 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReelWave: A Multi-Agent Framework Toward Professional Movie Sound Generation
Mar 10, 2025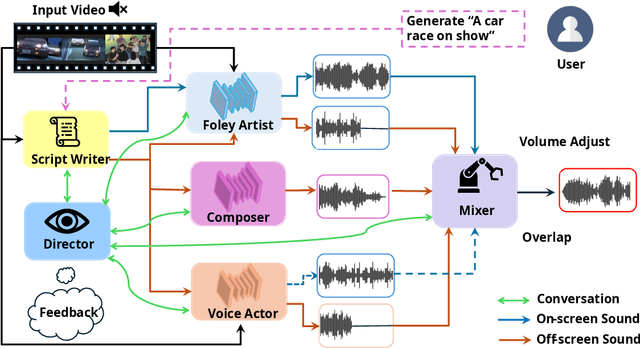

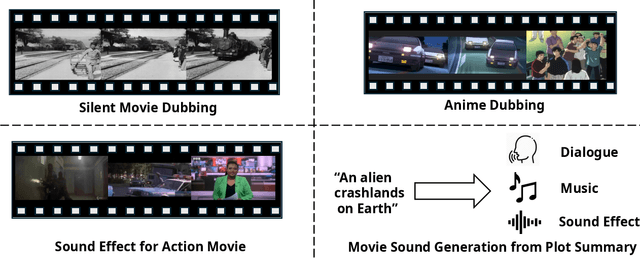
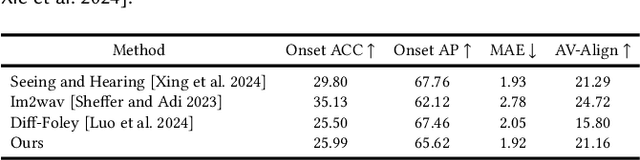
Film production is an important application for generative audio, where richer context is provided through multiple scenes. In ReelWave, we propose a multi-agent framework for audio generation inspired by the professional movie production process. We first capture semantic and temporal synchronized "on-screen" sound by training a prediction model that predicts three interpretable time-varying audio control signals comprising loudness, pitch, and timbre. These three parameters are subsequently specified as conditions by a cross-attention module. Then, our framework infers "off-screen" sound to complement the generation through cooperative interaction between communicative agents. Each agent takes up specific roles similar to the movie production team and is supervised by an agent called the director. Besides, we investigate when the conditional video consists of multiple scenes, a case frequently seen in videos extracted from movies of considerable length. Consequently, our framework can capture a richer context of audio generation conditioned on video clips extracted from movies.
WorldCraft: Photo-Realistic 3D World Creation and Customization via LLM Agents
Feb 21, 2025Constructing photorealistic virtual worlds has applications across various fields, but it often requires the extensive labor of highly trained professionals to operate conventional 3D modeling software. To democratize this process, we introduce WorldCraft, a system where large language model (LLM) agents leverage procedural generation to create indoor and outdoor scenes populated with objects, allowing users to control individual object attributes and the scene layout using intuitive natural language commands. In our framework, a coordinator agent manages the overall process and works with two specialized LLM agents to complete the scene creation: ForgeIt, which integrates an ever-growing manual through auto-verification to enable precise customization of individual objects, and ArrangeIt, which formulates hierarchical optimization problems to achieve a layout that balances ergonomic and aesthetic considerations. Additionally, our pipeline incorporates a trajectory control agent, allowing users to animate the scene and operate the camera through natural language interactions. Our system is also compatible with off-the-shelf deep 3D generators to enrich scene assets. Through evaluations and comparisons with state-of-the-art methods, we demonstrate the versatility of WorldCraft, ranging from single-object customization to intricate, large-scale interior and exterior scene designs. This system empowers non-professionals to bring their creative visions to life.
UVRM: A Scalable 3D Reconstruction Model from Unposed Videos
Jan 16, 2025



Large Reconstruction Models (LRMs) have recently become a popular method for creating 3D foundational models. Training 3D reconstruction models with 2D visual data traditionally requires prior knowledge of camera poses for the training samples, a process that is both time-consuming and prone to errors. Consequently, 3D reconstruction training has been confined to either synthetic 3D datasets or small-scale datasets with annotated poses. In this study, we investigate the feasibility of 3D reconstruction using unposed video data of various objects. We introduce UVRM, a novel 3D reconstruction model capable of being trained and evaluated on monocular videos without requiring any information about the pose. UVRM uses a transformer network to implicitly aggregate video frames into a pose-invariant latent feature space, which is then decoded into a tri-plane 3D representation. To obviate the need for ground-truth pose annotations during training, UVRM employs a combination of the score distillation sampling (SDS) method and an analysis-by-synthesis approach, progressively synthesizing pseudo novel-views using a pre-trained diffusion model. We qualitatively and quantitatively evaluate UVRM's performance on the G-Objaverse and CO3D datasets without relying on pose information. Extensive experiments show that UVRM is capable of effectively and efficiently reconstructing a wide range of 3D objects from unposed videos.
Audio-Agent: Leveraging LLMs For Audio Generation, Editing and Composition
Oct 04, 2024We introduce Audio-Agent, a multimodal framework for audio generation, editing and composition based on text or video inputs. Conventional approaches for text-to-audio (TTA) tasks often make single-pass inferences from text descriptions. While straightforward, this design struggles to produce high-quality audio when given complex text conditions. In our method, we utilize a pre-trained TTA diffusion network as the audio generation agent to work in tandem with GPT-4, which decomposes the text condition into atomic, specific instructions, and calls the agent for audio generation. Consequently, Audio-Agent generates high-quality audio that is closely aligned with the provided text or video while also supporting variable-length generation. For video-to-audio (VTA) tasks, most existing methods require training a timestamp detector to synchronize video events with generated audio, a process that can be tedious and time-consuming. We propose a simpler approach by fine-tuning a pre-trained Large Language Model (LLM), e.g., Gemma2-2B-it, to obtain both semantic and temporal conditions to bridge video and audio modality. Thus our framework provides a comprehensive solution for both TTA and VTA tasks without substantial computational overhead in training.
Reward-RAG: Enhancing RAG with Reward Driven Supervision
Oct 03, 2024



In this paper, we introduce Reward-RAG, a novel approach designed to enhance the Retrieval-Augmented Generation (RAG) model through Reward-Driven Supervision. Unlike previous RAG methodologies, which focus on training language models (LMs) to utilize external knowledge retrieved from external sources, our method adapts retrieval information to specific domains by employing CriticGPT to train a dedicated reward model. This reward model generates synthesized datasets for fine-tuning the RAG encoder, aligning its outputs more closely with human preferences. The versatility of our approach allows it to be effectively applied across various domains through domain-specific fine-tuning. We evaluate Reward-RAG on publicly available benchmarks from multiple domains, comparing it to state-of-the-art methods. Our experimental results demonstrate significant improvements in performance, highlighting the effectiveness of Reward-RAG in improving the relevance and quality of generated responses. These findings underscore the potential of integrating reward models with RAG to achieve superior outcomes in natural language generation tasks.
ChatCam: Empowering Camera Control through Conversational AI
Sep 25, 2024Cinematographers adeptly capture the essence of the world, crafting compelling visual narratives through intricate camera movements. Witnessing the strides made by large language models in perceiving and interacting with the 3D world, this study explores their capability to control cameras with human language guidance. We introduce ChatCam, a system that navigates camera movements through conversations with users, mimicking a professional cinematographer's workflow. To achieve this, we propose CineGPT, a GPT-based autoregressive model for text-conditioned camera trajectory generation. We also develop an Anchor Determinator to ensure precise camera trajectory placement. ChatCam understands user requests and employs our proposed tools to generate trajectories, which can be used to render high-quality video footage on radiance field representations. Our experiments, including comparisons to state-of-the-art approaches and user studies, demonstrate our approach's ability to interpret and execute complex instructions for camera operation, showing promising applications in real-world production settings.
VP-LLM: Text-Driven 3D Volume Completion with Large Language Models through Patchification
Jun 08, 2024



Recent conditional 3D completion works have mainly relied on CLIP or BERT to encode textual information, which cannot support complex instruction. Meanwhile, large language models (LLMs) have shown great potential in multi-modal understanding and generation tasks. Inspired by the recent advancements of LLM, we present Volume Patch LLM (VP-LLM), which leverages LLMs to perform conditional 3D completion in a single-forward pass. To integrate a 3D model into the LLM tokenization configuration, the incomplete 3D object is first divided into small patches that can be encoded independently. These encoded patches are then fed into an LLM along with the text prompt, instructing the LLM to capture the relations between these patches as well as injecting semantic meanings into the 3D object. Our results demonstrate a strong ability of LLMs to interpret complex text instructions and understand 3D objects, surpassing state-of-the-art diffusion-based 3D completion models in generation quality.
Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-aware Spatio-Temporal Sampling
Jun 06, 2024



Extensions of Neural Radiance Fields (NeRFs) to model dynamic scenes have enabled their near photo-realistic, free-viewpoint rendering. Although these methods have shown some potential in creating immersive experiences, two drawbacks limit their ubiquity: (i) a significant reduction in reconstruction quality when the computing budget is limited, and (ii) a lack of semantic understanding of the underlying scenes. To address these issues, we introduce Gear-NeRF, which leverages semantic information from powerful image segmentation models. Our approach presents a principled way for learning a spatio-temporal (4D) semantic embedding, based on which we introduce the concept of gears to allow for stratified modeling of dynamic regions of the scene based on the extent of their motion. Such differentiation allows us to adjust the spatio-temporal sampling resolution for each region in proportion to its motion scale, achieving more photo-realistic dynamic novel view synthesis. At the same time, almost for free, our approach enables free-viewpoint tracking of objects of interest - a functionality not yet achieved by existing NeRF-based methods. Empirical studies validate the effectiveness of our method, where we achieve state-of-the-art rendering and tracking performance on multiple challenging datasets.
MotionLLM: Multimodal Motion-Language Learning with Large Language Models
May 28, 2024



Recent advancements in Multimodal Large Language Models (MM-LLMs) have demonstrated promising potential in terms of generalization and robustness when applied to different modalities. While previous works have already achieved 3D human motion generation using various approaches including language modeling, they mostly % are mostly carefully designed use specialized architecture and are restricted to single-human motion generation. Inspired by the success of MM-LLMs, we propose MotionLLM, a simple and general framework that can achieve single-human, multi-human motion generation, and motion captioning by fine-tuning pre-trained LLMs. Specifically, we encode and quantize motions into discrete LLM-understandable tokens, which results in a unified vocabulary consisting of both motion and text tokens. With only 1--3% parameters of the LLMs trained by using adapters, our single-human motion generation achieves comparable results to those diffusion models and other trained-from-scratch transformer-based models. Additionally, we show that our approach is scalable and flexible, allowing easy extension to multi-human motion generation through autoregressive generation of single-human motions. Project page: https://knoxzhao.github.io/MotionLLM
C3LLM: Conditional Multimodal Content Generation Using Large Language Models
May 25, 2024We introduce C3LLM (Conditioned-on-Three-Modalities Large Language Models), a novel framework combining three tasks of video-to-audio, audio-to-text, and text-to-audio together. C3LLM adapts the Large Language Model (LLM) structure as a bridge for aligning different modalities, synthesizing the given conditional information, and making multimodal generation in a discrete manner. Our contributions are as follows. First, we adapt a hierarchical structure for audio generation tasks with pre-trained audio codebooks. Specifically, we train the LLM to generate audio semantic tokens from the given conditions, and further use a non-autoregressive transformer to generate different levels of acoustic tokens in layers to better enhance the fidelity of the generated audio. Second, based on the intuition that LLMs were originally designed for discrete tasks with the next-word prediction method, we use the discrete representation for audio generation and compress their semantic meanings into acoustic tokens, similar to adding "acoustic vocabulary" to LLM. Third, our method combines the previous tasks of audio understanding, video-to-audio generation, and text-to-audio generation together into one unified model, providing more versatility in an end-to-end fashion. Our C3LLM achieves improved results through various automated evaluation metrics, providing better semantic alignment compared to previous methods.