 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Optimization by Learning Space Partitions
Oct 10, 2021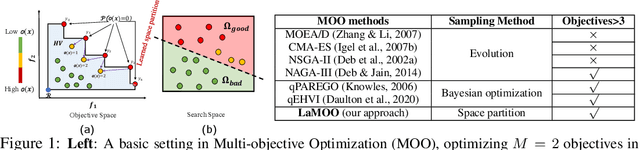
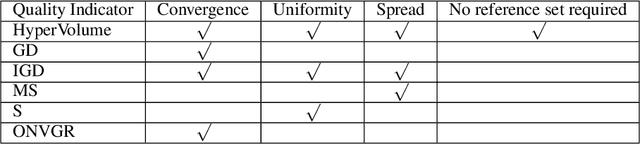
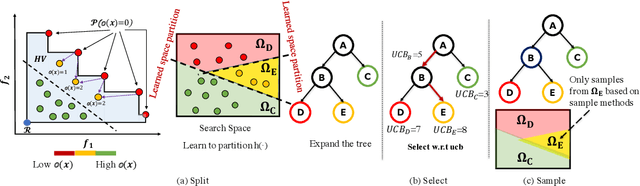
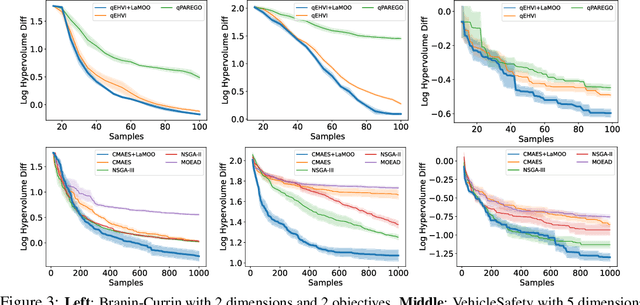
In contrast to single-objective optimization (SOO), multi-objective optimization (MOO) requires an optimizer to find the Pareto frontier, a subset of feasible solutions that are not dominated by other feasible solutions. In this paper, we propose LaMOO, a novel multi-objective optimizer that learns a model from observed samples to partition the search space and then focus on promising regions that are likely to contain a subset of the Pareto frontier. The partitioning is based on the dominance number, which measures "how close" a data point is to the Pareto frontier among existing samples. To account for possible partition errors due to limited samples and model mismatch, we leverage Monte Carlo Tree Search (MCTS) to exploit promising regions while exploring suboptimal regions that may turn out to contain good solutions later. Theoretically, we prove the efficacy of learning space partitioning via LaMOO under certain assumptions. Empirically, on the HyperVolume (HV) benchmark, a popular MOO metric, LaMOO substantially outperforms strong baselines on multiple real-world MOO tasks, by up to 225% in sample efficiency for neural architecture search on Nasbench201, and up to 10% for molecular design.
CompilerGym: Robust, Performant Compiler Optimization Environments for AI Research
Sep 17, 2021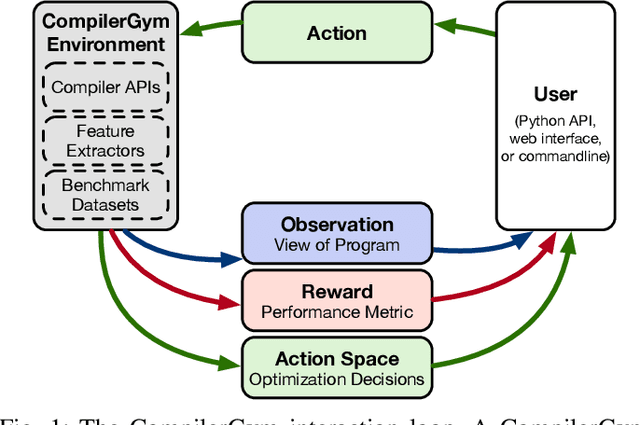
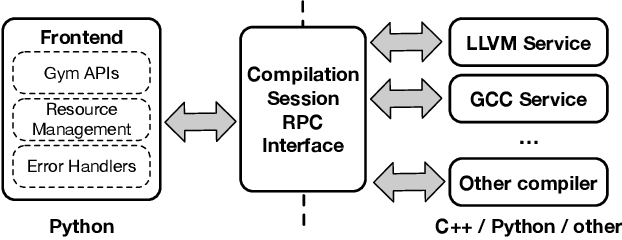
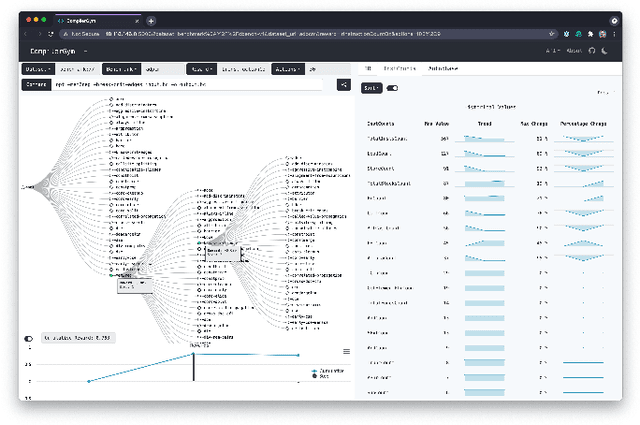
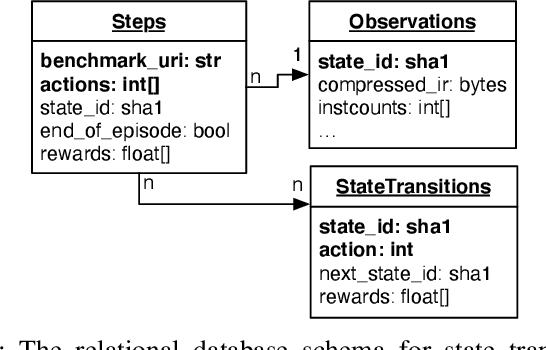
Interest in applying Artificial Intelligence (AI) techniques to compiler optimizations is increasing rapidly, but compiler research has a high entry barrier. Unlike in other domains, compiler and AI researchers do not have access to the datasets and frameworks that enable fast iteration and development of ideas, and getting started requires a significant engineering investment. What is needed is an easy, reusable experimental infrastructure for real world compiler optimization tasks that can serve as a common benchmark for comparing techniques, and as a platform to accelerate progress in the field. We introduce CompilerGym, a set of environments for real world compiler optimization tasks, and a toolkit for exposing new optimization tasks to compiler researchers. CompilerGym enables anyone to experiment on production compiler optimization problems through an easy-to-use package, regardless of their experience with compilers. We build upon the popular OpenAI Gym interface enabling researchers to interact with compilers using Python and a familiar API. We describe the CompilerGym architecture and implementation, characterize the optimization spaces and computational efficiencies of three included compiler environments, and provide extensive empirical evaluations. Compared to prior works, CompilerGym offers larger datasets and optimization spaces, is 27x more computationally efficient, is fault-tolerant, and capable of detecting reproducibility bugs in the underlying compilers. In making it easy for anyone to experiment with compilers - irrespective of their background - we aim to accelerate progress in the AI and compiler research domains.
Learning Space Partitions for Path Planning
Jul 14, 2021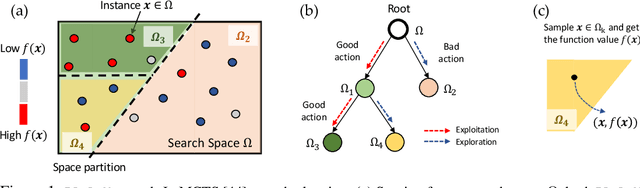

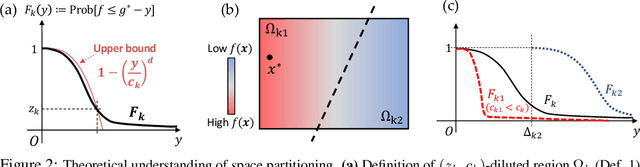
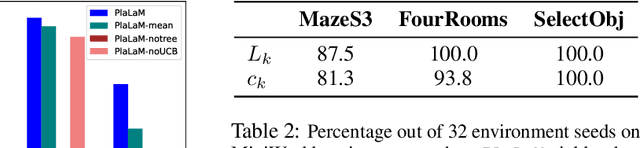
Path planning, the problem of efficiently discovering high-reward trajectories, often requires optimizing a high-dimensional and multimodal reward function. Popular approaches like CEM and CMA-ES greedily focus on promising regions of the search space and may get trapped in local maxima. DOO and VOOT balance exploration and exploitation, but use space partitioning strategies independent of the reward function to be optimized. Recently, LaMCTS empirically learns to partition the search space in a reward-sensitive manner for black-box optimization. In this paper, we develop a novel formal regret analysis for when and why such an adaptive region partitioning scheme works. We also propose a new path planning method PlaLaM which improves the function value estimation within each sub-region, and uses a latent representation of the search space. Empirically, PlaLaM outperforms existing path planning methods in 2D navigation tasks, especially in the presence of difficult-to-escape local optima, and shows benefits when plugged into model-based RL with planning components such as PETS. These gains transfer to highly multimodal real-world tasks, where we outperform strong baselines in compiler phase ordering by up to 245% and in molecular design by up to 0.4 on properties on a 0-1 scale. Code is available at https://github.com/yangkevin2/plalam.
Latent Execution for Neural Program Synthesis Beyond Domain-Specific Languages
Jun 29, 2021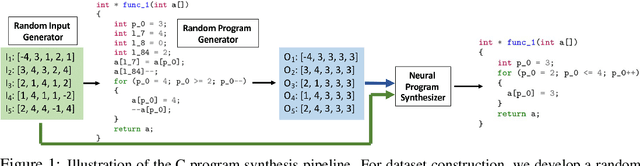

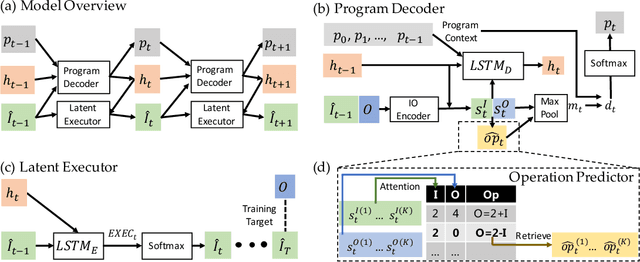
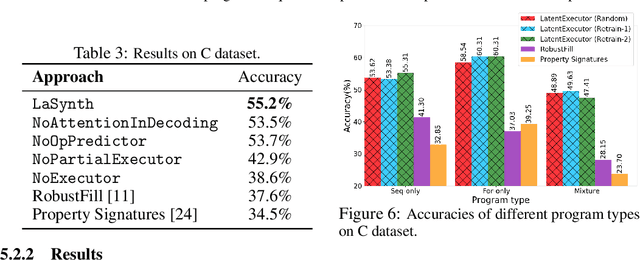
Program synthesis from input-output examples has been a long-standing challenge, and recent works have demonstrated some success in designing deep neural networks for program synthesis. However, existing efforts in input-output neural program synthesis have been focusing on domain-specific languages, thus the applicability of previous approaches to synthesize code in full-fledged popular programming languages, such as C, remains a question. The main challenges lie in two folds. On the one hand, the program search space grows exponentially when the syntax and semantics of the programming language become more complex, which poses higher requirements on the synthesis algorithm. On the other hand, increasing the complexity of the programming language also imposes more difficulties on data collection, since building a large-scale training set for input-output program synthesis require random program generators to sample programs and input-output examples. In this work, we take the first step to synthesize C programs from input-output examples. In particular, we propose LaSynth, which learns the latent representation to approximate the execution of partially generated programs, even if their semantics are not well-defined. We demonstrate the possibility of synthesizing elementary C code from input-output examples, and leveraging learned execution significantly improves the prediction performance over existing approaches. Meanwhile, compared to the randomly generated ground-truth programs, LaSynth synthesizes more concise programs that resemble human-written code. We show that training on these synthesized programs further improves the prediction performance for both Karel and C program synthesis, indicating the promise of leveraging the learned program synthesizer to improve the dataset quality for input-output program synthesis.
MADE: Exploration via Maximizing Deviation from Explored Regions
Jun 18, 2021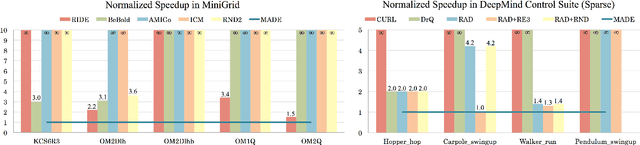
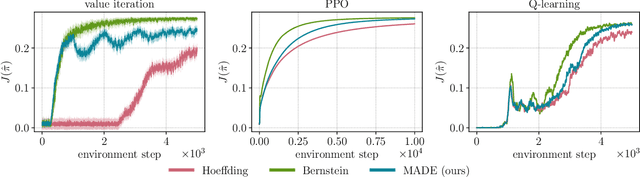

In online reinforcement learning (RL), efficient exploration remains particularly challenging in high-dimensional environments with sparse rewards. In low-dimensional environments, where tabular parameterization is possible, count-based upper confidence bound (UCB) exploration methods achieve minimax near-optimal rates. However, it remains unclear how to efficiently implement UCB in realistic RL tasks that involve non-linear function approximation. To address this, we propose a new exploration approach via \textit{maximizing} the deviation of the occupancy of the next policy from the explored regions. We add this term as an adaptive regularizer to the standard RL objective to balance exploration vs. exploitation. We pair the new objective with a provably convergent algorithm, giving rise to a new intrinsic reward that adjusts existing bonuses. The proposed intrinsic reward is easy to implement and combine with other existing RL algorithms to conduct exploration. As a proof of concept, we evaluate the new intrinsic reward on tabular examples across a variety of model-based and model-free algorithms, showing improvements over count-only exploration strategies. When tested on navigation and locomotion tasks from MiniGrid and DeepMind Control Suite benchmarks, our approach significantly improves sample efficiency over state-of-the-art methods. Our code is available at https://github.com/tianjunz/MADE.
Understanding Robustness in Teacher-Student Setting: A New Perspective
Mar 01, 2021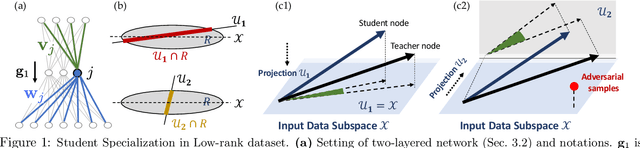

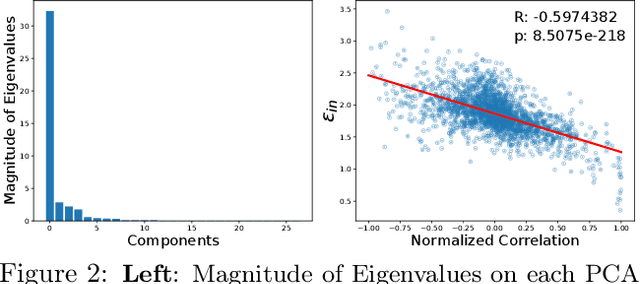
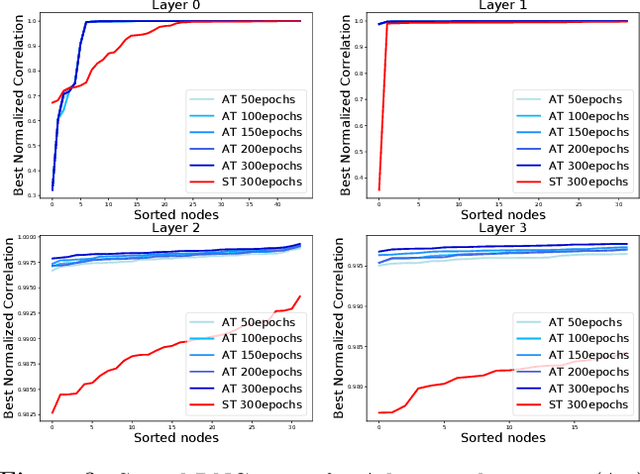
Adversarial examples have appeared as a ubiquitous property of machine learning models where bounded adversarial perturbation could mislead the models to make arbitrarily incorrect predictions. Such examples provide a way to assess the robustness of machine learning models as well as a proxy for understanding the model training process. Extensive studies try to explain the existence of adversarial examples and provide ways to improve model robustness (e.g. adversarial training). While they mostly focus on models trained on datasets with predefined labels, we leverage the teacher-student framework and assume a teacher model, or oracle, to provide the labels for given instances. We extend Tian (2019) in the case of low-rank input data and show that student specialization (trained student neuron is highly correlated with certain teacher neuron at the same layer) still happens within the input subspace, but the teacher and student nodes could differ wildly out of the data subspace, which we conjecture leads to adversarial examples. Extensive experiments show that student specialization correlates strongly with model robustness in different scenarios, including student trained via standard training, adversarial training, confidence-calibrated adversarial training, and training with robust feature dataset. Our studies could shed light on the future exploration about adversarial examples, and enhancing model robustness via principled data augmentation.
Provably Efficient Policy Gradient Methods for Two-Player Zero-Sum Markov Games
Feb 17, 2021Policy gradient methods are widely used in solving two-player zero-sum games to achieve superhuman performance in practice. However, it remains elusive when they can provably find a near-optimal solution and how many samples and iterations are needed. The current paper studies natural extensions of Natural Policy Gradient algorithm for solving two-player zero-sum games where function approximation is used for generalization across states. We thoroughly characterize the algorithms' performance in terms of the number of samples, number of iterations, concentrability coefficients, and approximation error. To our knowledge, this is the first quantitative analysis of policy gradient methods with function approximation for two-player zero-sum Markov games.
Understanding self-supervised Learning Dynamics without Contrastive Pairs
Feb 12, 2021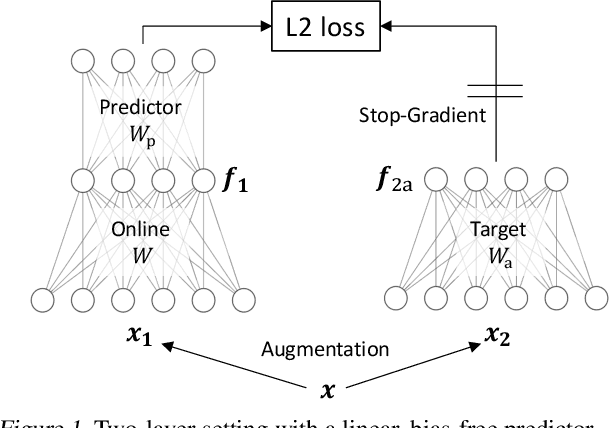
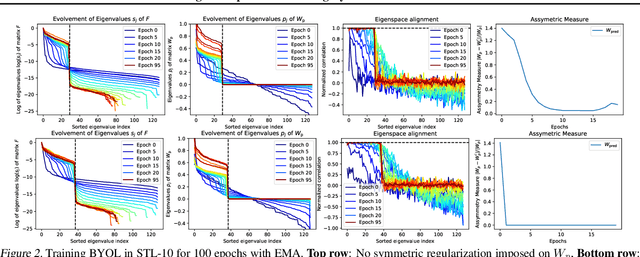

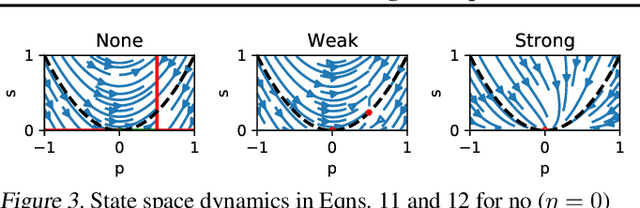
Contrastive approaches to self-supervised learning (SSL) learn representations by minimizing the distance between two augmented views of the same data point (positive pairs) and maximizing the same from different data points (negative pairs). However, recent approaches like BYOL and SimSiam, show remarkable performance {\it without} negative pairs, raising a fundamental theoretical question: how can SSL with only positive pairs avoid representational collapse? We study the nonlinear learning dynamics of non-contrastive SSL in simple linear networks. Our analysis yields conceptual insights into how non-contrastive SSL methods learn, how they avoid representational collapse, and how multiple factors, like predictor networks, stop-gradients, exponential moving averages, and weight decay all come into play. Our simple theory recapitulates the results of real-world ablation studies in both STL-10 and ImageNet. Furthermore, motivated by our theory we propose a novel approach that \emph{directly} sets the predictor based on the statistics of its inputs. In the case of linear predictors, our approach outperforms gradient training of the predictor by $5\%$ and on ImageNet it performs comparably with more complex two-layer non-linear predictors that employ BatchNorm. Code is released in https://github.com/facebookresearch/luckmatters/tree/master/ssl.
BeBold: Exploration Beyond the Boundary of Explored Regions
Dec 15, 2020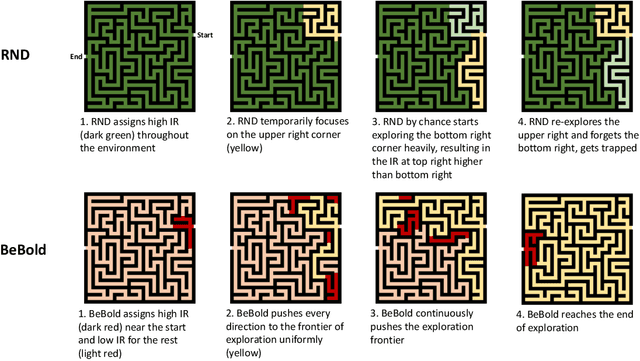
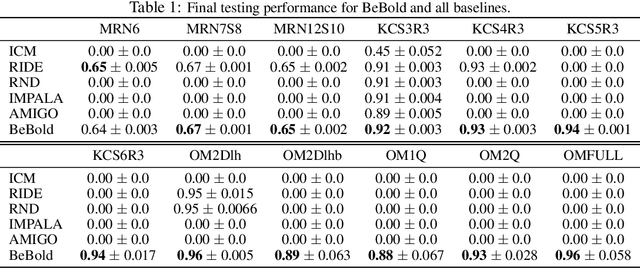
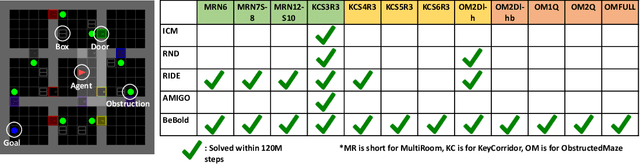

Efficient exploration under sparse rewards remains a key challenge in deep reinforcement learning. To guide exploration, previous work makes extensive use of intrinsic reward (IR). There are many heuristics for IR, including visitation counts, curiosity, and state-difference. In this paper, we analyze the pros and cons of each method and propose the regulated difference of inverse visitation counts as a simple but effective criterion for IR. The criterion helps the agent explore Beyond the Boundary of explored regions and mitigates common issues in count-based methods, such as short-sightedness and detachment. The resulting method, BeBold, solves the 12 most challenging procedurally-generated tasks in MiniGrid with just 120M environment steps, without any curriculum learning. In comparison, the previous SoTA only solves 50% of the tasks. BeBold also achieves SoTA on multiple tasks in NetHack, a popular rogue-like game that contains more challenging procedurally-generated environments.
FP-NAS: Fast Probabilistic Neural Architecture Search
Nov 24, 2020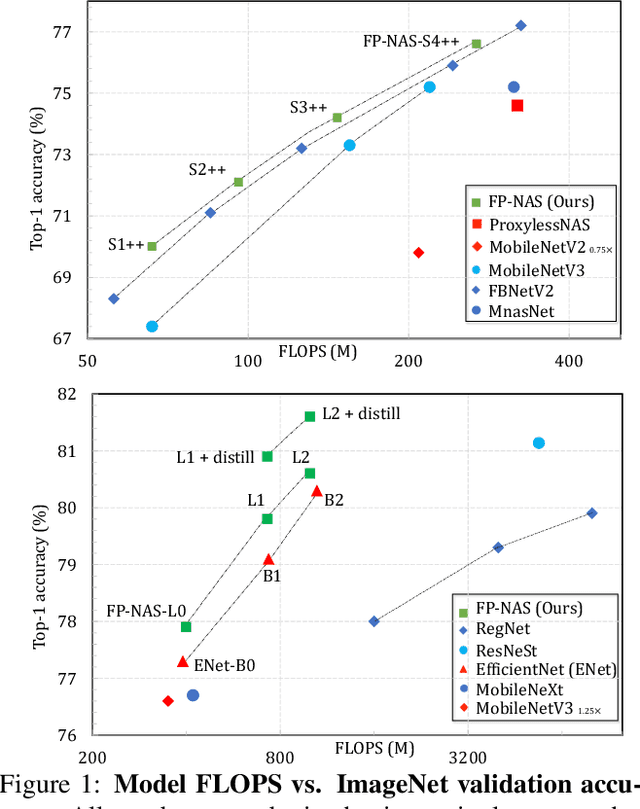
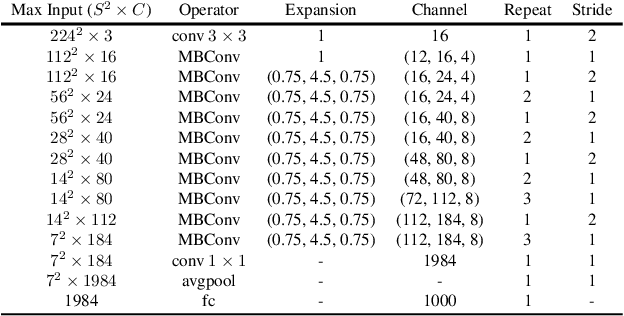
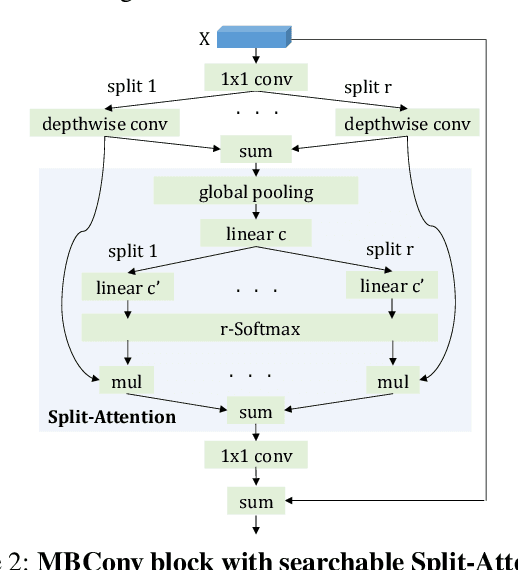

Differential Neural Architecture Search (NAS) requires all layer choices to be held in memory simultaneously; this limits the size of both search space and final architecture. In contrast, Probabilistic NAS, such as PARSEC, learns a distribution over high-performing architectures, and uses only as much memory as needed to train a single model. Nevertheless, it needs to sample many architectures, making it computationally expensive for searching in an extensive space. To solve these problems, we propose a sampling method adaptive to the distribution entropy, drawing more samples to encourage explorations at the beginning, and reducing samples as learning proceeds. Furthermore, to search fast in the multi-variate space, we propose a coarse-to-fine strategy by using a factorized distribution at the beginning which can reduce the number of architecture parameters by over an order of magnitude.We call this method Fast Probabilistic NAS (FP-NAS). Compared with PARSEC, it can sample 64% fewer architectures and search 2.1x faster. Compared with FBNetV2, FP-NAS is 1.9x - 3.6x faster, and the searched models outperform FBNetV2 models on ImageNet. FP-NAS allows us to expand the giant FBNetV2 space to be wider (i.e. larger channel choices) and deeper (i.e. more blocks), while adding Split-Attention block and enabling the search over the number of splits. When searching a model of size 0.4G FLOPS, FP-NAS is 132x faster than EfficientNet, and the searched FP-NAS-L0 model outperforms EfficientNet-B0 by 0.6% accuracy. Without using any architecture surrogate or scaling tricks, we directly search large models up to 1.0G FLOPS. Our FP-NAS-L2 model with simple distillation outperforms BigNAS-XL with advanced inplace distillation by 0.7% accuracy with less FLOPS.