within a unified framework, PilotTTS supports zero-shot voice cloning, emotion synthesis (11 categories), paralinguistic synthesis (4 categories), and Chinese dialect synthesis (14 dialects). On the Seed-TTS Eval benchmark, PilotTTS achieves the lowest WER of 1.50% on test-en, a CER of 0.87% on test-zh, and the highest speaker similarity on both test sets (0.862 and 0.815), outperforming systems trained on significantly larger datasets. We release the complete data pipeline recipe, pretrained weights, and code at https://github.com/AMAPVOICE/PilotTTS.
GrowLoop: Self-Evolving Conversation Evaluation Seeded by Human
May 26, 2026With the rapid advancement of large language models, evaluating human-likeness in open-ended conversation has become increasingly important. However, human-likeness is a form of tacit knowledge that humans perceive intuitively, yet the underlying criteria resist explicit formulation. Human judgments vary widely, with strong agreement on some cases and legitimate disagreement on others. Meanwhile, the criteria behind human judgments remain implicit, leaving no clear basis for constructing cases. Further, what counts as human-like is not static, but evolving with model capability and human expectations. Despite progress in evaluation methods such as expert-authored benchmarks, Reward Models, and self-evolving benchmarks, none addresses all three challenges simultaneously. Therefore, we propose GrowLoop, a self-evolving conversation evaluation system that continuously adapts as models advance and scenarios shift. With minimal human seed annotations as the first mover, LLM agents iteratively extract and refine evaluation rubrics through Heuristic Learning. Human-AI agreement is required where annotators converge, while only plausibility is expected where they diverge. Moreover, the Rubric-Case co-evolution mechanism enables continuous evolution, expanded through new seeds when the evaluation target moves. Applied to human-likeness evaluation in open-ended conversation, the generated rubrics not only substantially outperform existing methods in alignment with human judgments, but also uncover issues that annotators overlook. The resulting benchmark effectively discriminates models across capability tiers and reveals where they fall short, while generalizing to new scenarios and adapting as models advance. Our work shifts the benchmarking paradigm from manual updates or difficulty scaling to comprehensive, continuous self-evolution.
Recurrent Calibration Network for Irregular Text Recognition
Dec 18, 2018
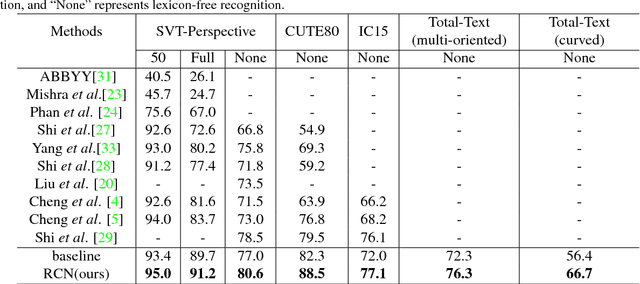
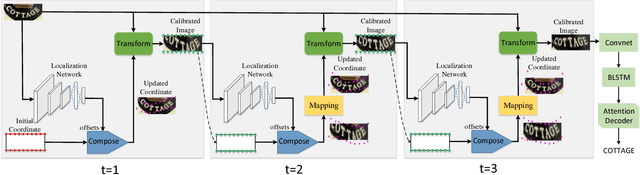
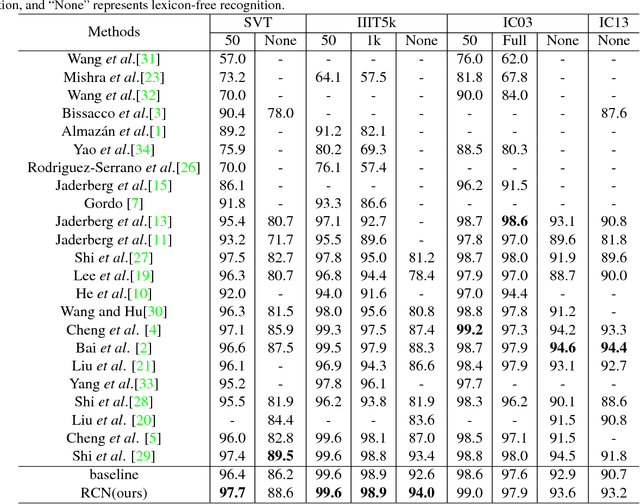
Scene text recognition has received increased attention in the research community. Text in the wild often possesses irregular arrangements, typically including perspective text, curved text, oriented text. Most existing methods are hard to work well for irregular text, especially for severely distorted text. In this paper, we propose a novel Recurrent Calibration Network (RCN) for irregular scene text recognition. The RCN progressively calibrates the irregular text to boost the recognition performance. By decomposing the calibration process into multiple steps, the irregular text can be calibrated to normal one step by step. Besides, in order to avoid the accumulation of lost information caused by inaccurate transformation, we further design a fiducial-point refinement structure to keep the integrity of text during the recurrent process. Instead of the calibrated images, the coordinates of fiducial points are tracked and refined, which implicitly models the transformation information. Based on the refined fiducial points, we estimate the transformation parameters and sample from the original image at each step. In this way, the original character information is preserved until the final transformation. Such designs lead to optimal calibration results to boost the performance of succeeding recognition. Extensive experiments on challenging datasets demonstrate the superiority of our method, especially on irregular benchmarks.
Reading Scene Text with Attention Convolutional Sequence Modeling
Sep 13, 2017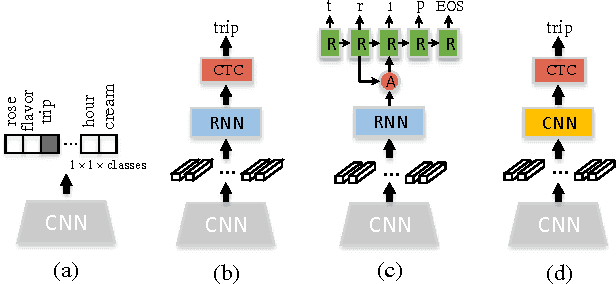
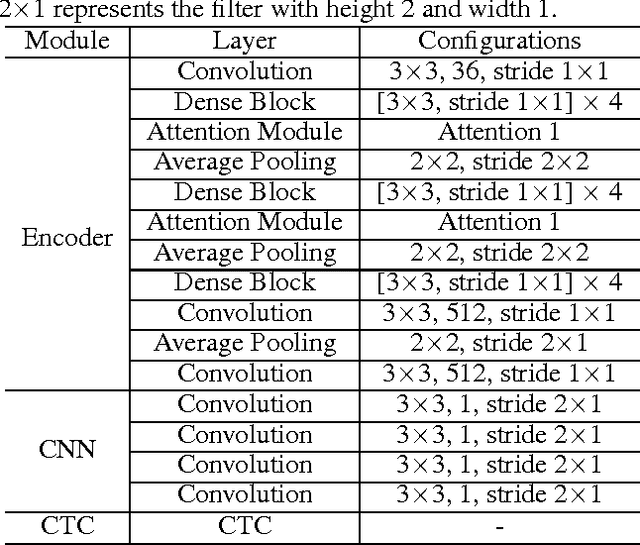
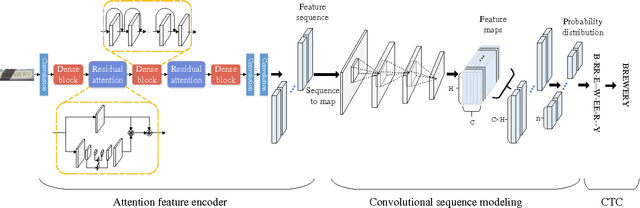
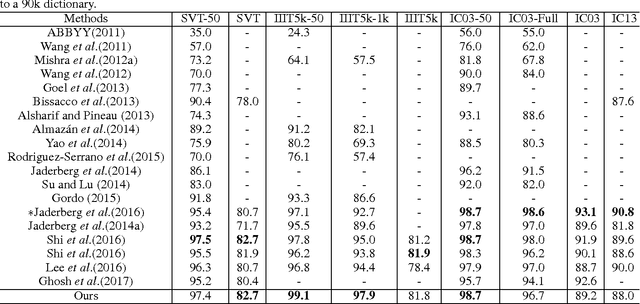
Reading text in the wild is a challenging task in the field of computer vision. Existing approaches mainly adopted Connectionist Temporal Classification (CTC) or Attention models based on Recurrent Neural Network (RNN), which is computationally expensive and hard to train. In this paper, we present an end-to-end Attention Convolutional Network for scene text recognition. Firstly, instead of RNN, we adopt the stacked convolutional layers to effectively capture the contextual dependencies of the input sequence, which is characterized by lower computational complexity and easier parallel computation. Compared to the chain structure of recurrent networks, the Convolutional Neural Network (CNN) provides a natural way to capture long-term dependencies between elements, which is 9 times faster than Bidirectional Long Short-Term Memory (BLSTM). Furthermore, in order to enhance the representation of foreground text and suppress the background noise, we incorporate the residual attention modules into a small densely connected network to improve the discriminability of CNN features. We validate the performance of our approach on the standard benchmarks, including the Street View Text, IIIT5K and ICDAR datasets. As a result, state-of-the-art or highly-competitive performance and efficiency show the superiority of the proposed approach.