 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillation-Resistant Watermarking for Model Protection in NLP
Oct 07, 2022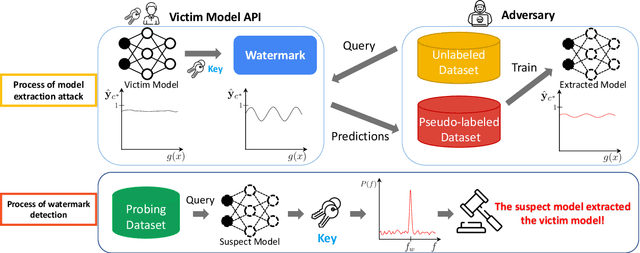
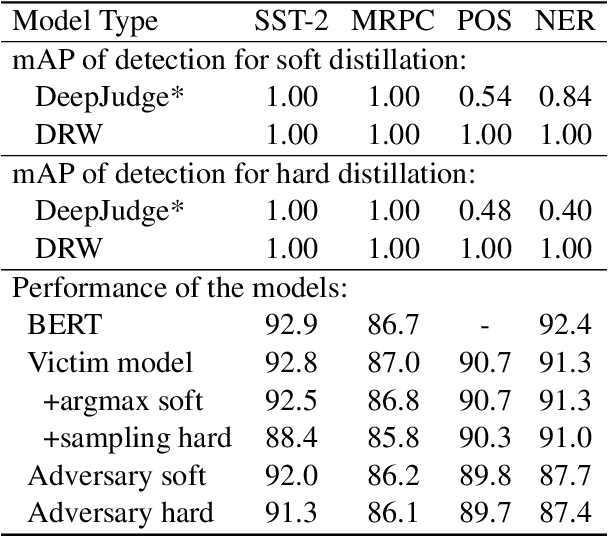
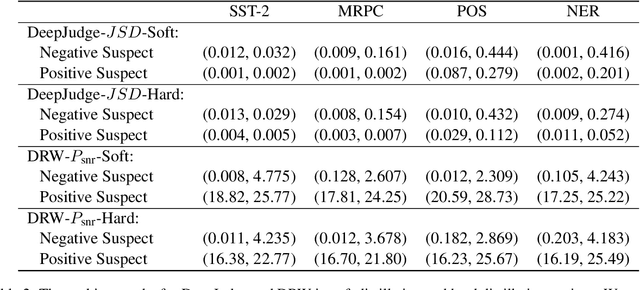
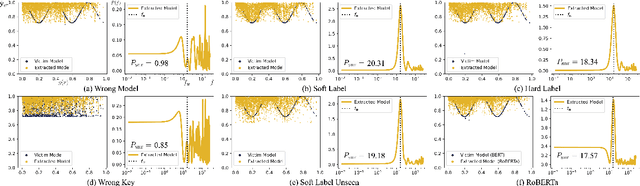
How can we protect the intellectual property of trained NLP models? Modern NLP models are prone to stealing by querying and distilling from their publicly exposed APIs. However, existing protection methods such as watermarking only work for images but are not applicable to text. We propose Distillation-Resistant Watermarking (DRW), a novel technique to protect NLP models from being stolen via distillation. DRW protects a model by injecting watermarks into the victim's prediction probability corresponding to a secret key and is able to detect such a key by probing a suspect model. We prove that a protected model still retains the original accuracy within a certain bound. We evaluate DRW on a diverse set of NLP tasks including text classification, part-of-speech tagging, and named entity recognition. Experiments show that DRW protects the original model and detects stealing suspects at 100% mean average precision for all four tasks while the prior method fails on two.
Differentially Private Bias-Term only Fine-tuning of Foundation Models
Oct 04, 2022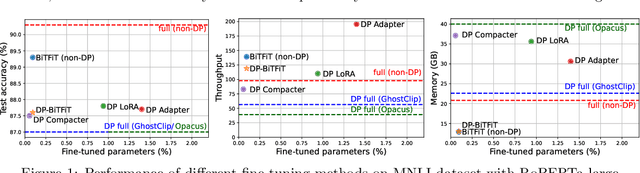
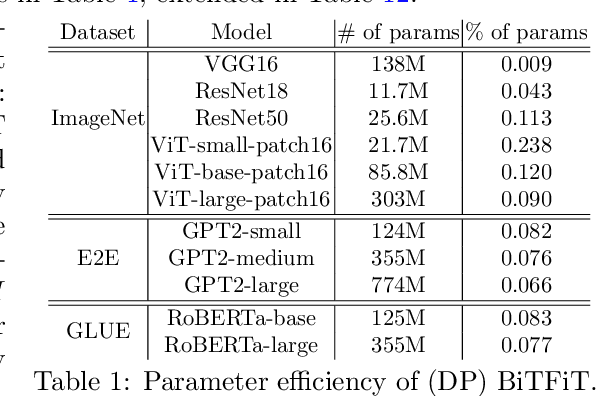
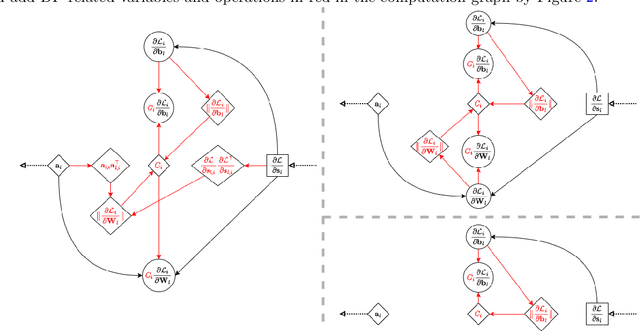
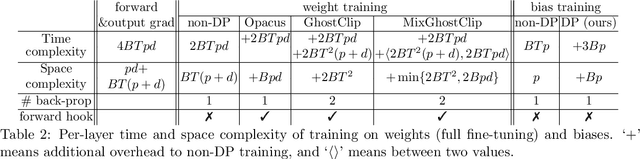
We study the problem of differentially private (DP) fine-tuning of large pre-trained models -- a recent privacy-preserving approach suitable for solving downstream tasks with sensitive data. Existing work has demonstrated that high accuracy is possible under strong privacy constraint, yet requires significant computational overhead or modifications to the network architecture. We propose differentially private bias-term fine-tuning (DP-BiTFiT), which matches the state-of-the-art accuracy for DP algorithms and the efficiency of the standard BiTFiT. DP-BiTFiT is model agnostic (not modifying the network architecture), parameter efficient (only training about $0.1\%$ of the parameters), and computation efficient (almost removing the overhead caused by DP, in both the time and space complexity). On a wide range of tasks, DP-BiTFiT is $2\sim 30\times$ faster and uses $2\sim 8\times$ less memory than DP full fine-tuning, even faster than the standard full fine-tuning. This amazing efficiency enables us to conduct DP fine-tuning on language and vision tasks with long-sequence texts and high-resolution images, which were computationally difficult using existing methods.
Offline Reinforcement Learning with Differentiable Function Approximation is Provably Efficient
Oct 03, 2022
Offline reinforcement learning, which aims at optimizing sequential decision-making strategies with historical data, has been extensively applied in real-life applications. State-Of-The-Art algorithms usually leverage powerful function approximators (e.g. neural networks) to alleviate the sample complexity hurdle for better empirical performances. Despite the successes, a more systematic understanding of the statistical complexity for function approximation remains lacking. Towards bridging the gap, we take a step by considering offline reinforcement learning with differentiable function class approximation (DFA). This function class naturally incorporates a wide range of models with nonlinear/nonconvex structures. Most importantly, we show offline RL with differentiable function approximation is provably efficient by analyzing the pessimistic fitted Q-learning (PFQL) algorithm, and our results provide the theoretical basis for understanding a variety of practical heuristics that rely on Fitted Q-Iteration style design. In addition, we further improve our guarantee with a tighter instance-dependent characterization. We hope our work could draw interest in studying reinforcement learning with differentiable function approximation beyond the scope of current research.
Near-Optimal Deployment Efficiency in Reward-Free Reinforcement Learning with Linear Function Approximation
Oct 03, 2022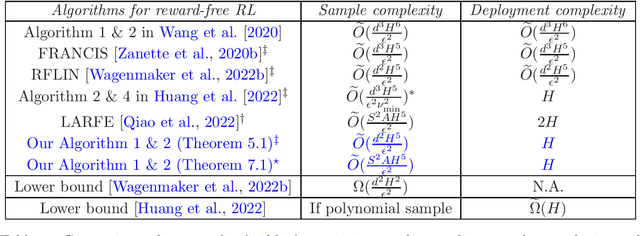

We study the problem of deployment efficient reinforcement learning (RL) with linear function approximation under the \emph{reward-free} exploration setting. This is a well-motivated problem because deploying new policies is costly in real-life RL applications. Under the linear MDP setting with feature dimension $d$ and planning horizon $H$, we propose a new algorithm that collects at most $\widetilde{O}(\frac{d^2H^5}{\epsilon^2})$ trajectories within $H$ deployments to identify $\epsilon$-optimal policy for any (possibly data-dependent) choice of reward functions. To the best of our knowledge, our approach is the first to achieve optimal deployment complexity and optimal $d$ dependence in sample complexity at the same time, even if the reward is known ahead of time. Our novel techniques include an exploration-preserving policy discretization and a generalized G-optimal experiment design, which could be of independent interest. Lastly, we analyze the related problem of regret minimization in low-adaptive RL and provide information-theoretic lower bounds for switching cost and batch complexity.
Differentially Private Optimization on Large Model at Small Cost
Sep 30, 2022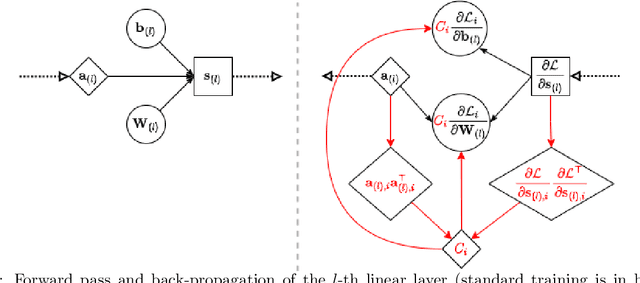

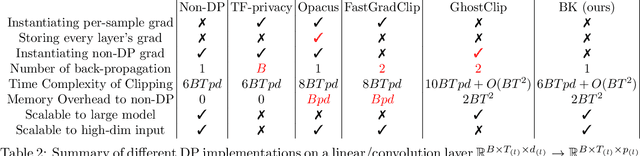

Differentially private (DP) optimization is the standard paradigm to learn large neural networks that are accurate and privacy-preserving. The computational cost for DP deep learning, however, is notoriously heavy due to the per-sample gradient clipping. Existing DP implementations are $2-1000\times$ more costly in time and space complexity than the standard (non-private) training. In this work, we develop a novel Book-Keeping (BK) technique that implements existing DP optimizers (thus achieving the same accuracy), with a substantial improvement on the computational cost. Specifically, BK enables DP training on large models and high dimensional data to be roughly as efficient as the standard training, whereas previous DP algorithms can be inefficient or incapable of training due to memory error. The computational advantage of BK is supported by the complexity analysis as well as extensive experiments on vision and language tasks. Our implementation achieves state-of-the-art (SOTA) accuracy with very small extra cost: on GPT2 and at the same memory cost, BK has 1.0$\times$ the time complexity of the standard training (0.75$\times$ training speed in practice), and 0.6$\times$ the time complexity of the most efficient DP implementation (1.24$\times$ training speed in practice). We will open-source the codebase for the BK algorithm.
Doubly Fair Dynamic Pricing
Sep 23, 2022We study the problem of online dynamic pricing with two types of fairness constraints: a "procedural fairness" which requires the proposed prices to be equal in expectation among different groups, and a "substantive fairness" which requires the accepted prices to be equal in expectation among different groups. A policy that is simultaneously procedural and substantive fair is referred to as "doubly fair". We show that a doubly fair policy must be random to have higher revenue than the best trivial policy that assigns the same price to different groups. In a two-group setting, we propose an online learning algorithm for the 2-group pricing problems that achieves $\tilde{O}(\sqrt{T})$ regret, zero procedural unfairness and $\tilde{O}(\sqrt{T})$ substantive unfairness over $T$ rounds of learning. We also prove two lower bounds showing that these results on regret and unfairness are both information-theoretically optimal up to iterated logarithmic factors. To the best of our knowledge, this is the first dynamic pricing algorithm that learns to price while satisfying two fairness constraints at the same time.
Optimal Dynamic Regret in LQR Control
Jun 18, 2022


We consider the problem of nonstochastic control with a sequence of quadratic losses, i.e., LQR control. We provide an efficient online algorithm that achieves an optimal dynamic (policy) regret of $\tilde{O}(\text{max}\{n^{1/3} \mathcal{TV}(M_{1:n})^{2/3}, 1\})$, where $\mathcal{TV}(M_{1:n})$ is the total variation of any oracle sequence of Disturbance Action policies parameterized by $M_1,...,M_n$ -- chosen in hindsight to cater to unknown nonstationarity. The rate improves the best known rate of $\tilde{O}(\sqrt{n (\mathcal{TV}(M_{1:n})+1)} )$ for general convex losses and we prove that it is information-theoretically optimal for LQR. Main technical components include the reduction of LQR to online linear regression with delayed feedback due to Foster and Simchowitz (2020), as well as a new proper learning algorithm with an optimal $\tilde{O}(n^{1/3})$ dynamic regret on a family of ``minibatched'' quadratic losses, which could be of independent interest.
Automatic Clipping: Differentially Private Deep Learning Made Easier and Stronger
Jun 14, 2022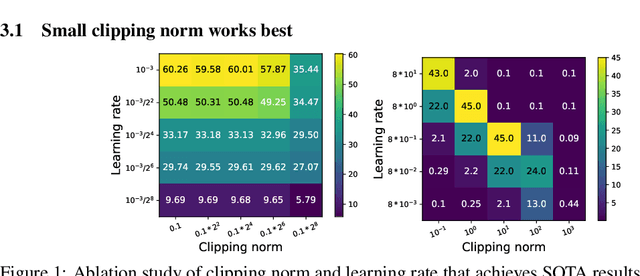
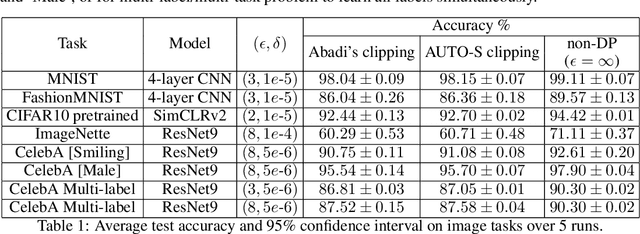
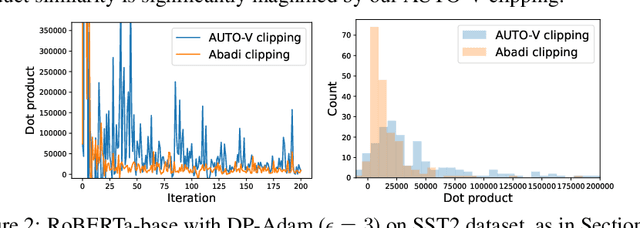
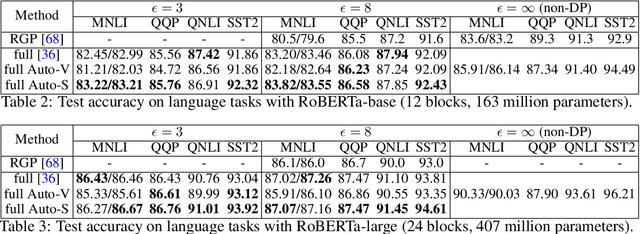
Per-example gradient clipping is a key algorithmic step that enables practical differential private (DP) training for deep learning models. The choice of clipping norm $R$, however, is shown to be vital for achieving high accuracy under DP. We propose an easy-to-use replacement, called AutoClipping, that eliminates the need to tune $R$ for any DP optimizers, including DP-SGD, DP-Adam, DP-LAMB and many others. The automatic variants are as private and computationally efficient as existing DP optimizers, but require no DP-specific hyperparameters and thus make DP training as amenable as the standard non-private training. We give a rigorous convergence analysis of automatic DP-SGD in the non-convex setting, which shows that it enjoys an asymptotic convergence rate that matches the standard SGD. We also demonstrate on various language and vision tasks that automatic clipping outperforms or matches the state-of-the-art, and can be easily employed with minimal changes to existing codebases.
Why Quantization Improves Generalization: NTK of Binary Weight Neural Networks
Jun 13, 2022
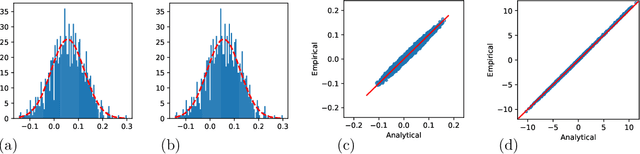
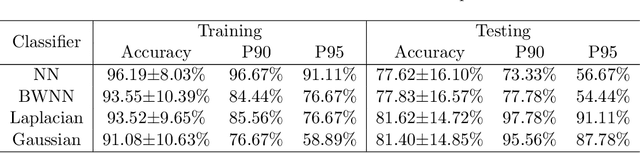
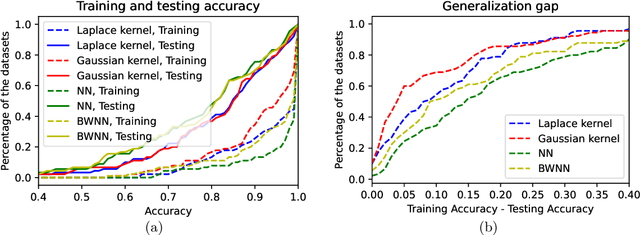
Quantized neural networks have drawn a lot of attention as they reduce the space and computational complexity during the inference. Moreover, there has been folklore that quantization acts as an implicit regularizer and thus can improve the generalizability of neural networks, yet no existing work formalizes this interesting folklore. In this paper, we take the binary weights in a neural network as random variables under stochastic rounding, and study the distribution propagation over different layers in the neural network. We propose a quasi neural network to approximate the distribution propagation, which is a neural network with continuous parameters and smooth activation function. We derive the neural tangent kernel (NTK) for this quasi neural network, and show that the eigenvalue of NTK decays at approximately exponential rate, which is comparable to that of Gaussian kernel with randomized scale. This in turn indicates that the Reproducing Kernel Hilbert Space (RKHS) of a binary weight neural network covers a strict subset of functions compared with the one with real value weights. We use experiments to verify that the quasi neural network we proposed can well approximate binary weight neural network. Furthermore, binary weight neural network gives a lower generalization gap compared with real value weight neural network, which is similar to the difference between Gaussian kernel and Laplace kernel.
Offline Stochastic Shortest Path: Learning, Evaluation and Towards Optimality
Jun 10, 2022
Goal-oriented Reinforcement Learning, where the agent needs to reach the goal state while simultaneously minimizing the cost, has received significant attention in real-world applications. Its theoretical formulation, stochastic shortest path (SSP), has been intensively researched in the online setting. Nevertheless, it remains understudied when such an online interaction is prohibited and only historical data is provided. In this paper, we consider the offline stochastic shortest path problem when the state space and the action space are finite. We design the simple value iteration-based algorithms for tackling both offline policy evaluation (OPE) and offline policy learning tasks. Notably, our analysis of these simple algorithms yields strong instance-dependent bounds which can imply worst-case bounds that are near-minimax optimal. We hope our study could help illuminate the fundamental statistical limits of the offline SSP problem and motivate further studies beyond the scope of current consideration.