 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVib2ECG: A Paired Chest-Lead SCG-ECG Dataset and Benchmark for ECG Reconstruction
Mar 16, 2026Twelve-lead electrocardiography (ECG) is essential for cardiovascular diagnosis, but its long-term acquisition in daily life is constrained by complex and costly hardware. Recent efforts have explored reconstructing ECG from low-cost cardiac vibrational signals such as seismocardiography (SCG), however, due to the lack of a dataset, current methods are limited to limb leads, while clinical diagnosis requires multi-lead ECG, including chest leads. In this work, we propose Vib2ECG, the first paired, multi-channel electro-mechanical cardiac signal dataset, which includes complete twelve-lead ECGs and vibrational signals acquired by inertial measurement units (IMUs) at six chest-lead positions from 17 subjects. Based on this dataset, we also provide a benchmark. Experimental results demonstrate the feasibility of reconstructing electrical cardiac signals at variable locations from vibrational signals using a lightweight 364 K-parameter U-Net. Furthermore, we observe a hallucination phenomenon in the model, where ECG waveforms are generated in regions where no corresponding electrical activity is present. We analyze the causes of this phenomenon and propose potential directions for mitigation. This study demonstrates the feasibility of mobile-device-friendly ECG monitoring through chest-lead ECG prediction from low-cost vibrational signals acquired using IMU sensors. It expands the application of cardiac vibrational signals and provides new insights into the spatial relationship between cardiac electrical and mechanical activities with spatial location variation.
From Camera to World: A Plug-and-Play Module for Human Mesh Transformation
Dec 17, 2025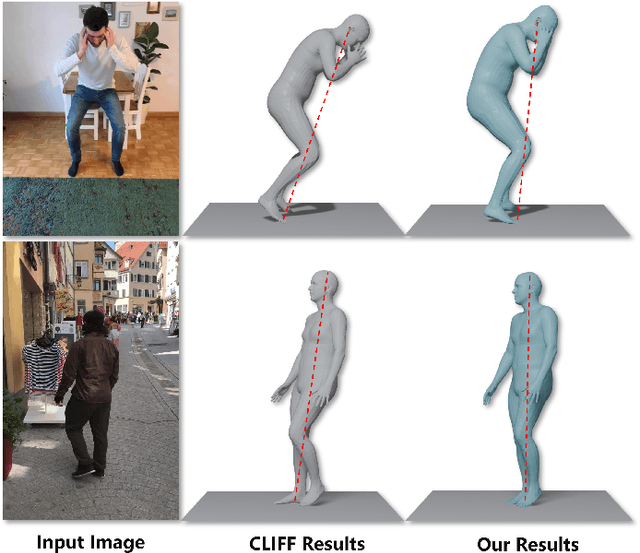
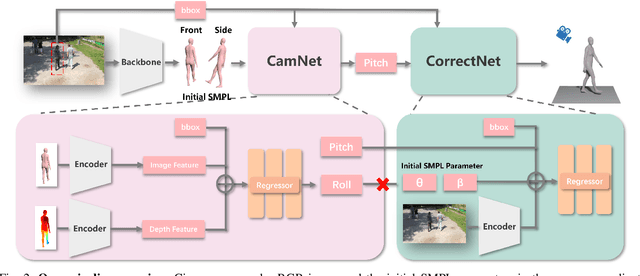
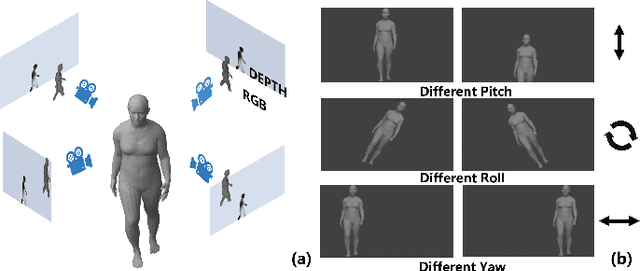

Reconstructing accurate 3D human meshes in the world coordinate system from in-the-wild images remains challenging due to the lack of camera rotation information. While existing methods achieve promising results in the camera coordinate system by assuming zero camera rotation, this simplification leads to significant errors when transforming the reconstructed mesh to the world coordinate system. To address this challenge, we propose Mesh-Plug, a plug-and-play module that accurately transforms human meshes from camera coordinates to world coordinates. Our key innovation lies in a human-centered approach that leverages both RGB images and depth maps rendered from the initial mesh to estimate camera rotation parameters, eliminating the dependency on environmental cues. Specifically, we first train a camera rotation prediction module that focuses on the human body's spatial configuration to estimate camera pitch angle. Then, by integrating the predicted camera parameters with the initial mesh, we design a mesh adjustment module that simultaneously refines the root joint orientation and body pose. Extensive experiments demonstrate that our framework outperforms state-of-the-art methods on the benchmark datasets SPEC-SYN and SPEC-MTP.
PressTrack-HMR: Pressure-Based Top-Down Multi-Person Global Human Mesh Recovery
Nov 13, 2025Multi-person global human mesh recovery (HMR) is crucial for understanding crowd dynamics and interactions. Traditional vision-based HMR methods sometimes face limitations in real-world scenarios due to mutual occlusions, insufficient lighting, and privacy concerns. Human-floor tactile interactions offer an occlusion-free and privacy-friendly alternative for capturing human motion. Existing research indicates that pressure signals acquired from tactile mats can effectively estimate human pose in single-person scenarios. However, when multiple individuals walk randomly on the mat simultaneously, how to distinguish intermingled pressure signals generated by different persons and subsequently acquire individual temporal pressure data remains a pending challenge for extending pressure-based HMR to the multi-person situation. In this paper, we present \textbf{PressTrack-HMR}, a top-down pipeline that recovers multi-person global human meshes solely from pressure signals. This pipeline leverages a tracking-by-detection strategy to first identify and segment each individual's pressure signal from the raw pressure data, and subsequently performs HMR for each extracted individual signal. Furthermore, we build a multi-person interaction pressure dataset \textbf{MIP}, which facilitates further research into pressure-based human motion analysis in multi-person scenarios. Experimental results demonstrate that our method excels in multi-person HMR using pressure data, with 89.2 $mm$ MPJPE and 112.6 $mm$ WA-MPJPE$_{100}$, and these showcase the potential of tactile mats for ubiquitous, privacy-preserving multi-person action recognition. Our dataset & code are available at https://github.com/Jiayue-Yuan/PressTrack-HMR.
Contrastive Learning-based User Identification with Limited Data on Smart Textiles
Sep 06, 2024



Pressure-sensitive smart textiles are widely applied in the fields of healthcare, sports monitoring, and intelligent homes. The integration of devices embedded with pressure sensing arrays is expected to enable comprehensive scene coverage and multi-device integration. However, the implementation of identity recognition, a fundamental function in this context, relies on extensive device-specific datasets due to variations in pressure distribution across different devices. To address this challenge, we propose a novel user identification method based on contrastive learning. We design two parallel branches to facilitate user identification on both new and existing devices respectively, employing supervised contrastive learning in the feature space to promote domain unification. When encountering new devices, extensive data collection efforts are not required; instead, user identification can be achieved using limited data consisting of only a few simple postures. Through experimentation with two 8-subject pressure datasets (BedPressure and ChrPressure), our proposed method demonstrates the capability to achieve user identification across 12 sitting scenarios using only a dataset containing 2 postures. Our average recognition accuracy reaches 79.05%, representing an improvement of 2.62% over the best baseline model.