 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Face Anti-Spoofing: A Survey
Jun 28, 2021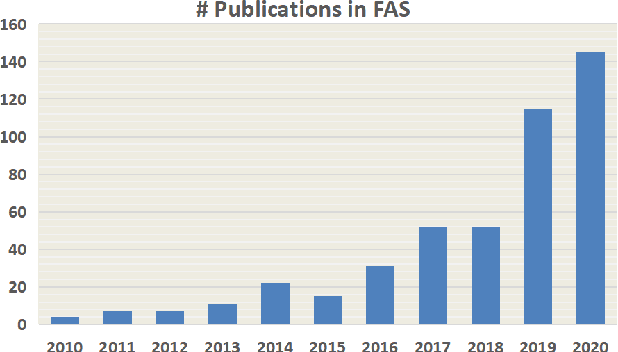
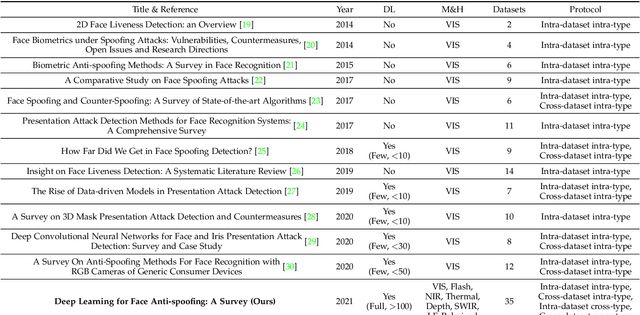
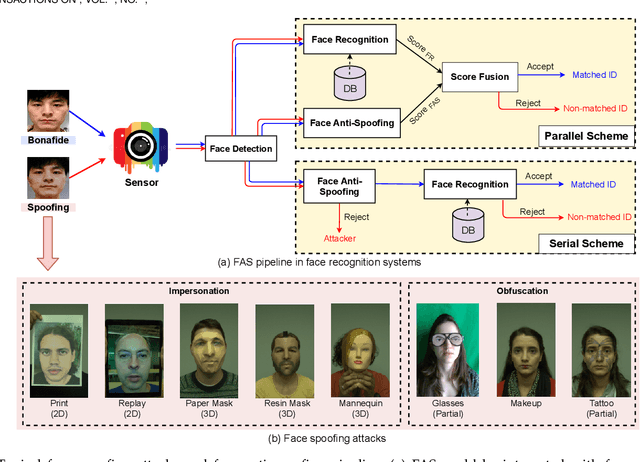
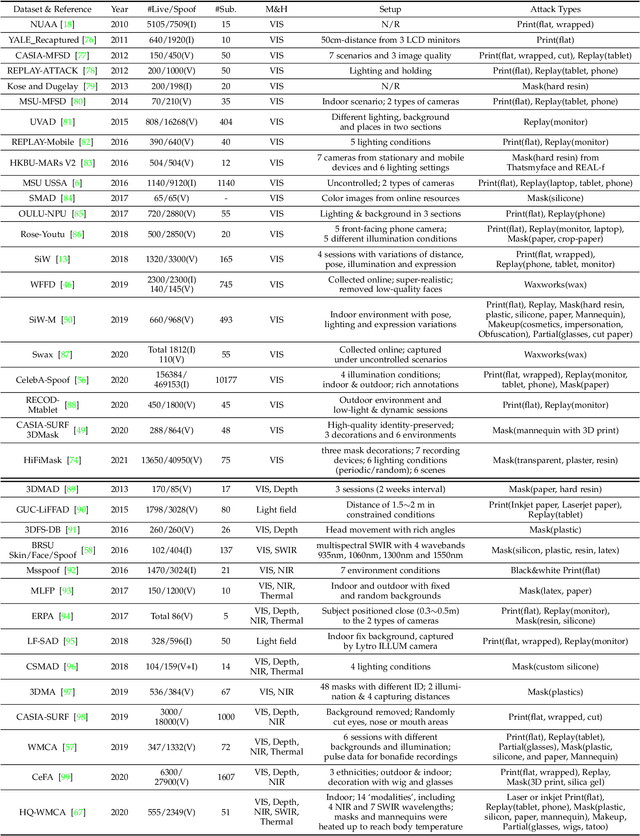
Face anti-spoofing (FAS) has lately attracted increasing attention due to its vital role in securing face recognition systems from presentation attacks (PAs). As more and more realistic PAs with novel types spring up, traditional FAS methods based on handcrafted features become unreliable due to their limited representation capacity. With the emergence of large-scale academic datasets in the recent decade, deep learning based FAS achieves remarkable performance and dominates this area. However, existing reviews in this field mainly focus on the handcrafted features, which are outdated and uninspiring for the progress of FAS community. In this paper, to stimulate future research, we present the first comprehensive review of recent advances in deep learning based FAS. It covers several novel and insightful components: 1) besides supervision with binary label (e.g., '0' for bonafide vs. '1' for PAs), we also investigate recent methods with pixel-wise supervision (e.g., pseudo depth map); 2) in addition to traditional intra-dataset evaluation, we collect and analyze the latest methods specially designed for domain generalization and open-set FAS; and 3) besides commercial RGB camera, we summarize the deep learning applications under multi-modal (e.g., depth and infrared) or specialized (e.g., light field and flash) sensors. We conclude this survey by emphasizing current open issues and highlighting potential prospects.
Dual-Cross Central Difference Network for Face Anti-Spoofing
May 04, 2021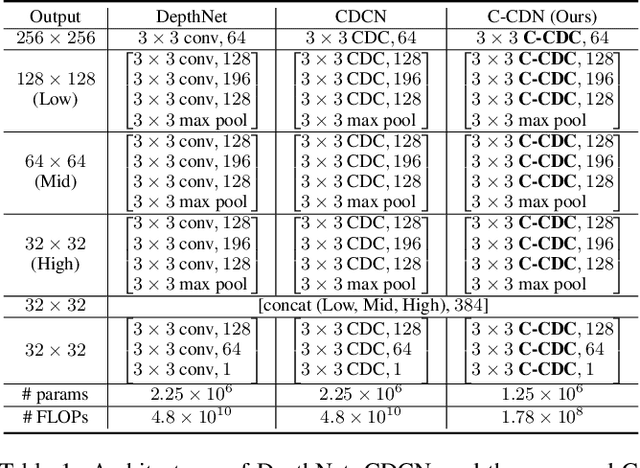
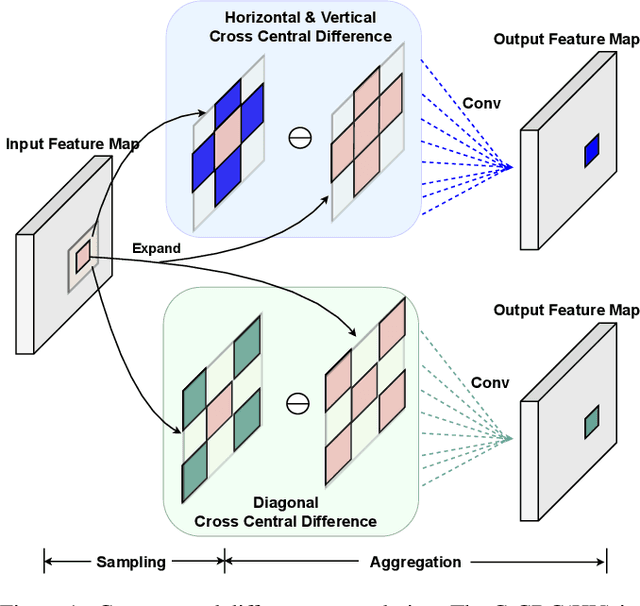
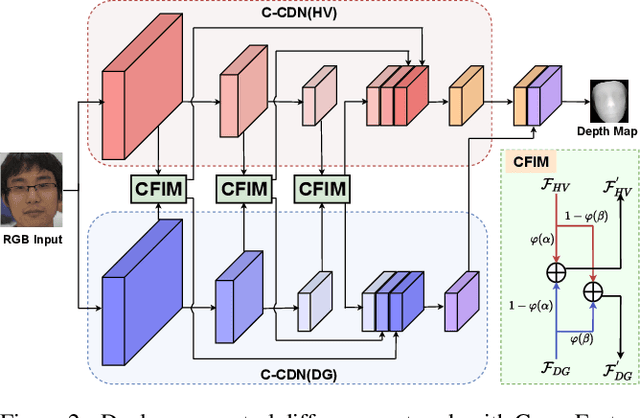
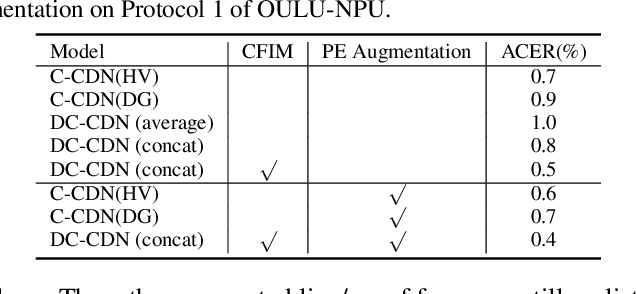
Face anti-spoofing (FAS) plays a vital role in securing face recognition systems. Recently, central difference convolution (CDC) has shown its excellent representation capacity for the FAS task via leveraging local gradient features. However, aggregating central difference clues from all neighbors/directions simultaneously makes the CDC redundant and sub-optimized in the training phase. In this paper, we propose two Cross Central Difference Convolutions (C-CDC), which exploit the difference of the center and surround sparse local features from the horizontal/vertical and diagonal directions, respectively. It is interesting to find that, with only five ninth parameters and less computational cost, C-CDC even outperforms the full directional CDC. Based on these two decoupled C-CDC, a powerful Dual-Cross Central Difference Network (DC-CDN) is established with Cross Feature Interaction Modules (CFIM) for mutual relation mining and local detailed representation enhancement. Furthermore, a novel Patch Exchange (PE) augmentation strategy for FAS is proposed via simply exchanging the face patches as well as their dense labels from random samples. Thus, the augmented samples contain richer live/spoof patterns and diverse domain distributions, which benefits the intrinsic and robust feature learning. Comprehensive experiments are performed on four benchmark datasets with three testing protocols to demonstrate our state-of-the-art performance.
Searching for Alignment in Face Recognition
Feb 10, 2021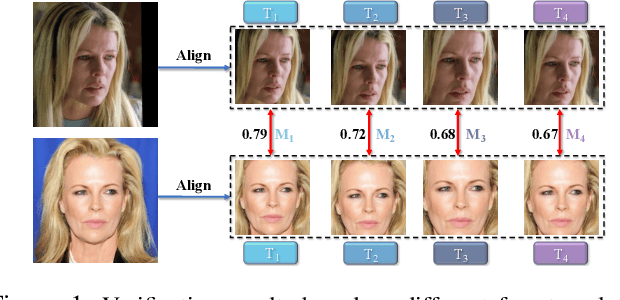
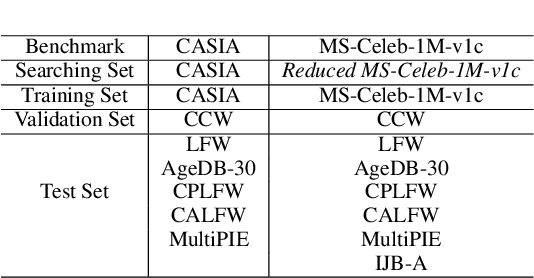
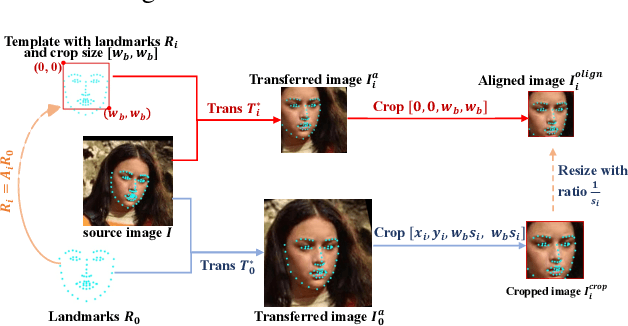
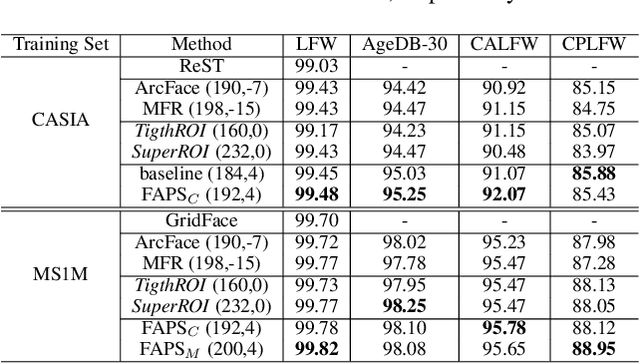
A standard pipeline of current face recognition frameworks consists of four individual steps: locating a face with a rough bounding box and several fiducial landmarks, aligning the face image using a pre-defined template, extracting representations and comparing. Among them, face detection, landmark detection and representation learning have long been studied and a lot of works have been proposed. As an essential step with a significant impact on recognition performance, the alignment step has attracted little attention. In this paper, we first explore and highlight the effects of different alignment templates on face recognition. Then, for the first time, we try to search for the optimal template automatically. We construct a well-defined searching space by decomposing the template searching into the crop size and vertical shift, and propose an efficient method Face Alignment Policy Search (FAPS). Besides, a well-designed benchmark is proposed to evaluate the searched policy. Experiments on our proposed benchmark validate the effectiveness of our method to improve face recognition performance.
NAS-FAS: Static-Dynamic Central Difference Network Search for Face Anti-Spoofing
Nov 03, 2020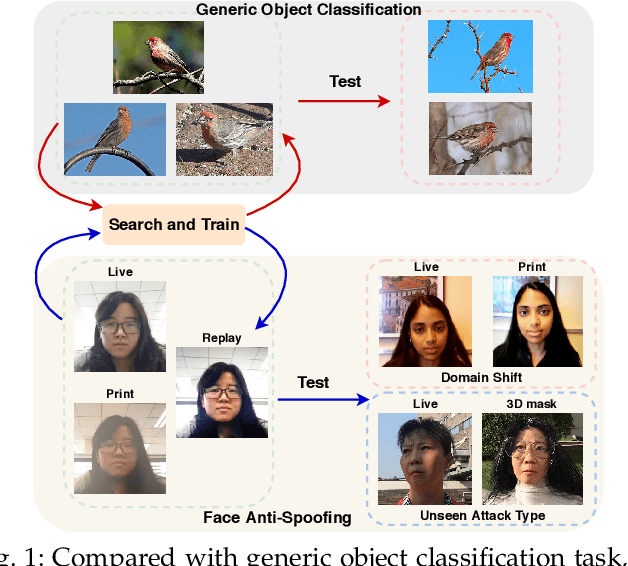
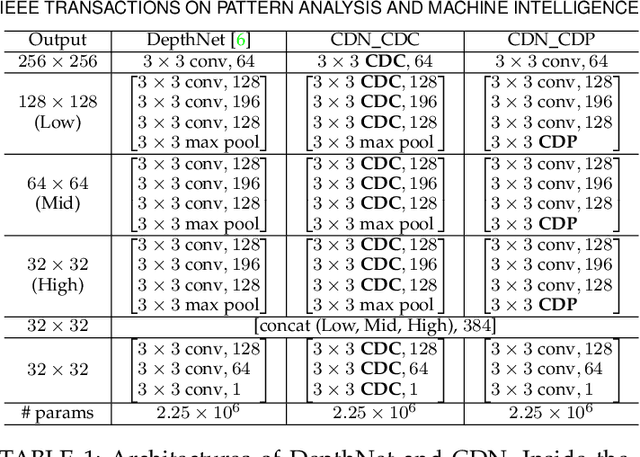
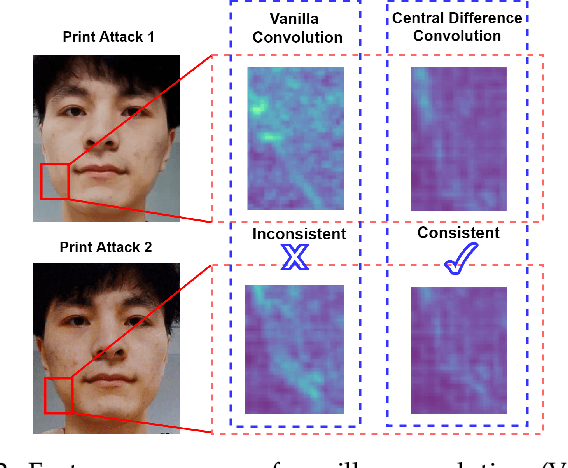
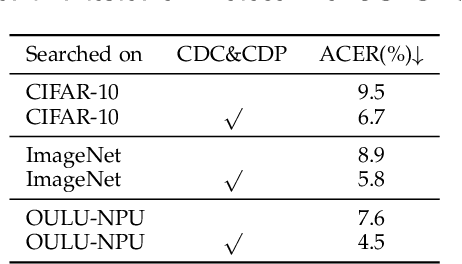
Face anti-spoofing (FAS) plays a vital role in securing face recognition systems. Existing methods heavily rely on the expert-designed networks, which may lead to a sub-optimal solution for FAS task. Here we propose the first FAS method based on neural architecture search (NAS), called NAS-FAS, to discover the well-suited task-aware networks. Unlike previous NAS works mainly focus on developing efficient search strategies in generic object classification, we pay more attention to study the search spaces for FAS task. The challenges of utilizing NAS for FAS are in two folds: the networks searched on 1) a specific acquisition condition might perform poorly in unseen conditions, and 2) particular spoofing attacks might generalize badly for unseen attacks. To overcome these two issues, we develop a novel search space consisting of central difference convolution and pooling operators. Moreover, an efficient static-dynamic representation is exploited for fully mining the FAS-aware spatio-temporal discrepancy. Besides, we propose Domain/Type-aware Meta-NAS, which leverages cross-domain/type knowledge for robust searching. Finally, in order to evaluate the NAS transferability for cross datasets and unknown attack types, we release a large-scale 3D mask dataset, namely CASIA-SURF 3DMask, for supporting the new 'cross-dataset cross-type' testing protocol. Experiments demonstrate that the proposed NAS-FAS achieves state-of-the-art performance on nine FAS benchmark datasets with four testing protocols.
Layer-Wise Adaptive Updating for Few-Shot Image Classification
Jul 16, 2020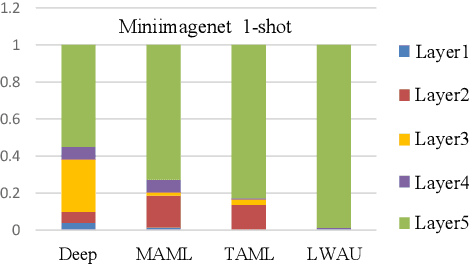
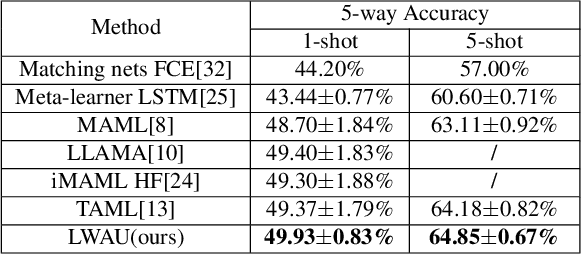
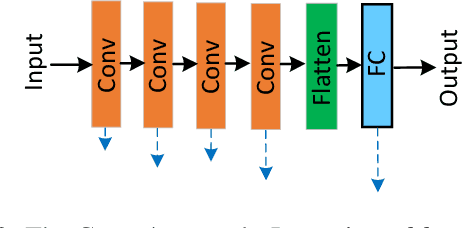
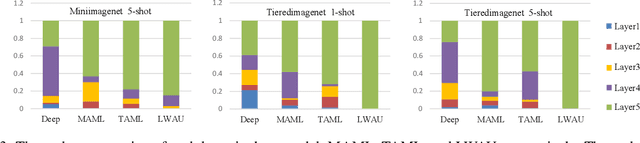
Few-shot image classification (FSIC), which requires a model to recognize new categories via learning from few images of these categories, has attracted lots of attention. Recently, meta-learning based methods have been shown as a promising direction for FSIC. Commonly, they train a meta-learner (meta-learning model) to learn easy fine-tuning weight, and when solving an FSIC task, the meta-learner efficiently fine-tunes itself to a task-specific model by updating itself on few images of the task. In this paper, we propose a novel meta-learning based layer-wise adaptive updating (LWAU) method for FSIC. LWAU is inspired by an interesting finding that compared with common deep models, the meta-learner pays much more attention to update its top layer when learning from few images. According to this finding, we assume that the meta-learner may greatly prefer updating its top layer to updating its bottom layers for better FSIC performance. Therefore, in LWAU, the meta-learner is trained to learn not only the easy fine-tuning model but also its favorite layer-wise adaptive updating rule to improve its learning efficiency. Extensive experiments show that with the layer-wise adaptive updating rule, the proposed LWAU: 1) outperforms existing few-shot classification methods with a clear margin; 2) learns from few images more efficiently by at least 5 times than existing meta-learners when solving FSIC.
Multi-Modal Face Anti-Spoofing Based on Central Difference Networks
Apr 17, 2020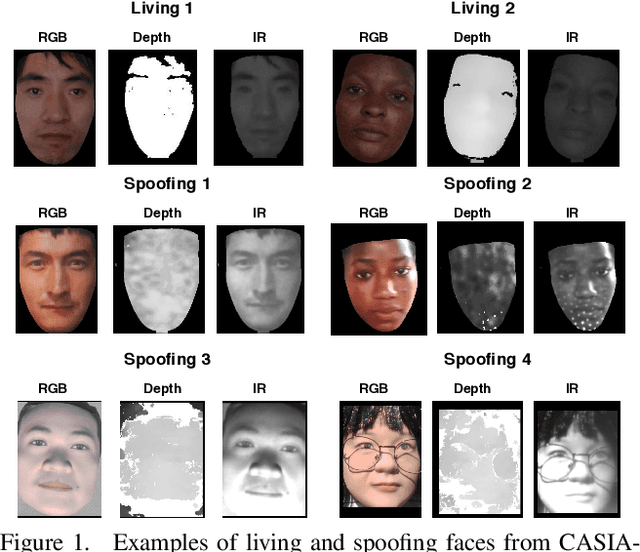
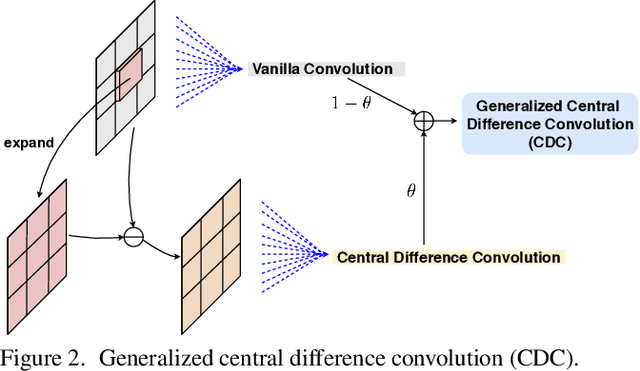
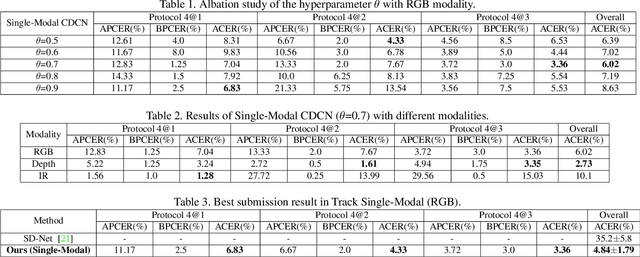
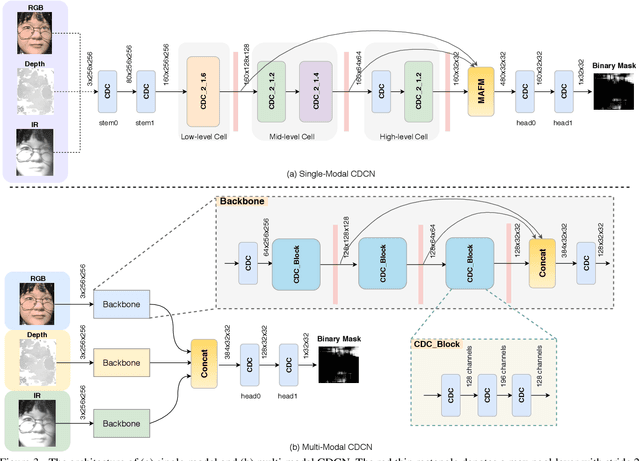
Face anti-spoofing (FAS) plays a vital role in securing face recognition systems from presentation attacks. Existing multi-modal FAS methods rely on stacked vanilla convolutions, which is weak in describing detailed intrinsic information from modalities and easily being ineffective when the domain shifts (e.g., cross attack and cross ethnicity). In this paper, we extend the central difference convolutional networks (CDCN) \cite{yu2020searching} to a multi-modal version, intending to capture intrinsic spoofing patterns among three modalities (RGB, depth and infrared). Meanwhile, we also give an elaborate study about single-modal based CDCN. Our approach won the first place in "Track Multi-Modal" as well as the second place in "Track Single-Modal (RGB)" of ChaLearn Face Anti-spoofing Attack Detection Challenge@CVPR2020 \cite{liu2020cross}. Our final submission obtains 1.02$\pm$0.59\% and 4.84$\pm$1.79\% ACER in "Track Multi-Modal" and "Track Single-Modal (RGB)", respectively. The codes are available at{https://github.com/ZitongYu/CDCN}.
Deep Spatial Gradient and Temporal Depth Learning for Face Anti-spoofing
Mar 18, 2020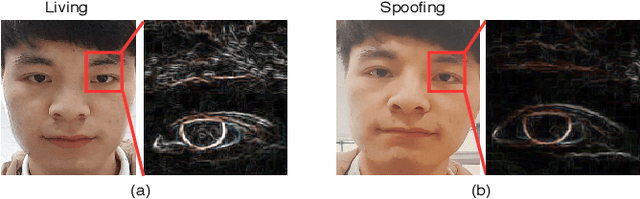
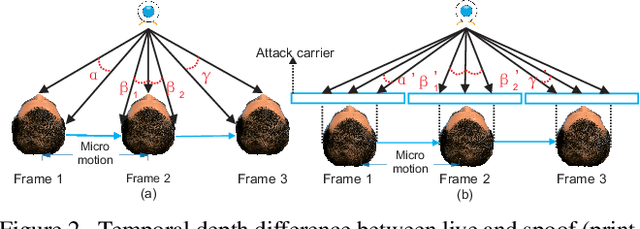

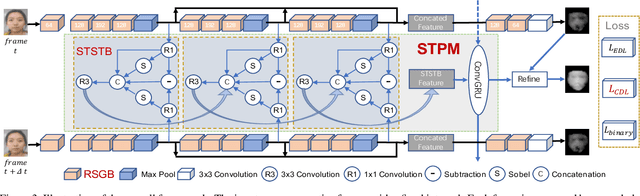
Face anti-spoofing is critical to the security of face recognition systems. Depth supervised learning has been proven as one of the most effective methods for face anti-spoofing. Despite the great success, most previous works still formulate the problem as a single-frame multi-task one by simply augmenting the loss with depth, while neglecting the detailed fine-grained information and the interplay between facial depths and moving patterns. In contrast, we design a new approach to detect presentation attacks from multiple frames based on two insights: 1) detailed discriminative clues (e.g., spatial gradient magnitude) between living and spoofing face may be discarded through stacked vanilla convolutions, and 2) the dynamics of 3D moving faces provide important clues in detecting the spoofing faces. The proposed method is able to capture discriminative details via Residual Spatial Gradient Block (RSGB) and encode spatio-temporal information from Spatio-Temporal Propagation Module (STPM) efficiently. Moreover, a novel Contrastive Depth Loss is presented for more accurate depth supervision. To assess the efficacy of our method, we also collect a Double-modal Anti-spoofing Dataset (DMAD) which provides actual depth for each sample. The experiments demonstrate that the proposed approach achieves state-of-the-art results on five benchmark datasets including OULU-NPU, SiW, CASIA-MFSD, Replay-Attack, and the new DMAD. Codes will be available at https://github.com/clks-wzz/FAS-SGTD.
Searching Central Difference Convolutional Networks for Face Anti-Spoofing
Mar 09, 2020
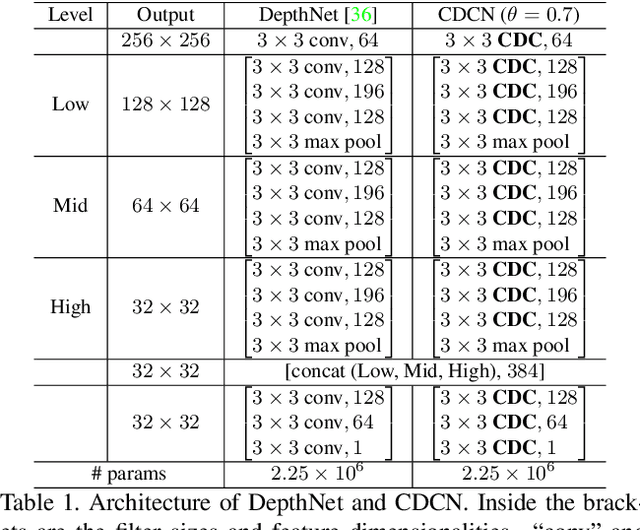
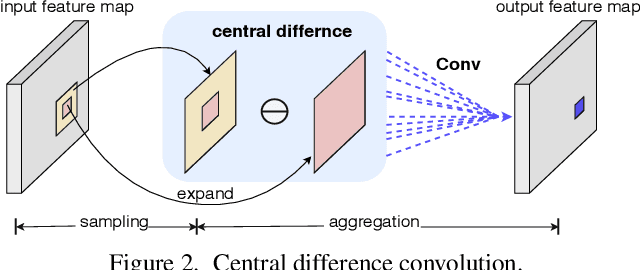

Face anti-spoofing (FAS) plays a vital role in face recognition systems. Most state-of-the-art FAS methods 1) rely on stacked convolutions and expert-designed network, which is weak in describing detailed fine-grained information and easily being ineffective when the environment varies (e.g., different illumination), and 2) prefer to use long sequence as input to extract dynamic features, making them difficult to deploy into scenarios which need quick response. Here we propose a novel frame level FAS method based on Central Difference Convolution (CDC), which is able to capture intrinsic detailed patterns via aggregating both intensity and gradient information. A network built with CDC, called the Central Difference Convolutional Network (CDCN), is able to provide more robust modeling capacity than its counterpart built with vanilla convolution. Furthermore, over a specifically designed CDC search space, Neural Architecture Search (NAS) is utilized to discover a more powerful network structure (CDCN++), which can be assembled with Multiscale Attention Fusion Module (MAFM) for further boosting performance. Comprehensive experiments are performed on six benchmark datasets to show that 1) the proposed method not only achieves superior performance on intra-dataset testing (especially 0.2% ACER in Protocol-1 of OULU-NPU dataset), 2) it also generalizes well on cross-dataset testing (particularly 6.5% HTER from CASIA-MFSD to Replay-Attack datasets). The codes are available at \href{https://github.com/ZitongYu/CDCN}{https://github.com/ZitongYu/CDCN}.
Meta Anti-spoofing: Learning to Learn in Face Anti-spoofing
Apr 29, 2019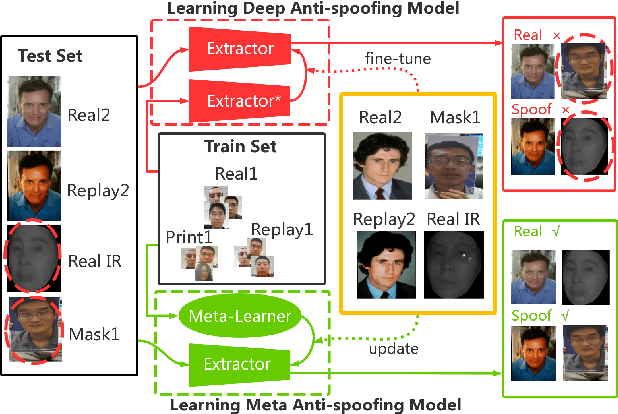
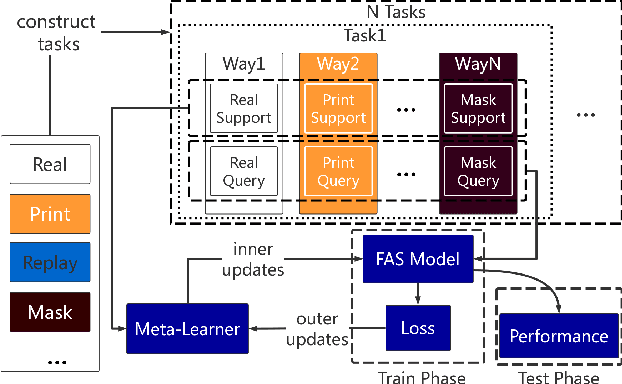
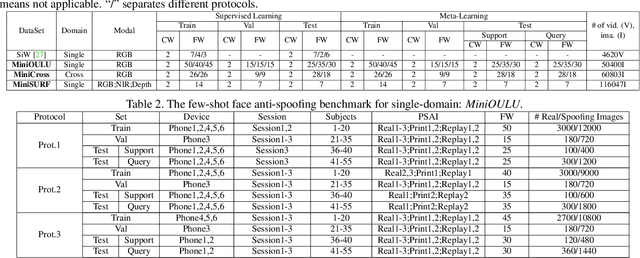
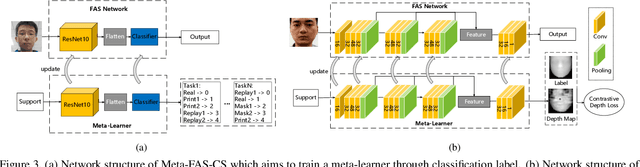
Face anti-spoofing is crucial to the security of face recognition systems. Previously, most methods formulate face anti-spoofing as a supervised learning problem to detect various predefined presentation attacks (PA). However, new attack methods keep evolving that produce new forms of spoofing faces to compromise the existing detectors. This requires researchers to collect a large number of samples to train classifiers for detecting new attacks, which is often costly and leads the later newly evolved attack samples to remain in small scales. Alternatively, we define face anti-spoofing as a few-shot learning problem with evolving new attacks and propose a novel face anti-spoofing approach via meta-learning named Meta Face Anti-spoofing (Meta-FAS). Meta-FAS addresses the above-mentioned problems by training the classifiers how to learn to detect the spoofing faces with few examples. To assess the effectiveness of the proposed approach, we propose a series of evaluation benchmarks based on public datasets (\textit{e.g.}, OULU-NPU, SiW, CASIA-MFSD, Replay-Attack, MSU-MFSD, 3D-MAD, and CASIA-SURF), and the proposed approach shows its superior performances to compared methods.
Rethink and Redesign Meta learning
Dec 24, 2018
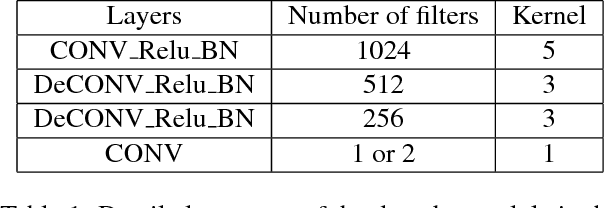
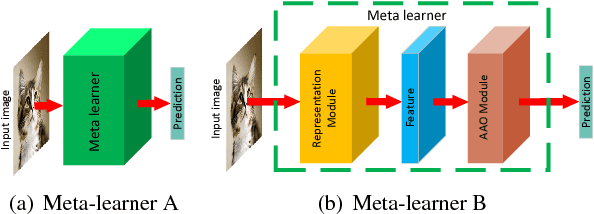
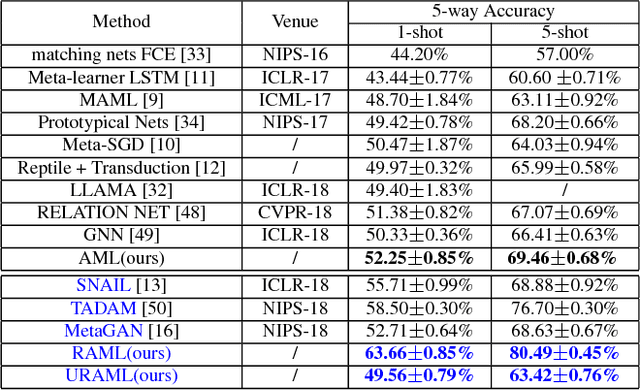
Recently, meta-learning has shown as a promising way to improve the ability to learn from few-data for many computer vision tasks. However, existing meta-learning approaches still fall behind human greatly, and like many deep learning algorithms, they also suffer from overfitting. We named this problem as Task-Over-Fitting (TOF) problem that the meta-learner over-fits to the training tasks, not to the training data. We human beings can learn from few-data, mainly due to that we are so smart to leverage past knowledge to understand the images of new categories rapidly. Furthermore, be benefiting from our flexible attention mechanism, we can accurately extract and select key features from images and further solve few-shot learning tasks with excellent performance. In this paper, we rethink the meta-learning algorithm and find that existing meta-learning approaches miss considering attention mechanism and past knowledge. To this end, we present a novel paradigm of meta-learning approach with three developments to introduce attention mechanism and past knowledge step by step. In this way, we can narrow the problem space and improve the performance of meta-learning, and the TOF problem can also be significantly reduced. Extensive experiments demonstrate the effectiveness of our designation and methods with state-of-the-art performance not only on several few-shot learning benchmarks but also on the Cross-Entropy across Tasks (CET) metric.