 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Camera to World: A Plug-and-Play Module for Human Mesh Transformation
Dec 17, 2025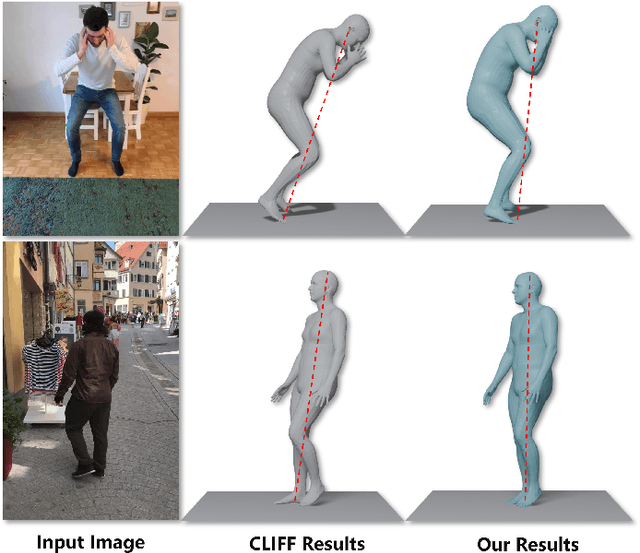
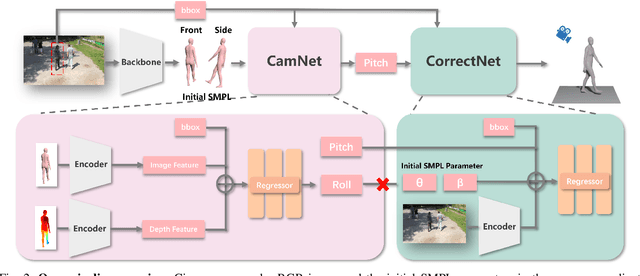
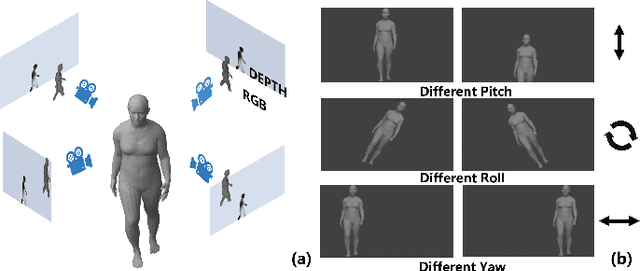

Reconstructing accurate 3D human meshes in the world coordinate system from in-the-wild images remains challenging due to the lack of camera rotation information. While existing methods achieve promising results in the camera coordinate system by assuming zero camera rotation, this simplification leads to significant errors when transforming the reconstructed mesh to the world coordinate system. To address this challenge, we propose Mesh-Plug, a plug-and-play module that accurately transforms human meshes from camera coordinates to world coordinates. Our key innovation lies in a human-centered approach that leverages both RGB images and depth maps rendered from the initial mesh to estimate camera rotation parameters, eliminating the dependency on environmental cues. Specifically, we first train a camera rotation prediction module that focuses on the human body's spatial configuration to estimate camera pitch angle. Then, by integrating the predicted camera parameters with the initial mesh, we design a mesh adjustment module that simultaneously refines the root joint orientation and body pose. Extensive experiments demonstrate that our framework outperforms state-of-the-art methods on the benchmark datasets SPEC-SYN and SPEC-MTP.
Contrastive Learning-based User Identification with Limited Data on Smart Textiles
Sep 06, 2024



Pressure-sensitive smart textiles are widely applied in the fields of healthcare, sports monitoring, and intelligent homes. The integration of devices embedded with pressure sensing arrays is expected to enable comprehensive scene coverage and multi-device integration. However, the implementation of identity recognition, a fundamental function in this context, relies on extensive device-specific datasets due to variations in pressure distribution across different devices. To address this challenge, we propose a novel user identification method based on contrastive learning. We design two parallel branches to facilitate user identification on both new and existing devices respectively, employing supervised contrastive learning in the feature space to promote domain unification. When encountering new devices, extensive data collection efforts are not required; instead, user identification can be achieved using limited data consisting of only a few simple postures. Through experimentation with two 8-subject pressure datasets (BedPressure and ChrPressure), our proposed method demonstrates the capability to achieve user identification across 12 sitting scenarios using only a dataset containing 2 postures. Our average recognition accuracy reaches 79.05%, representing an improvement of 2.62% over the best baseline model.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.