 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Edge of Orthogonality: A Simple View of What Makes BYOL Tick
Feb 09, 2023Self-predictive unsupervised learning methods such as BYOL or SimSiam have shown impressive results, and counter-intuitively, do not collapse to trivial representations. In this work, we aim at exploring the simplest possible mathematical arguments towards explaining the underlying mechanisms behind self-predictive unsupervised learning. We start with the observation that those methods crucially rely on the presence of a predictor network (and stop-gradient). With simple linear algebra, we show that when using a linear predictor, the optimal predictor is close to an orthogonal projection, and propose a general framework based on orthonormalization that enables to interpret and give intuition on why BYOL works. In addition, this framework demonstrates the crucial role of the exponential moving average and stop-gradient operator in BYOL as an efficient orthonormalization mechanism. We use these insights to propose four new \emph{closed-form predictor} variants of BYOL to support our analysis. Our closed-form predictors outperform standard linear trainable predictor BYOL at $100$ and $300$ epochs (top-$1$ linear accuracy on ImageNet).
An Analysis of Quantile Temporal-Difference Learning
Jan 11, 2023



We analyse quantile temporal-difference learning (QTD), a distributional reinforcement learning algorithm that has proven to be a key component in several successful large-scale applications of reinforcement learning. Despite these empirical successes, a theoretical understanding of QTD has proven elusive until now. Unlike classical TD learning, which can be analysed with standard stochastic approximation tools, QTD updates do not approximate contraction mappings, are highly non-linear, and may have multiple fixed points. The core result of this paper is a proof of convergence to the fixed points of a related family of dynamic programming procedures with probability 1, putting QTD on firm theoretical footing. The proof establishes connections between QTD and non-linear differential inclusions through stochastic approximation theory and non-smooth analysis.
Understanding Self-Predictive Learning for Reinforcement Learning
Dec 06, 2022



We study the learning dynamics of self-predictive learning for reinforcement learning, a family of algorithms that learn representations by minimizing the prediction error of their own future latent representations. Despite its recent empirical success, such algorithms have an apparent defect: trivial representations (such as constants) minimize the prediction error, yet it is obviously undesirable to converge to such solutions. Our central insight is that careful designs of the optimization dynamics are critical to learning meaningful representations. We identify that a faster paced optimization of the predictor and semi-gradient updates on the representation, are crucial to preventing the representation collapse. Then in an idealized setup, we show self-predictive learning dynamics carries out spectral decomposition on the state transition matrix, effectively capturing information of the transition dynamics. Building on the theoretical insights, we propose bidirectional self-predictive learning, a novel self-predictive algorithm that learns two representations simultaneously. We examine the robustness of our theoretical insights with a number of small-scale experiments and showcase the promise of the novel representation learning algorithm with large-scale experiments.
The Nature of Temporal Difference Errors in Multi-step Distributional Reinforcement Learning
Jul 15, 2022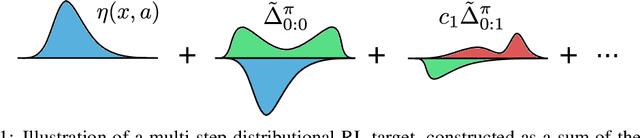
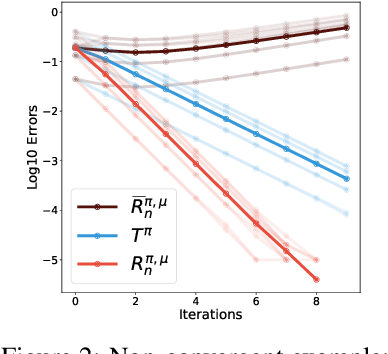
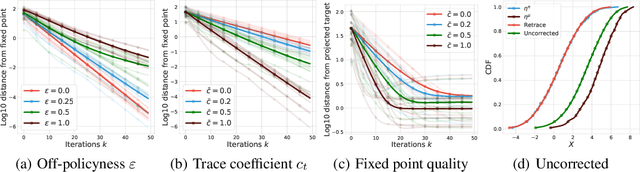
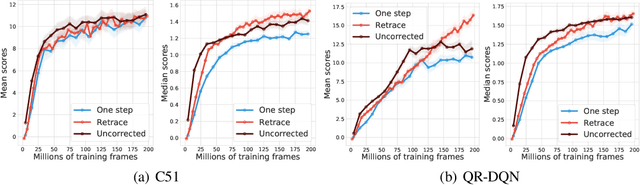
We study the multi-step off-policy learning approach to distributional RL. Despite the apparent similarity between value-based RL and distributional RL, our study reveals intriguing and fundamental differences between the two cases in the multi-step setting. We identify a novel notion of path-dependent distributional TD error, which is indispensable for principled multi-step distributional RL. The distinction from the value-based case bears important implications on concepts such as backward-view algorithms. Our work provides the first theoretical guarantees on multi-step off-policy distributional RL algorithms, including results that apply to the small number of existing approaches to multi-step distributional RL. In addition, we derive a novel algorithm, Quantile Regression-Retrace, which leads to a deep RL agent QR-DQN-Retrace that shows empirical improvements over QR-DQN on the Atari-57 benchmark. Collectively, we shed light on how unique challenges in multi-step distributional RL can be addressed both in theory and practice.
BYOL-Explore: Exploration by Bootstrapped Prediction
Jun 16, 2022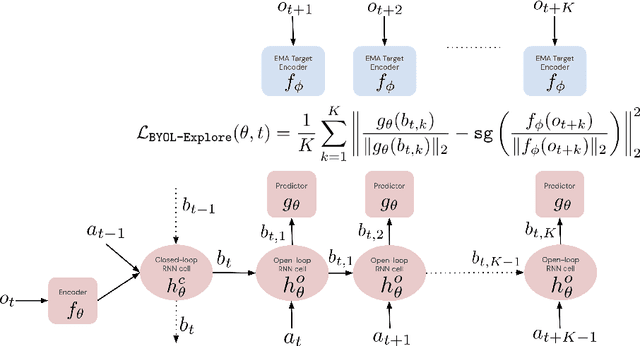
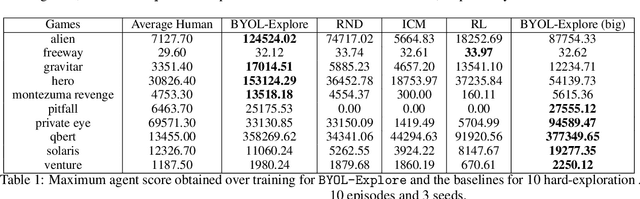

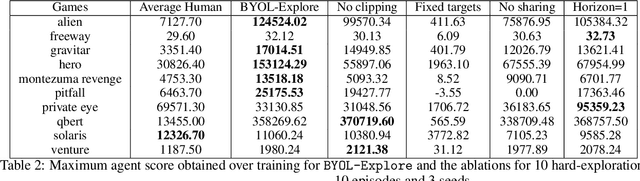
We present BYOL-Explore, a conceptually simple yet general approach for curiosity-driven exploration in visually-complex environments. BYOL-Explore learns a world representation, the world dynamics, and an exploration policy all-together by optimizing a single prediction loss in the latent space with no additional auxiliary objective. We show that BYOL-Explore is effective in DM-HARD-8, a challenging partially-observable continuous-action hard-exploration benchmark with visually-rich 3-D environments. On this benchmark, we solve the majority of the tasks purely through augmenting the extrinsic reward with BYOL-Explore s intrinsic reward, whereas prior work could only get off the ground with human demonstrations. As further evidence of the generality of BYOL-Explore, we show that it achieves superhuman performance on the ten hardest exploration games in Atari while having a much simpler design than other competitive agents.
KL-Entropy-Regularized RL with a Generative Model is Minimax Optimal
May 27, 2022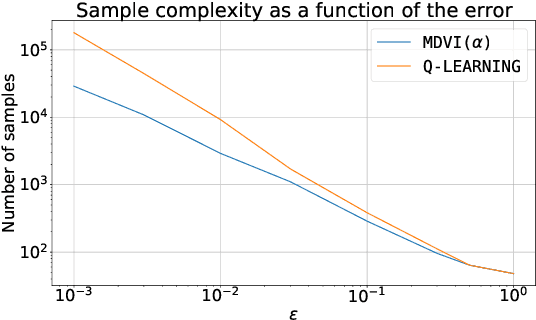

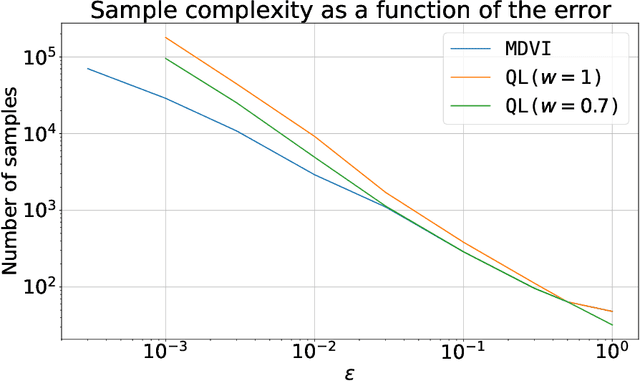
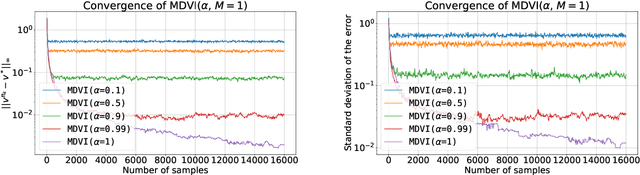
In this work, we consider and analyze the sample complexity of model-free reinforcement learning with a generative model. Particularly, we analyze mirror descent value iteration (MDVI) by Geist et al. (2019) and Vieillard et al. (2020a), which uses the Kullback-Leibler divergence and entropy regularization in its value and policy updates. Our analysis shows that it is nearly minimax-optimal for finding an $\varepsilon$-optimal policy when $\varepsilon$ is sufficiently small. This is the first theoretical result that demonstrates that a simple model-free algorithm without variance-reduction can be nearly minimax-optimal under the considered setting.
From Dirichlet to Rubin: Optimistic Exploration in RL without Bonuses
May 16, 2022
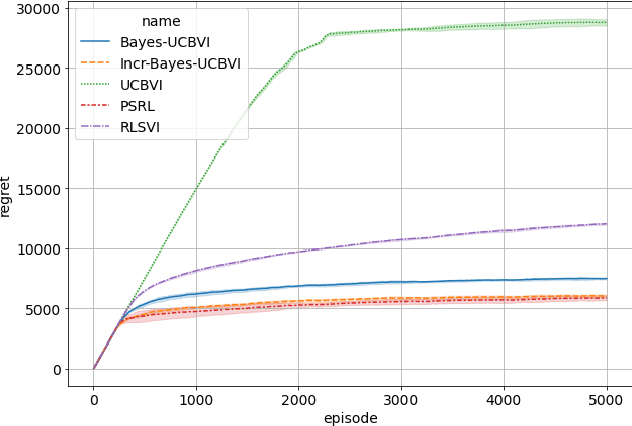
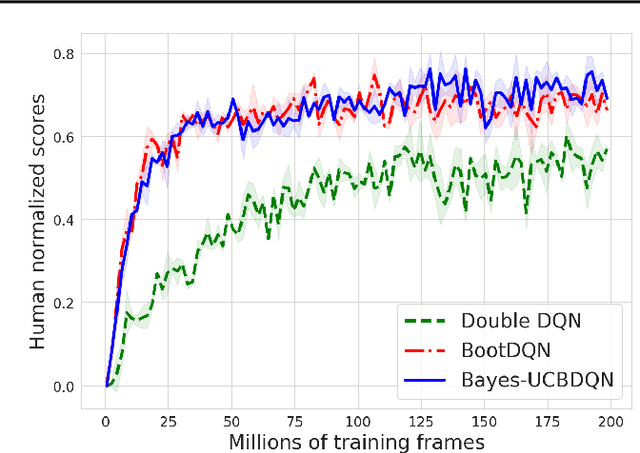
We propose the Bayes-UCBVI algorithm for reinforcement learning in tabular, stage-dependent, episodic Markov decision process: a natural extension of the Bayes-UCB algorithm by Kaufmann et al. (2012) for multi-armed bandits. Our method uses the quantile of a Q-value function posterior as upper confidence bound on the optimal Q-value function. For Bayes-UCBVI, we prove a regret bound of order $\widetilde{O}(\sqrt{H^3SAT})$ where $H$ is the length of one episode, $S$ is the number of states, $A$ the number of actions, $T$ the number of episodes, that matches the lower-bound of $\Omega(\sqrt{H^3SAT})$ up to poly-$\log$ terms in $H,S,A,T$ for a large enough $T$. To the best of our knowledge, this is the first algorithm that obtains an optimal dependence on the horizon $H$ (and $S$) without the need for an involved Bernstein-like bonus or noise. Crucial to our analysis is a new fine-grained anti-concentration bound for a weighted Dirichlet sum that can be of independent interest. We then explain how Bayes-UCBVI can be easily extended beyond the tabular setting, exhibiting a strong link between our algorithm and Bayesian bootstrap (Rubin, 1981).
Marginalized Operators for Off-policy Reinforcement Learning
Mar 30, 2022
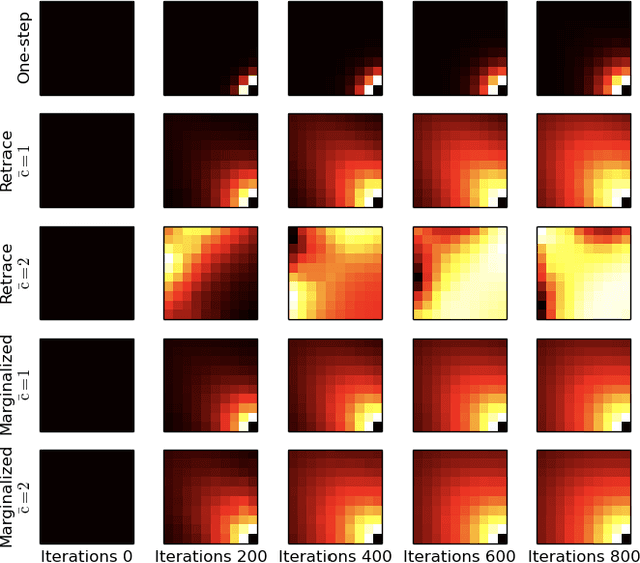
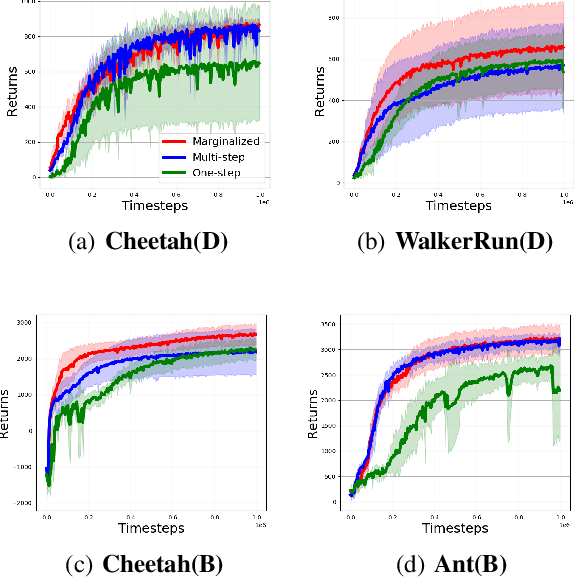
In this work, we propose marginalized operators, a new class of off-policy evaluation operators for reinforcement learning. Marginalized operators strictly generalize generic multi-step operators, such as Retrace, as special cases. Marginalized operators also suggest a form of sample-based estimates with potential variance reduction, compared to sample-based estimates of the original multi-step operators. We show that the estimates for marginalized operators can be computed in a scalable way, which also generalizes prior results on marginalized importance sampling as special cases. Finally, we empirically demonstrate that marginalized operators provide performance gains to off-policy evaluation and downstream policy optimization algorithms.
Biased Gradient Estimate with Drastic Variance Reduction for Meta Reinforcement Learning
Dec 14, 2021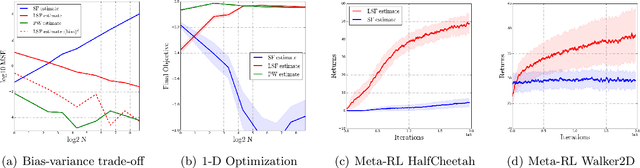
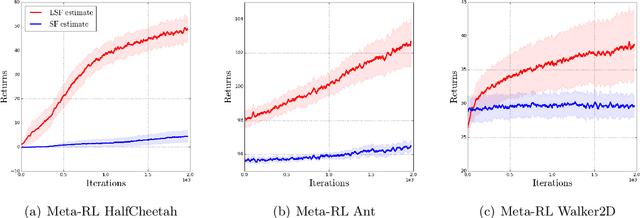
Despite the empirical success of meta reinforcement learning (meta-RL), there are still a number poorly-understood discrepancies between theory and practice. Critically, biased gradient estimates are almost always implemented in practice, whereas prior theory on meta-RL only establishes convergence under unbiased gradient estimates. In this work, we investigate such a discrepancy. In particular, (1) We show that unbiased gradient estimates have variance $\Theta(N)$ which linearly depends on the sample size $N$ of the inner loop updates; (2) We propose linearized score function (LSF) gradient estimates, which have bias $\mathcal{O}(1/\sqrt{N})$ and variance $\mathcal{O}(1/N)$; (3) We show that most empirical prior work in fact implements variants of the LSF gradient estimates. This implies that practical algorithms "accidentally" introduce bias to achieve better performance; (4) We establish theoretical guarantees for the LSF gradient estimates in meta-RL regarding its convergence to stationary points, showing better dependency on $N$ than prior work when $N$ is large.
Unifying Gradient Estimators for Meta-Reinforcement Learning via Off-Policy Evaluation
Jun 24, 2021
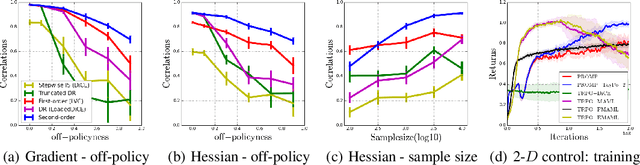
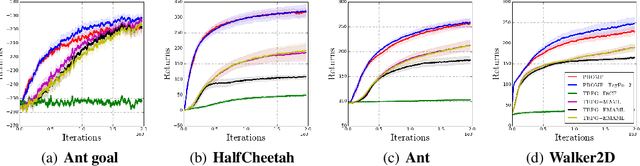

Model-agnostic meta-reinforcement learning requires estimating the Hessian matrix of value functions. This is challenging from an implementation perspective, as repeatedly differentiating policy gradient estimates may lead to biased Hessian estimates. In this work, we provide a unifying framework for estimating higher-order derivatives of value functions, based on off-policy evaluation. Our framework interprets a number of prior approaches as special cases and elucidates the bias and variance trade-off of Hessian estimates. This framework also opens the door to a new family of estimates, which can be easily implemented with auto-differentiation libraries, and lead to performance gains in practice.