 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSAD: Uncertainty-aware Statistical Adversarial Detection
Jun 26, 2026Statistical adversarial detection (SAD) treats detection as a two-sample test. Given a reference set of clean examples (CEs) and a batch of queries, potentially containing an unknown mixture of CEs and adversarial examples (AEs), SAD decides whether the query distribution drifts away from the CE distribution while controlling the false-alarm rate. Existing SAD-based methods mainly use maximum mean discrepancy (MMD) to measure the distributional discrepancy. However, MMD's distributional properties limit its ability to capture characteristic uncertainty patterns of AEs that are crucial for detection: AEs typically exhibit abnormal feature spread (i.e., global uncertainty) and instability under perturbations (i.e., local uncertainty). To close the gap, we propose Uncertainty-aware Statistical Adversarial Detection (USAD), which explicitly captures these uncertainty patterns with two new statistics: (1) Variance Discrepancy (VD), which measures the difference in feature spread between AEs and CEs to capture global uncertainty differences. (2) Perturbation-based Covariance Discrepancy (PCD), which compares feature covariance under Gaussian perturbations to capture local uncertainty differences. By aggregating VD and PCD, USAD achieves superior detection performances over baseline methods against various adversarial attacks, highlighting the importance of considering characteristic behaviors of AEs for effective SAD. Our code is available at: https://anonymous.4open.science/r/USAD.
FedReLa: Imbalanced Federated Learning via Re-Labeling
Jun 24, 2026Federated learning has emerged as the foremost approach for decentralized model training with privacy preservation. The global class imbalance and cross-client data heterogeneity naturally coexist, and the mismatch between local and global imbalances exacerbates the performance degradation of the aggregated model. The agnosticism of global class distribution poses significant challenges for data-level methods, especially under extreme conditions with severe class absence across clients. In this paper, we propose FedReLa, a novel data-level approach that tackles the coexistence of data heterogeneity and class imbalance in federated learning. By re-labeling samples with a feature-dependent label re-allocator, FedReLa corrects biased global decision boundaries without requiring knowledge of the global class distribution. This modular, model-agnostic approach can be integrated with algorithmic methods to deliver consistent improvements without additional communication overhead. Through extensive experiments, our method significantly improves the accuracy of minority classes and the overall accuracy on stepwise-imbalanced and long-tailed datasets, outperforming the previous state of the art.
LOTTERY: Learning from Reference-Only Samples in Two-Sample Testing under Size Asymmetry
Jun 07, 2026Data-adaptive two-sample testing assesses if two samples come from the same distribution, using a discrepancy learned from the data (e.g., via kernel-based feature representations). Such methods typically rely on data splitting to decouple learning from testing and control type I error. However, this paradigm is ill-suited to few-shot settings with severe sample-size imbalance: abundant reference samples are available, while only a handful of query samples arrive. In this paper, we show how this imbalance can be leveraged constructively. Using abundant reference data, we learn reference-dependent representations that summarize salient structure of the reference distribution and provide informative signals for detecting departures. We incorporate a collection of representation families that capture both global and local structure, and adaptively weight them using only reference samples via an uncertainty-guided principle. Theoretically, we establish permutation-based type I error control and show consistency of the aggregated test: as the sample sizes grow, the test power converges to one whenever the representation set contains at least one consistent representation. Empirically, our aggregation achieves strong performance across a range of benchmarks while retaining type I error control.
* 16 pages, 1 figure
Learning U-Statistics with Active Inference
May 12, 2026$U$-statistics play a central role in statistical inference. In many modern applications, however, acquiring the labels required for $U$-statistics is costly. Motivated by recent advances in active inference, we develop an active inference framework for $U$-statistics that selectively queries informative labels to improve estimation efficiency under a fixed labeling budget, while preserving valid statistical inference. Our approach is built on the augmented inverse probability weighting $U$-statistic, which is designed to incorporate the sampling rule and machine learning predictions. We characterize the optimal sampling rule that minimizes its variance and design practical sampling strategies. We further extend the framework to $U$-statistic-based empirical risk minimization. Experiments on real datasets demonstrate substantial gains in estimation efficiency over baseline methods, while maintaining target coverage.
Adapformer: Adaptive Channel Management for Multivariate Time Series Forecasting
Nov 18, 2025



In multivariate time series forecasting (MTSF), accurately modeling the intricate dependencies among multiple variables remains a significant challenge due to the inherent limitations of traditional approaches. Most existing models adopt either \textbf{channel-independent} (CI) or \textbf{channel-dependent} (CD) strategies, each presenting distinct drawbacks. CI methods fail to leverage the potential insights from inter-channel interactions, resulting in models that may not fully exploit the underlying statistical dependencies present in the data. Conversely, CD approaches often incorporate too much extraneous information, risking model overfitting and predictive inefficiency. To address these issues, we introduce the Adaptive Forecasting Transformer (\textbf{Adapformer}), an advanced Transformer-based framework that merges the benefits of CI and CD methodologies through effective channel management. The core of Adapformer lies in its dual-stage encoder-decoder architecture, which includes the \textbf{A}daptive \textbf{C}hannel \textbf{E}nhancer (\textbf{ACE}) for enriching embedding processes and the \textbf{A}daptive \textbf{C}hannel \textbf{F}orecaster (\textbf{ACF}) for refining the predictions. ACE enhances token representations by selectively incorporating essential dependencies, while ACF streamlines the decoding process by focusing on the most relevant covariates, substantially reducing noise and redundancy. Our rigorous testing on diverse datasets shows that Adapformer achieves superior performance over existing models, enhancing both predictive accuracy and computational efficiency, thus making it state-of-the-art in MTSF.
Revisit Non-parametric Two-sample Testing as a Semi-supervised Learning Problem
Nov 30, 2024



Learning effective data representations is crucial in answering if two samples X and Y are from the same distribution (a.k.a. the non-parametric two-sample testing problem), which can be categorized into: i) learning discriminative representations (DRs) that distinguish between two samples in a supervised-learning paradigm, and ii) learning inherent representations (IRs) focusing on data's inherent features in an unsupervised-learning paradigm. However, both paradigms have issues: learning DRs reduces the data points available for the two-sample testing phase, and learning purely IRs misses discriminative cues. To mitigate both issues, we propose a novel perspective to consider non-parametric two-sample testing as a semi-supervised learning (SSL) problem, introducing the SSL-based Classifier Two-Sample Test (SSL-C2ST) framework. While a straightforward implementation of SSL-C2ST might directly use existing state-of-the-art (SOTA) SSL methods to train a classifier with labeled data (with sample indexes X or Y) and unlabeled data (the remaining ones in the two samples), conventional two-sample testing data often exhibits substantial overlap between samples and violates SSL methods' assumptions, resulting in low test power. Therefore, we propose a two-step approach: first, learn IRs using all data, then fine-tune IRs with only labelled data to learn DRs, which can both utilize information from whole dataset and adapt the discriminative power to the given data. Extensive experiments and theoretical analysis demonstrate that SSL-C2ST outperforms traditional C2ST by effectively leveraging unlabeled data. We also offer a stronger empirically designed test achieving the SOTA performance in many two-sample testing datasets.
Nonparametric Feature Selection by Random Forests and Deep Neural Networks
Jan 18, 2022
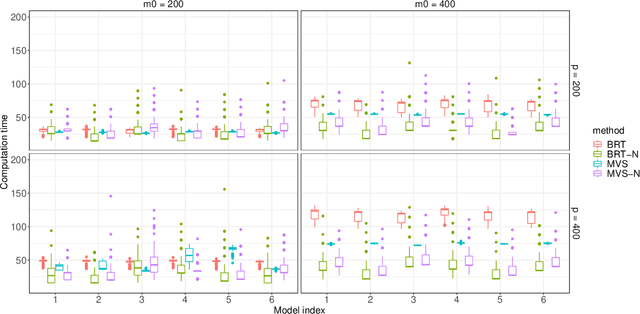
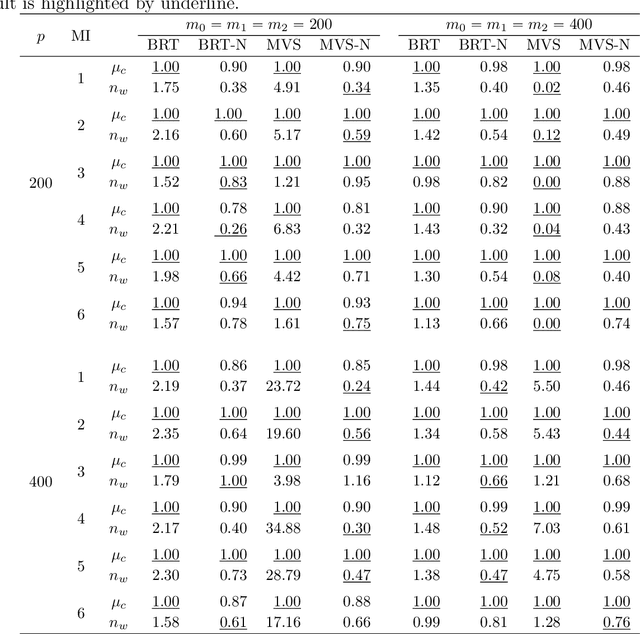

Random forests are a widely used machine learning algorithm, but their computational efficiency is undermined when applied to large-scale datasets with numerous instances and useless features. Herein, we propose a nonparametric feature selection algorithm that incorporates random forests and deep neural networks, and its theoretical properties are also investigated under regularity conditions. Using different synthetic models and a real-world example, we demonstrate the advantage of the proposed algorithm over other alternatives in terms of identifying useful features, avoiding useless ones, and the computation efficiency. Although the algorithm is proposed using standard random forests, it can be widely adapted to other machine learning algorithms, as long as features can be sorted accordingly.