 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaSST: Fast Sparsifying Secondary Transform
May 14, 2026Data-dependent secondary transforms, which aim to decorrelate coefficients of a separable primary transform, can improve residual coding efficiency; however, their deployment is often constrained by computational complexity. Recent video codecs use variants of the low-frequency non-separable transform (LFNST), which discards some high-frequency secondary transform coefficients, limiting achievable coding gains. Moreover, existing data-dependent secondary transforms lack explicit rate-distortion (RD) optimal design criteria. In this work, we propose a framework for designing low-complexity data-dependent secondary transforms, termed Fast Sparsifying Secondary Transforms (FaSSTs). Our approach approximates data-driven sparse orthonormal transforms (SOTs) by factorizing them into a sequence of Givens rotations. The rotations are efficiently determined using an alternating minimization strategy combined with an approximate Givens factorization procedure. Our method adapts the number of rotations based on the prediction mode, further reducing computational complexity. We design mode-dependent secondary transforms for intra-prediction residuals in AV2 using FaSST. Experimental results show that mode-adaptive FaSST matches the RD performance of LFNST while reducing the number of computations by 83.67%. Moreover, by avoiding fixed-coefficient truncation, FaSST achieves up to 1.80% BD-rate savings relative to LFNST while operating at 66.24% lower complexity.
Transform and Entropy Coding in AV2
Jan 06, 2026AV2 is the successor to the AV1 royalty-free video coding standard developed by the Alliance for Open Media (AOMedia). Its primary objective is to deliver substantial compression gains and subjective quality improvements while maintaining low-complexity encoder and decoder operations. This paper describes the transform, quantization and entropy coding design in AV2, including redesigned transform kernels and data-driven transforms, expanded transform partitioning, and a mode & coefficient dependent transform signaling. AV2 introduces several new coding tools including Intra/Inter Secondary Transforms (IST), Trellis Coded Quantization (TCQ), Adaptive Transform Coding (ATC), Probability Adaptation Rate Adjustment (PARA), Forward Skip Coding (FSC), Cross Chroma Component Transforms (CCTX), Parity Hiding (PH) tools and improved lossless coding. These advances enable AV2 to deliver the highest quality video experience for video applications at a significantly reduced bitrate.
Joint Optimization of Primary and Secondary Transforms Using Rate-Distortion Optimized Transform Design
May 21, 2025



Data-dependent transforms are increasingly being incorporated into next-generation video coding systems such as AVM, a codec under development by the Alliance for Open Media (AOM), and VVC. To circumvent the computational complexities associated with implementing non-separable data-dependent transforms, combinations of separable primary transforms and non-separable secondary transforms have been studied and integrated into video coding standards. These codecs often utilize rate-distortion optimized transforms (RDOT) to ensure that the new transforms complement existing transforms like the DCT and the ADST. In this work, we propose an optimization framework for jointly designing primary and secondary transforms from data through a rate-distortion optimized clustering. Primary transforms are assumed to follow a path-graph model, while secondary transforms are non-separable. We empirically evaluate our proposed approach using AVM residual data and demonstrate that 1) the joint clustering method achieves lower total RD cost in the RDOT design framework, and 2) jointly optimized separable path-graph transforms (SPGT) provide better coding efficiency compared to separable KLTs obtained from the same data.
Standard compliant video coding using low complexity, switchable neural wrappers
Jul 10, 2024The proliferation of high resolution videos posts great storage and bandwidth pressure on cloud video services, driving the development of next-generation video codecs. Despite great progress made in neural video coding, existing approaches are still far from economical deployment considering the complexity and rate-distortion performance tradeoff. To clear the roadblocks for neural video coding, in this paper we propose a new framework featuring standard compatibility, high performance, and low decoding complexity. We employ a set of jointly optimized neural pre- and post-processors, wrapping a standard video codec, to encode videos at different resolutions. The rate-distorion optimal downsampling ratio is signaled to the decoder at the per-sequence level for each target rate. We design a low complexity neural post-processor architecture that can handle different upsampling ratios. The change of resolution exploits the spatial redundancy in high-resolution videos, while the neural wrapper further achieves rate-distortion performance improvement through end-to-end optimization with a codec proxy. Our light-weight post-processor architecture has a complexity of 516 MACs / pixel, and achieves 9.3% BD-Rate reduction over VVC on the UVG dataset, and 6.4% on AOM CTC Class A1. Our approach has the potential to further advance the performance of the latest video coding standards using neural processing with minimal added complexity.
DCT and DST Filtering with Sparse Graph Operators
Mar 22, 2021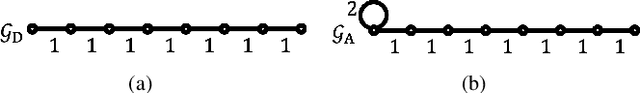
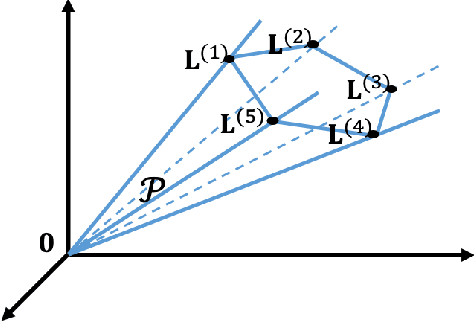
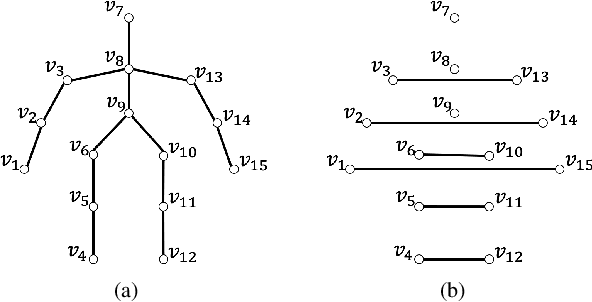
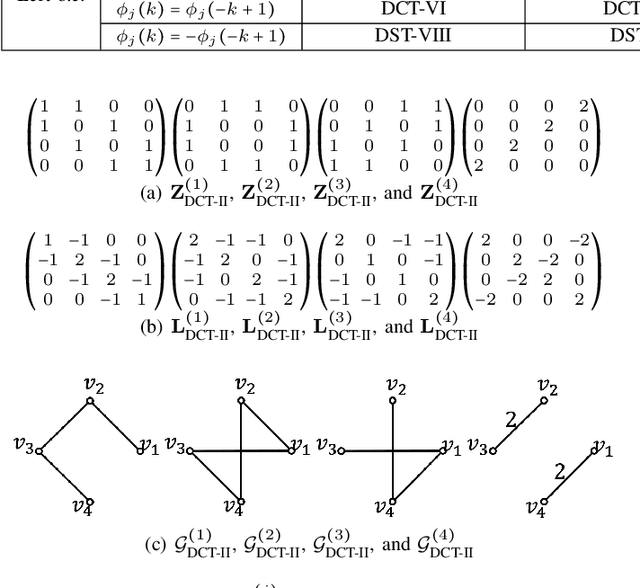
Graph filtering is a fundamental tool in graph signal processing. Polynomial graph filters (PGFs), defined as polynomials of a fundamental graph operator, can be implemented in the vertex domain, and usually have a lower complexity than frequency domain filter implementations. In this paper, we focus on the design of filters for graphs with graph Fourier transform (GFT) corresponding to a discrete trigonometric transform (DTT), i.e., one of 8 types of discrete cosine transforms (DCT) and 8 discrete sine transforms (DST). In this case, we show that multiple sparse graph operators can be identified, which allows us to propose a generalization of PGF design: multivariate polynomial graph filter (MPGF). First, for the widely used DCT-II (type-2 DCT), we characterize a set of sparse graph operators that share the DCT-II matrix as their common eigenvector matrix. This set contains the well-known connected line graph. These sparse operators can be viewed as graph filters operating in the DCT domain, which allows us to approximate any DCT graph filter by a MPGF, leading to a design with more degrees of freedom than the conventional PGF approach. Then, we extend those results to all of the 16 DTTs as well as their 2D versions, and show how their associated sets of multiple graph operators can be determined. We demonstrate experimentally that ideal low-pass and exponential DCT/DST filters can be approximated with higher accuracy with similar runtime complexity. Finally, we apply our method to transform-type selection in a video codec, AV1, where we demonstrate significant encoding time savings, with a negligible compression loss.