 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask Transfiner for High-Quality Instance Segmentation
Nov 26, 2021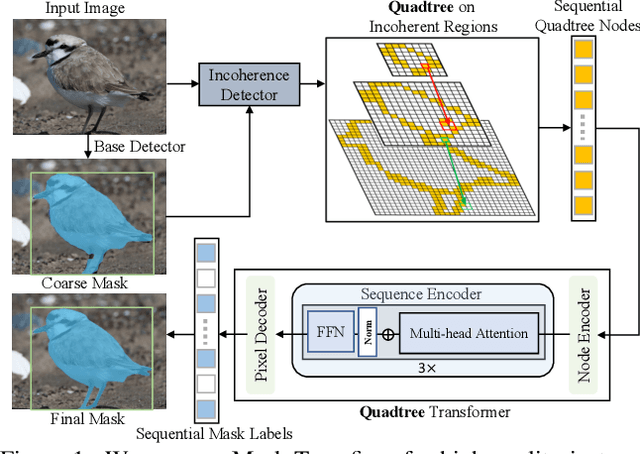


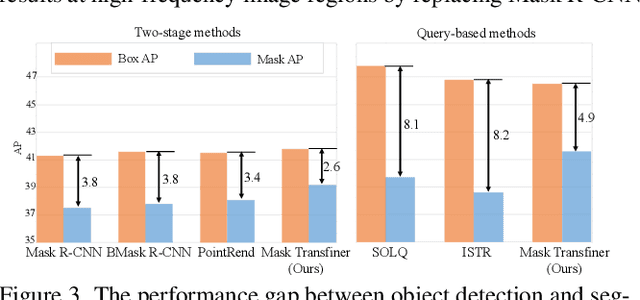
Two-stage and query-based instance segmentation methods have achieved remarkable results. However, their segmented masks are still very coarse. In this paper, we present Mask Transfiner for high-quality and efficient instance segmentation. Instead of operating on regular dense tensors, our Mask Transfiner decomposes and represents the image regions as a quadtree. Our transformer-based approach only processes detected error-prone tree nodes and self-corrects their errors in parallel. While these sparse pixels only constitute a small proportion of the total number, they are critical to the final mask quality. This allows Mask Transfiner to predict highly accurate instance masks, at a low computational cost. Extensive experiments demonstrate that Mask Transfiner outperforms current instance segmentation methods on three popular benchmarks, significantly improving both two-stage and query-based frameworks by a large margin of +3.0 mask AP on COCO and BDD100K, and +6.6 boundary AP on Cityscapes. Our code and trained models will be available at http://vis.xyz/pub/transfiner.
Occlusion-Aware Video Object Inpainting
Aug 15, 2021
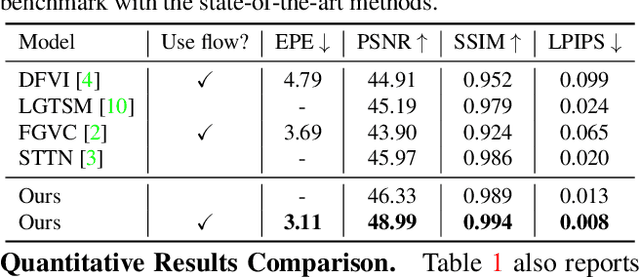
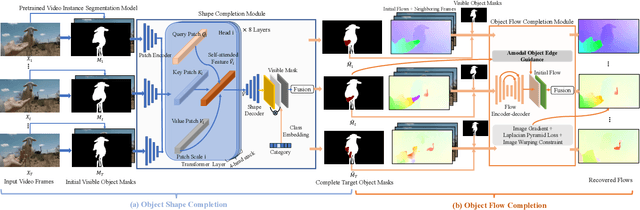
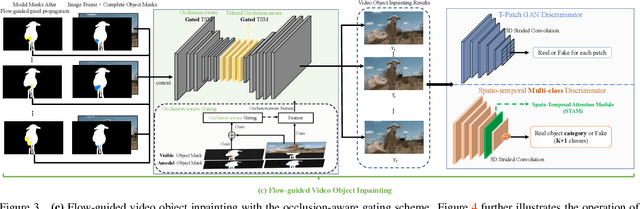
Conventional video inpainting is neither object-oriented nor occlusion-aware, making it liable to obvious artifacts when large occluded object regions are inpainted. This paper presents occlusion-aware video object inpainting, which recovers both the complete shape and appearance for occluded objects in videos given their visible mask segmentation. To facilitate this new research, we construct the first large-scale video object inpainting benchmark YouTube-VOI to provide realistic occlusion scenarios with both occluded and visible object masks available. Our technical contribution VOIN jointly performs video object shape completion and occluded texture generation. In particular, the shape completion module models long-range object coherence while the flow completion module recovers accurate flow with sharp motion boundary, for propagating temporally-consistent texture to the same moving object across frames. For more realistic results, VOIN is optimized using both T-PatchGAN and a new spatio-temporal attention-based multi-class discriminator. Finally, we compare VOIN and strong baselines on YouTube-VOI. Experimental results clearly demonstrate the efficacy of our method including inpainting complex and dynamic objects. VOIN degrades gracefully with inaccurate input visible mask.
Prototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation
Jun 22, 2021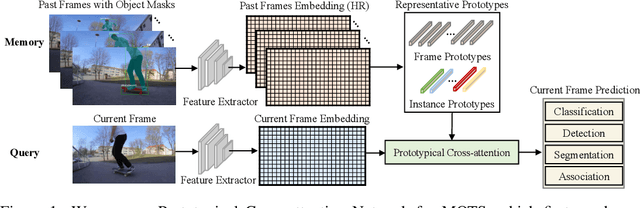
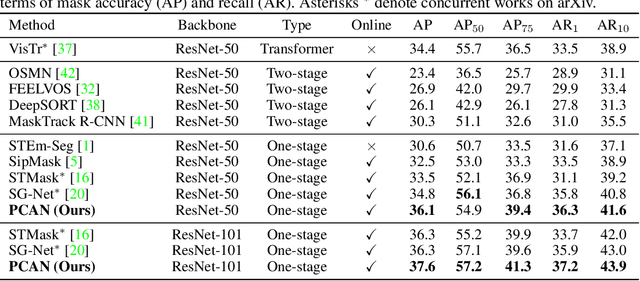
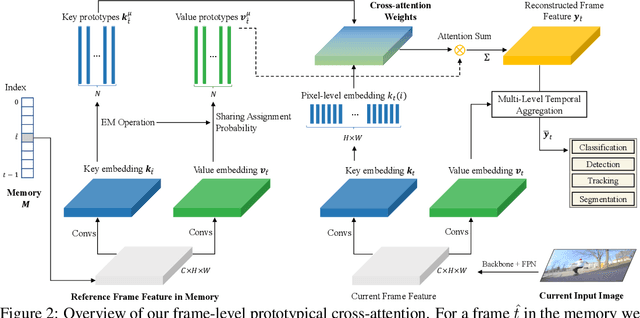

Multiple object tracking and segmentation requires detecting, tracking, and segmenting objects belonging to a set of given classes. Most approaches only exploit the temporal dimension to address the association problem, while relying on single frame predictions for the segmentation mask itself. We propose Prototypical Cross-Attention Network (PCAN), capable of leveraging rich spatio-temporal information for online multiple object tracking and segmentation. PCAN first distills a space-time memory into a set of prototypes and then employs cross-attention to retrieve rich information from the past frames. To segment each object, PCAN adopts a prototypical appearance module to learn a set of contrastive foreground and background prototypes, which are then propagated over time. Extensive experiments demonstrate that PCAN outperforms current video instance tracking and segmentation competition winners on both Youtube-VIS and BDD100K datasets, and shows efficacy to both one-stage and two-stage segmentation frameworks. Code will be available at http://vis.xyz/pub/pcan.
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
Jun 09, 2021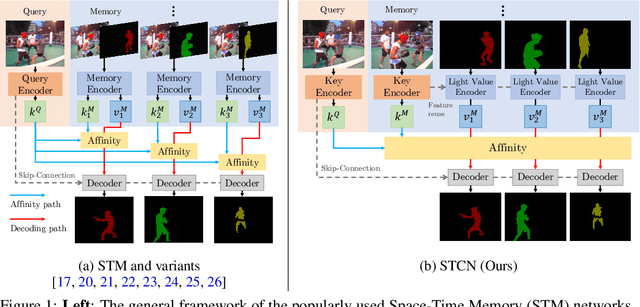

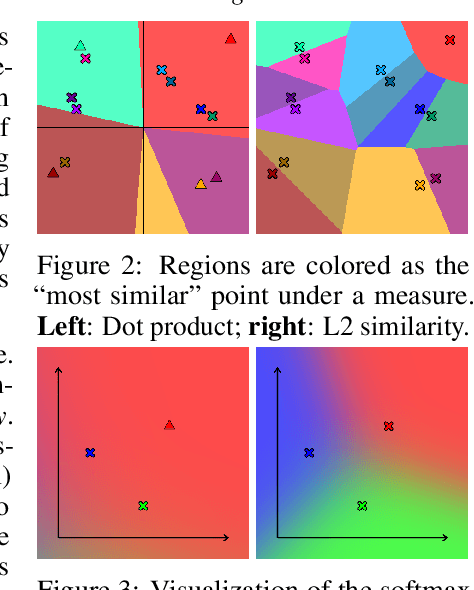
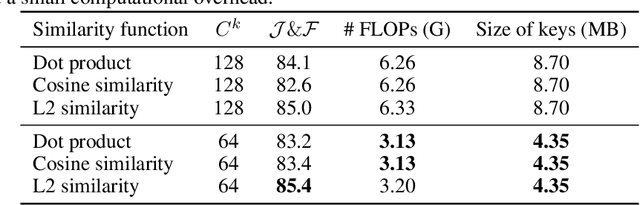
This paper presents a simple yet effective approach to modeling space-time correspondences in the context of video object segmentation. Unlike most existing approaches, we establish correspondences directly between frames without re-encoding the mask features for every object, leading to a highly efficient and robust framework. With the correspondences, every node in the current query frame is inferred by aggregating features from the past in an associative fashion. We cast the aggregation process as a voting problem and find that the existing inner-product affinity leads to poor use of memory with a small (fixed) subset of memory nodes dominating the votes, regardless of the query. In light of this phenomenon, we propose using the negative squared Euclidean distance instead to compute the affinities. We validated that every memory node now has a chance to contribute, and experimentally showed that such diversified voting is beneficial to both memory efficiency and inference accuracy. The synergy of correspondence networks and diversified voting works exceedingly well, achieves new state-of-the-art results on both DAVIS and YouTubeVOS datasets while running significantly faster at 20+ FPS for multiple objects without bells and whistles.
Few-Shot Video Object Detection
Apr 30, 2021
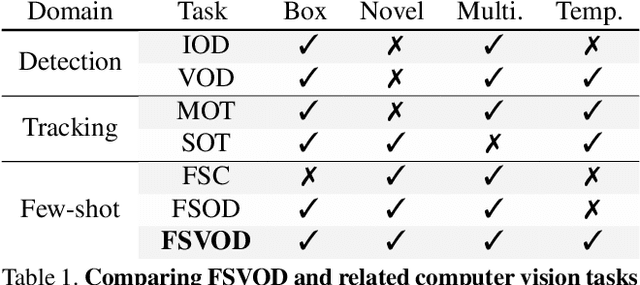
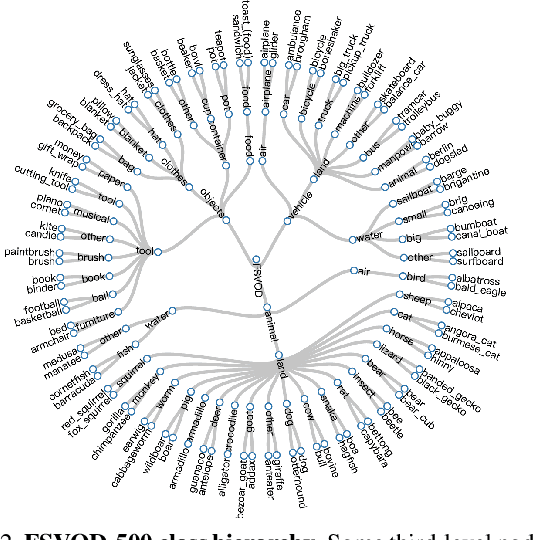
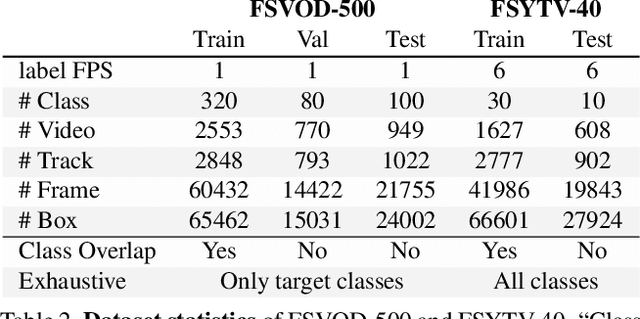
We introduce Few-Shot Video Object Detection (FSVOD) with three important contributions: 1) a large-scale video dataset FSVOD-500 comprising of 500 classes with class-balanced videos in each category for few-shot learning; 2) a novel Tube Proposal Network (TPN) to generate high-quality video tube proposals to aggregate feature representation for the target video object; 3) a strategically improved Temporal Matching Network (TMN+) to match representative query tube features and supports with better discriminative ability. Our TPN and TMN+ are jointly and end-to-end trained. Extensive experiments demonstrate that our method produces significantly better detection results on two few-shot video object detection datasets compared to image-based methods and other naive video-based extensions. Codes and datasets will be released at https://github.com/fanq15/FewX.
Deep Video Matting via Spatio-Temporal Alignment and Aggregation
Apr 22, 2021
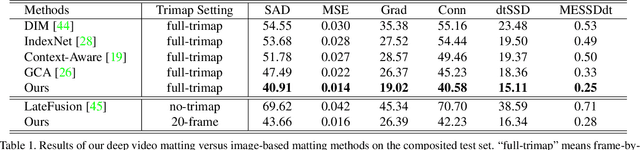
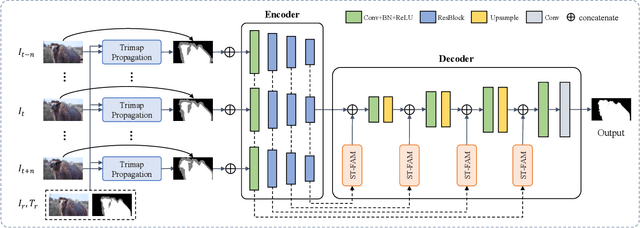
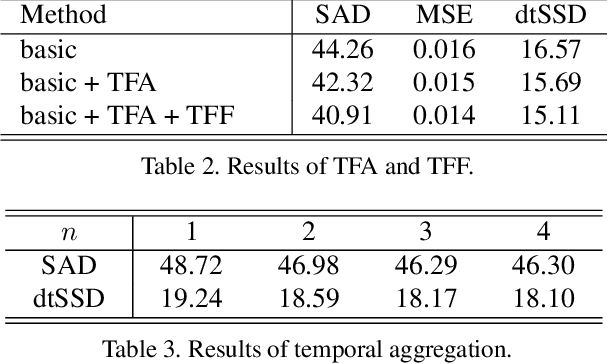
Despite the significant progress made by deep learning in natural image matting, there has been so far no representative work on deep learning for video matting due to the inherent technical challenges in reasoning temporal domain and lack of large-scale video matting datasets. In this paper, we propose a deep learning-based video matting framework which employs a novel and effective spatio-temporal feature aggregation module (ST-FAM). As optical flow estimation can be very unreliable within matting regions, ST-FAM is designed to effectively align and aggregate information across different spatial scales and temporal frames within the network decoder. To eliminate frame-by-frame trimap annotations, a lightweight interactive trimap propagation network is also introduced. The other contribution consists of a large-scale video matting dataset with groundtruth alpha mattes for quantitative evaluation and real-world high-resolution videos with trimaps for qualitative evaluation. Quantitative and qualitative experimental results show that our framework significantly outperforms conventional video matting and deep image matting methods applied to video in presence of multi-frame temporal information.
Few-Shot Model Adaptation for Customized Facial Landmark Detection, Segmentation, Stylization and Shadow Removal
Apr 19, 2021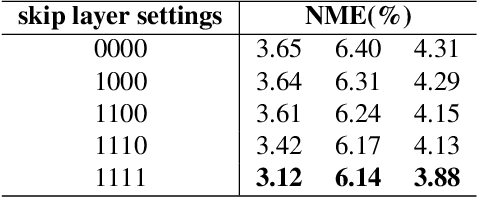
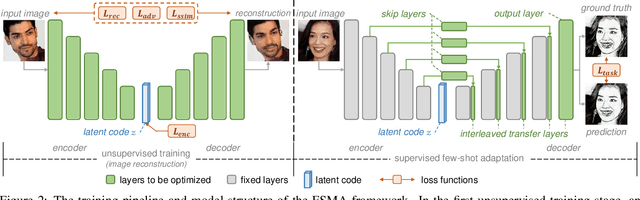
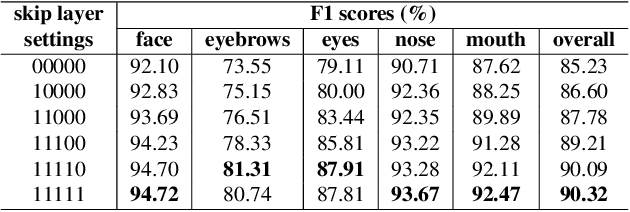
Despite excellent progress has been made, the performance of deep learning based algorithms still heavily rely on specific datasets, which are difficult to extend due to labor-intensive labeling. Moreover, because of the advancement of new applications, initial definition of data annotations might not always meet the requirements of new functionalities. Thus, there is always a great demand in customized data annotations. To address the above issues, we propose the Few-Shot Model Adaptation (FSMA) framework and demonstrate its potential on several important tasks on Faces. The FSMA first acquires robust facial image embeddings by training an adversarial auto-encoder using large-scale unlabeled data. Then the model is equipped with feature adaptation and fusion layers, and adapts to the target task efficiently using a minimal amount of annotated images. The FSMA framework is prominent in its versatility across a wide range of facial image applications. The FSMA achieves state-of-the-art few-shot landmark detection performance and it offers satisfying solutions for few-shot face segmentation, stylization and facial shadow removal tasks for the first time.
Semantic Image Matting
Apr 16, 2021
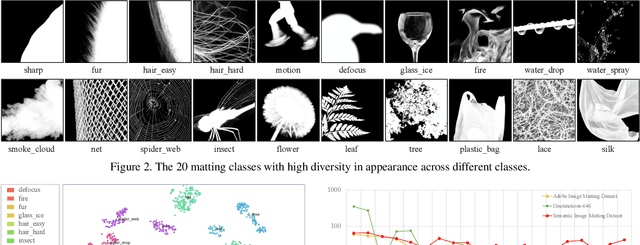
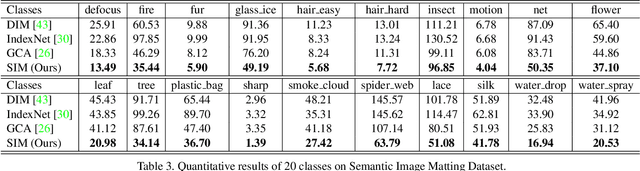
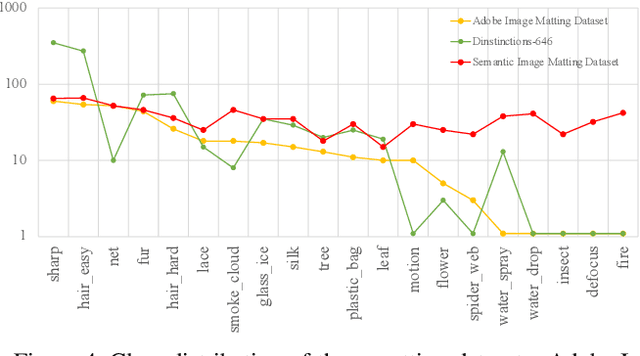
Natural image matting separates the foreground from background in fractional occupancy which can be caused by highly transparent objects, complex foreground (e.g., net or tree), and/or objects containing very fine details (e.g., hairs). Although conventional matting formulation can be applied to all of the above cases, no previous work has attempted to reason the underlying causes of matting due to various foreground semantics. We show how to obtain better alpha mattes by incorporating into our framework semantic classification of matting regions. Specifically, we consider and learn 20 classes of matting patterns, and propose to extend the conventional trimap to semantic trimap. The proposed semantic trimap can be obtained automatically through patch structure analysis within trimap regions. Meanwhile, we learn a multi-class discriminator to regularize the alpha prediction at semantic level, and content-sensitive weights to balance different regularization losses. Experiments on multiple benchmarks show that our method outperforms other methods and has achieved the most competitive state-of-the-art performance. Finally, we contribute a large-scale Semantic Image Matting Dataset with careful consideration of data balancing across different semantic classes.
Deep Occlusion-Aware Instance Segmentation with Overlapping BiLayers
Mar 23, 2021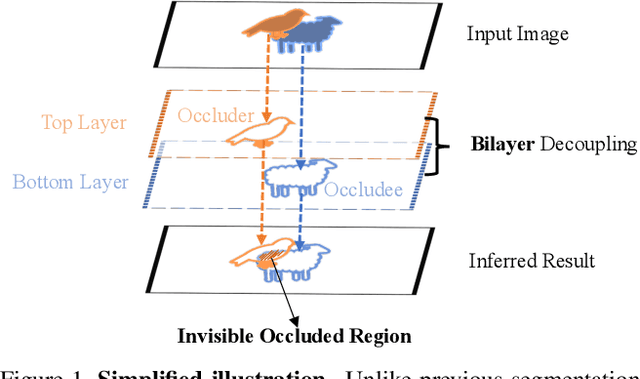
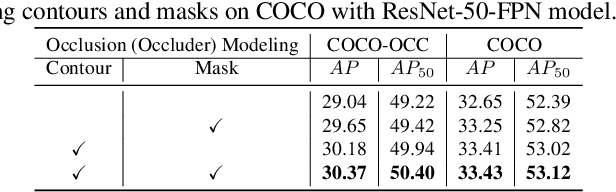

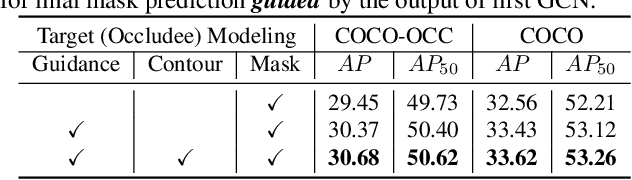
Segmenting highly-overlapping objects is challenging, because typically no distinction is made between real object contours and occlusion boundaries. Unlike previous two-stage instance segmentation methods, we model image formation as composition of two overlapping layers, and propose Bilayer Convolutional Network (BCNet), where the top GCN layer detects the occluding objects (occluder) and the bottom GCN layer infers partially occluded instance (occludee). The explicit modeling of occlusion relationship with bilayer structure naturally decouples the boundaries of both the occluding and occluded instances, and considers the interaction between them during mask regression. We validate the efficacy of bilayer decoupling on both one-stage and two-stage object detectors with different backbones and network layer choices. Despite its simplicity, extensive experiments on COCO and KINS show that our occlusion-aware BCNet achieves large and consistent performance gain especially for heavy occlusion cases. Code is available at https://github.com/lkeab/BCNet.
Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion
Mar 21, 2021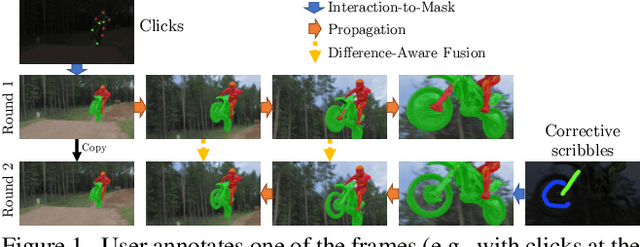
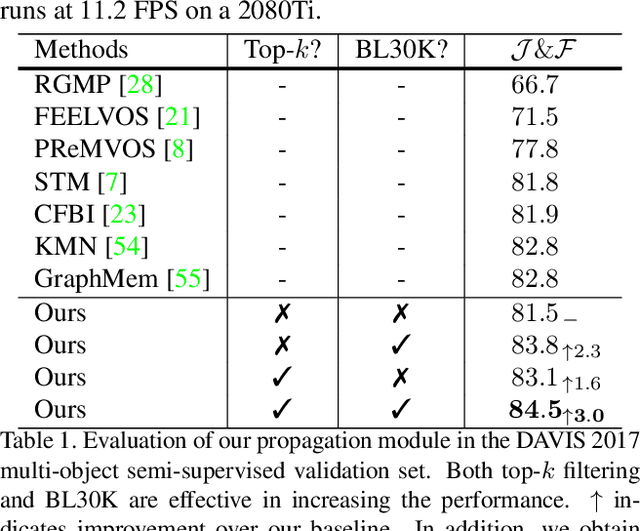
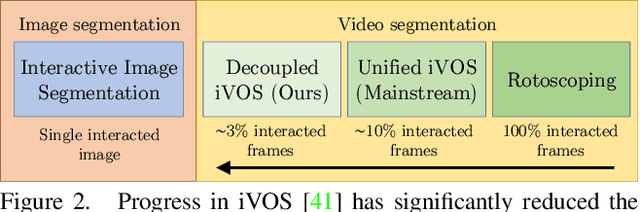
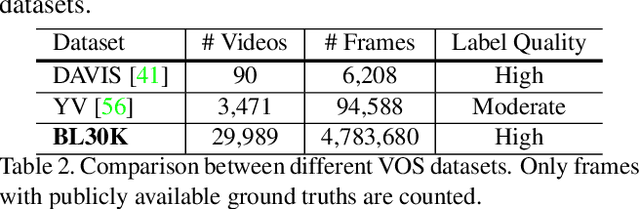
We present Modular interactive VOS (MiVOS) framework which decouples interaction-to-mask and mask propagation, allowing for higher generalizability and better performance. Trained separately, the interaction module converts user interactions to an object mask, which is then temporally propagated by our propagation module using a novel top-$k$ filtering strategy in reading the space-time memory. To effectively take the user's intent into account, a novel difference-aware module is proposed to learn how to properly fuse the masks before and after each interaction, which are aligned with the target frames by employing the space-time memory. We evaluate our method both qualitatively and quantitatively with different forms of user interactions (e.g., scribbles, clicks) on DAVIS to show that our method outperforms current state-of-the-art algorithms while requiring fewer frame interactions, with the additional advantage in generalizing to different types of user interactions. We contribute a large-scale synthetic VOS dataset with pixel-accurate segmentation of 4.8M frames to accompany our source codes to facilitate future research.