 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Controllable Object through Video Prediction Improves Visual Reinforcement Learning
Feb 21, 2020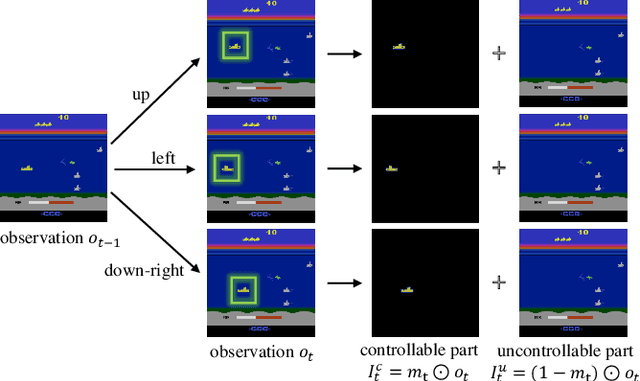
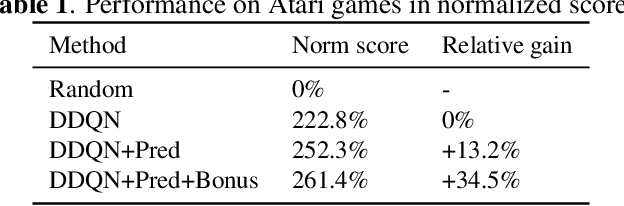
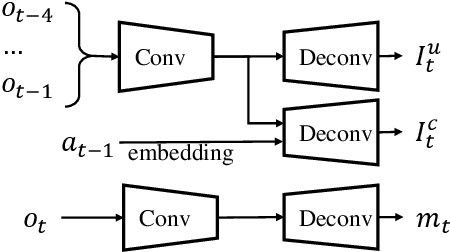
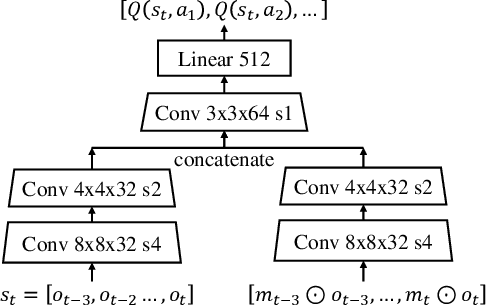
In many vision-based reinforcement learning (RL) problems, the agent controls a movable object in its visual field, e.g., the player's avatar in video games and the robotic arm in visual grasping and manipulation. Leveraging action-conditioned video prediction, we propose an end-to-end learning framework to disentangle the controllable object from the observation signal. The disentangled representation is shown to be useful for RL as additional observation channels to the agent. Experiments on a set of Atari games with the popular Double DQN algorithm demonstrate improved sample efficiency and game performance (from 222.8% to 261.4% measured in normalized game scores, with prediction bonus reward).
Sequence Modeling of Temporal Credit Assignment for Episodic Reinforcement Learning
May 31, 2019

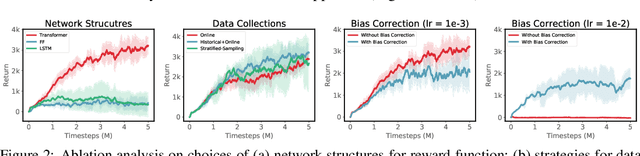
Recent advances in deep reinforcement learning algorithms have shown great potential and success for solving many challenging real-world problems, including Go game and robotic applications. Usually, these algorithms need a carefully designed reward function to guide training in each time step. However, in real world, it is non-trivial to design such a reward function, and the only signal available is usually obtained at the end of a trajectory, also known as the episodic reward or return. In this work, we introduce a new algorithm for temporal credit assignment, which learns to decompose the episodic return back to each time-step in the trajectory using deep neural networks. With this learned reward signal, the learning efficiency can be substantially improved for episodic reinforcement learning. In particular, we find that expressive language models such as the Transformer can be adopted for learning the importance and the dependency of states in the trajectory, therefore providing high-quality and interpretable learned reward signals. We have performed extensive experiments on a set of MuJoCo continuous locomotive control tasks with only episodic returns and demonstrated the effectiveness of our algorithm.
Anchor Box Optimization for Object Detection
Dec 02, 2018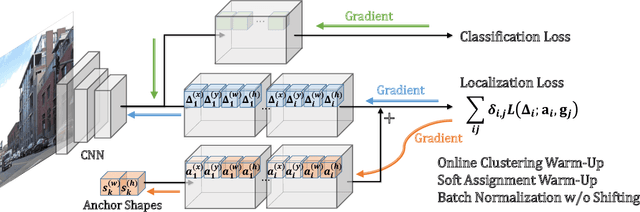
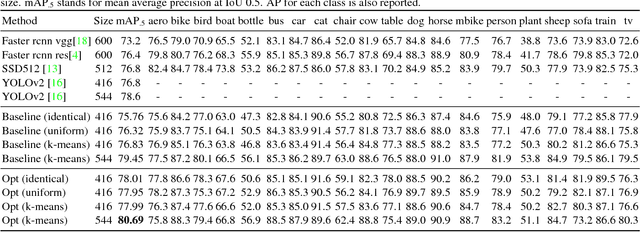
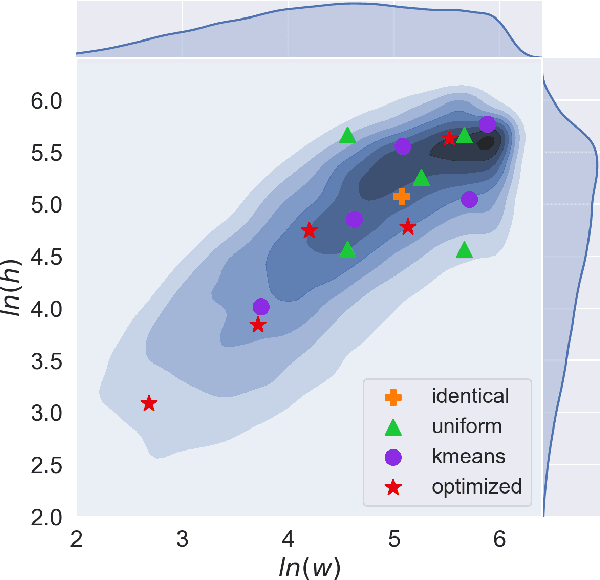
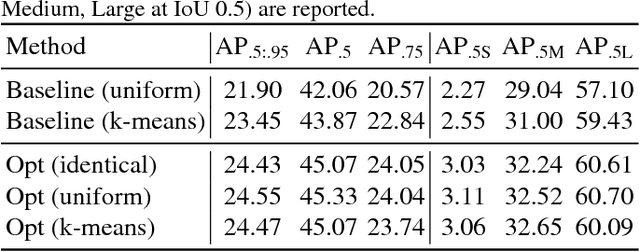
In this paper, we propose a general approach to optimize anchor boxes for object detection. Nowadays, anchor boxes are widely adopted in state-of-the-art detection frameworks. However, all these frameworks pre-define anchor box shapes in a heuristic way and fix the size during training. To improve the accuracy and reduce the effort to design the anchor boxes, we propose to dynamically learn the shapes, which allows the anchors to automatically adapt to the data distribution and the network learning capability. The learning approach can be easily implemented in the stochastic gradient descent way and be plugged into any anchor box-based detection framework. The extra training cost is almost negligible and it has no impact on the inference time cost. Exhaustive experiments also demonstrate that the proposed anchor optimization method consistently achieves significant improvement ($\ge 1\%$ mAP absolute gain) over the baseline method on several benchmark datasets including Pascal VOC 07+12, MS COCO and Brainwash. Meanwhile, the robustness is also verified towards different anchor box initialization methods, which greatly simplifies the problem of anchor box design.
Rethinking Feature Distribution for Loss Functions in Image Classification
Mar 08, 2018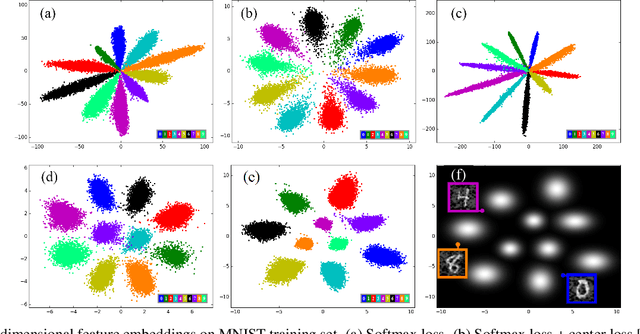
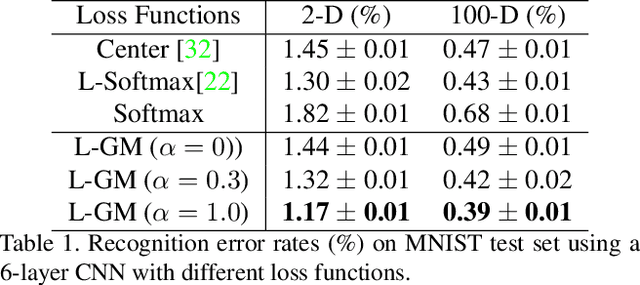
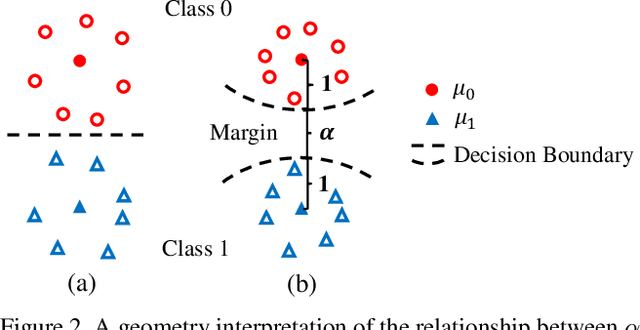
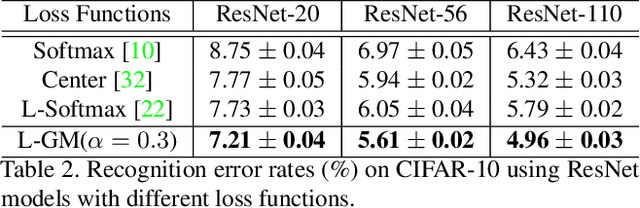
We propose a large-margin Gaussian Mixture (L-GM) loss for deep neural networks in classification tasks. Different from the softmax cross-entropy loss, our proposal is established on the assumption that the deep features of the training set follow a Gaussian Mixture distribution. By involving a classification margin and a likelihood regularization, the L-GM loss facilitates both a high classification performance and an accurate modeling of the training feature distribution. As such, the L-GM loss is superior to the softmax loss and its major variants in the sense that besides classification, it can be readily used to distinguish abnormal inputs, such as the adversarial examples, based on their features' likelihood to the training feature distribution. Extensive experiments on various recognition benchmarks like MNIST, CIFAR, ImageNet and LFW, as well as on adversarial examples demonstrate the effectiveness of our proposal.
Towards End-to-End Face Recognition through Alignment Learning
Jan 25, 2017
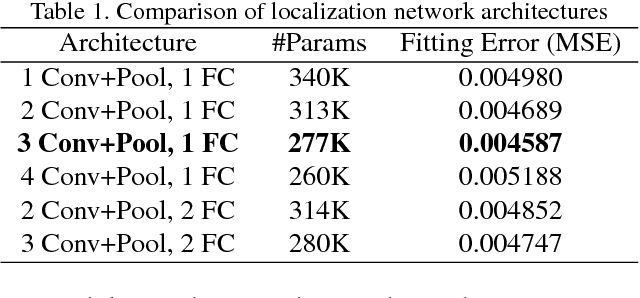
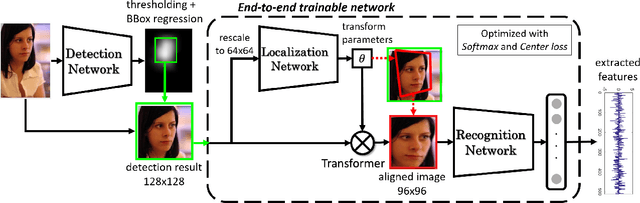
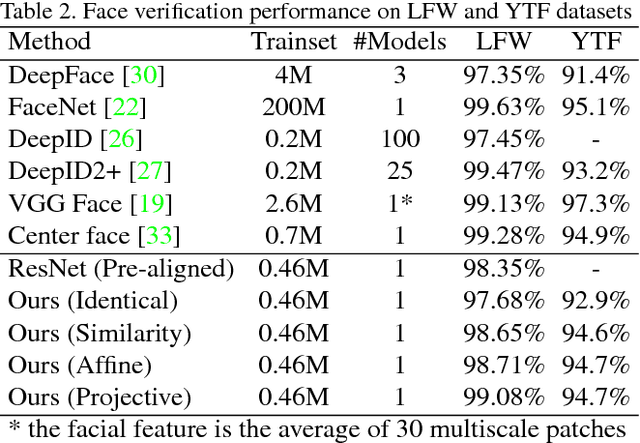
Plenty of effective methods have been proposed for face recognition during the past decade. Although these methods differ essentially in many aspects, a common practice of them is to specifically align the facial area based on the prior knowledge of human face structure before feature extraction. In most systems, the face alignment module is implemented independently. This has actually caused difficulties in the designing and training of end-to-end face recognition models. In this paper we study the possibility of alignment learning in end-to-end face recognition, in which neither prior knowledge on facial landmarks nor artificially defined geometric transformations are required. Specifically, spatial transformer layers are inserted in front of the feature extraction layers in a Convolutional Neural Network (CNN) for face recognition. Only human identity clues are used for driving the neural network to automatically learn the most suitable geometric transformation and the most appropriate facial area for the recognition task. To ensure reproducibility, our model is trained purely on the publicly available CASIA-WebFace dataset, and is tested on the Labeled Face in the Wild (LFW) dataset. We have achieved a verification accuracy of 99.08\% which is comparable to state-of-the-art single model based methods.