 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Contrastive Reasoning for Multi-Table Q&A
Jun 03, 2026Multi-table question answering requires models to retrieve relevant evidence, link schemas, and perform compositional reasoning across relational tables. Existing multi-table Q&A resources typically provide questions and final answers but lack reasoning supervision that explains how answers are derived. To address this gap, we construct a synthetic contrastive reasoning-trace dataset for MMQA by generating validated positive traces and plausible negative traces with heterogeneous LLMs. We then use the resulting preference pairs to fine-tune open-weight LLMs with Contrastive Preference Optimization (CPO). Across Qwen3-14B, Mistral-8B, and Llama-3.1-8B, CPO achieves absolute average improvements over Q&A supervised fine-tuning ranging from 9.7%-16.3%, with gains up to 21 percentage points on MMQA. Ablations show that heterogeneous positive and negative trace generators strengthen the contrastive signal, and automated as well as human evaluations indicate that the generated pairs are largely faithful, coherent, and meaningfully contrastive.
Hybrid Verified Decoding: Learning to Allocate Verification in Speculative Decoding
May 31, 2026Large Language Model (LLM) generation remains expensive because autoregressive decoding calls the model once for each new token. Speculative decoding reduces this cost by drafting multiple tokens and verifying them with the target model in one step, but its speedup depends on how many drafted tokens are accepted. Parameter-free draft sources can propose long continuations at low cost in structured and agentic workloads, yet a cache match that looks promising at one generation step may have low payoff at the next. We propose Hybrid Verified Decoding, which predicts the accepted length of a cache draft before verification and uses this payoff estimate to choose between cache verification and a model-based drafter. Across three LLMs and sixteen datasets, Hybrid Verified Decoding is especially effective on agentic workflows, where it outperforms EAGLE3 in every setting with a 2.73x average speedup. Our analysis shows how prompt structure creates cache opportunities, how high-payoff cache drafts concentrate in a small part of the draft space, and how payoff-guided selection reduces sequential decoding work, pointing to runtime draft selection as a promising direction for speculative decoding.
Cross-Cultural Value Awareness in Large Vision-Language Models
Apr 10, 2026The rapid adoption of large vision-language models (LVLMs) in recent years has been accompanied by growing fairness concerns due to their propensity to reinforce harmful societal stereotypes. While significant attention has been paid to such fairness concerns in the context of social biases, relatively little prior work has examined the presence of stereotypes in LVLMs related to cultural contexts such as religion, nationality, and socioeconomic status. In this work, we aim to narrow this gap by investigating how cultural contexts depicted in images influence the judgments LVLMs make about a person's moral, ethical, and political values. We conduct a multi-dimensional analysis of such value judgments in five popular LVLMs using counterfactual image sets, which depict the same person across different cultural contexts. Our evaluation framework diagnoses LVLM awareness of cultural value differences through the use of Moral Foundations Theory, lexical analyses, and the sensitivity of generated values to depicted cultural contexts.
Cultural Counterfactuals: Evaluating Cultural Biases in Large Vision-Language Models with Counterfactual Examples
Mar 02, 2026Large Vision-Language Models (LVLMs) have grown increasingly powerful in recent years, but can also exhibit harmful biases. Prior studies investigating such biases have primarily focused on demographic traits related to the visual characteristics of a person depicted in an image, such as their race or gender. This has left biases related to cultural differences (e.g., religion, socioeconomic status), which cannot be readily discerned from an individual's appearance alone, relatively understudied. A key challenge in measuring cultural biases is that determining which group an individual belongs to often depends upon cultural context cues in images, and datasets annotated with cultural context cues are lacking. To address this gap, we introduce Cultural Counterfactuals: a high-quality synthetic dataset containing nearly 60k counterfactual images for measuring cultural biases related to religion, nationality, and socioeconomic status. To ensure that cultural contexts are accurately depicted, we generate our dataset using an image-editing model to place people of different demographics into real cultural context images. This enables the construction of counterfactual image sets which depict the same person in multiple different contexts, allowing for precise measurement of the impact that cultural context differences have on LVLM outputs. We demonstrate the utility of Cultural Counterfactuals for quantifying cultural biases in popular LVLMs.
Investigating the Robustness of Retrieval-Augmented Generation at the Query Level
Jul 09, 2025Large language models (LLMs) are very costly and inefficient to update with new information. To address this limitation, retrieval-augmented generation (RAG) has been proposed as a solution that dynamically incorporates external knowledge during inference, improving factual consistency and reducing hallucinations. Despite its promise, RAG systems face practical challenges-most notably, a strong dependence on the quality of the input query for accurate retrieval. In this paper, we investigate the sensitivity of different components in the RAG pipeline to various types of query perturbations. Our analysis reveals that the performance of commonly used retrievers can degrade significantly even under minor query variations. We study each module in isolation as well as their combined effect in an end-to-end question answering setting, using both general-domain and domain-specific datasets. Additionally, we propose an evaluation framework to systematically assess the query-level robustness of RAG pipelines and offer actionable recommendations for practitioners based on the results of more than 1092 experiments we performed.
A Semantic Parsing Framework for End-to-End Time Normalization
Jul 08, 2025Time normalization is the task of converting natural language temporal expressions into machine-readable representations. It underpins many downstream applications in information retrieval, question answering, and clinical decision-making. Traditional systems based on the ISO-TimeML schema limit expressivity and struggle with complex constructs such as compositional, event-relative, and multi-span time expressions. In this work, we introduce a novel formulation of time normalization as a code generation task grounded in the SCATE framework, which defines temporal semantics through symbolic and compositional operators. We implement a fully executable SCATE Python library and demonstrate that large language models (LLMs) can generate executable SCATE code. Leveraging this capability, we develop an automatic data augmentation pipeline using LLMs to synthesize large-scale annotated data with code-level validation. Our experiments show that small, locally deployable models trained on this augmented data can achieve strong performance, outperforming even their LLM parents and enabling practical, accurate, and interpretable time normalization.
Analyzing Hierarchical Structure in Vision Models with Sparse Autoencoders
May 21, 2025The ImageNet hierarchy provides a structured taxonomy of object categories, offering a valuable lens through which to analyze the representations learned by deep vision models. In this work, we conduct a comprehensive analysis of how vision models encode the ImageNet hierarchy, leveraging Sparse Autoencoders (SAEs) to probe their internal representations. SAEs have been widely used as an explanation tool for large language models (LLMs), where they enable the discovery of semantically meaningful features. Here, we extend their use to vision models to investigate whether learned representations align with the ontological structure defined by the ImageNet taxonomy. Our results show that SAEs uncover hierarchical relationships in model activations, revealing an implicit encoding of taxonomic structure. We analyze the consistency of these representations across different layers of the popular vision foundation model DINOv2 and provide insights into how deep vision models internalize hierarchical category information by increasing information in the class token through each layer. Our study establishes a framework for systematic hierarchical analysis of vision model representations and highlights the potential of SAEs as a tool for probing semantic structure in deep networks.
Learning from Reasoning Failures via Synthetic Data Generation
Apr 20, 2025Training models on synthetic data has emerged as an increasingly important strategy for improving the performance of generative AI. This approach is particularly helpful for large multimodal models (LMMs) due to the relative scarcity of high-quality paired image-text data compared to language-only data. While a variety of methods have been proposed for generating large multimodal datasets, they do not tailor the synthetic data to address specific deficiencies in the reasoning abilities of LMMs which will be trained with the generated dataset. In contrast, humans often learn in a more efficient manner by seeking out examples related to the types of reasoning where they have failed previously. Inspired by this observation, we propose a new approach for synthetic data generation which is grounded in the analysis of an existing LMM's reasoning failures. Our methodology leverages frontier models to automatically analyze errors produced by a weaker LMM and propose new examples which can be used to correct the reasoning failure via additional training, which are then further filtered to ensure high quality. We generate a large multimodal instruction tuning dataset containing over 553k examples using our approach and conduct extensive experiments demonstrating its utility for improving the performance of LMMs on multiple downstream tasks. Our results show that models trained on our synthetic data can even exceed the performance of LMMs trained on an equivalent amount of additional real data, demonstrating the high value of generating synthetic data targeted to specific reasoning failure modes in LMMs. We will make our dataset and code publicly available.
Transformer-Based Temporal Information Extraction and Application: A Review
Apr 10, 2025
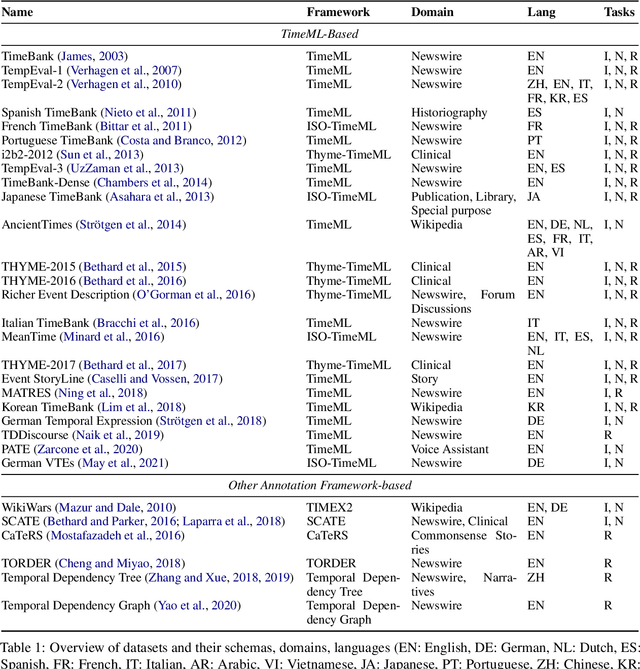
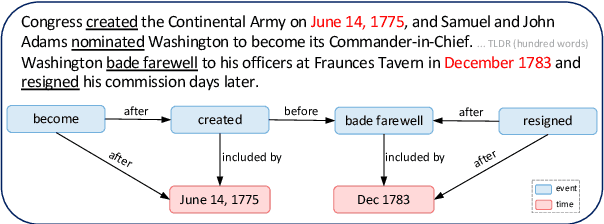
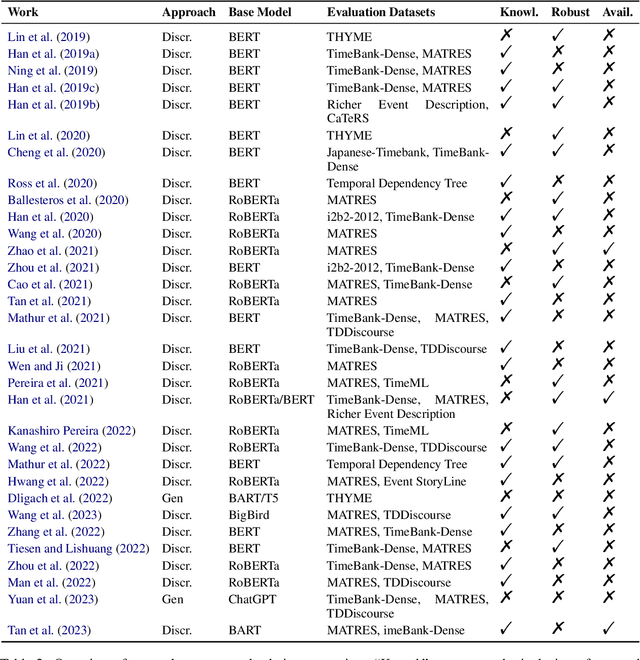
Temporal information extraction (IE) aims to extract structured temporal information from unstructured text, thereby uncovering the implicit timelines within. This technique is applied across domains such as healthcare, newswire, and intelligence analysis, aiding models in these areas to perform temporal reasoning and enabling human users to grasp the temporal structure of text. Transformer-based pre-trained language models have produced revolutionary advancements in natural language processing, demonstrating exceptional performance across a multitude of tasks. Despite the achievements garnered by Transformer-based approaches in temporal IE, there is a lack of comprehensive reviews on these endeavors. In this paper, we aim to bridge this gap by systematically summarizing and analyzing the body of work on temporal IE using Transformers while highlighting potential future research directions.
Quantifying Interpretability in CLIP Models with Concept Consistency
Mar 14, 2025



CLIP is one of the most popular foundational models and is heavily used for many vision-language tasks. However, little is known about the inner workings of CLIP. While recent work has proposed decomposition-based interpretability methods for identifying textual descriptions of attention heads in CLIP, the implications of conceptual consistency in these text labels on interpretability and model performance has not been explored. To bridge this gap, we study the conceptual consistency of text descriptions for attention heads in CLIP-like models. We conduct extensive experiments on six different models from OpenAI and OpenCLIP which vary by size, type of pre-training data and patch size. We propose Concept Consistency Score (CCS), a novel interpretability metric that measures how consistently individual attention heads in CLIP models align with specific concepts. To assign concept labels to heads, we use in-context learning with ChatGPT, guided by a few manually-curated examples, and validate these labels using an LLM-as-a-judge approach. Our soft-pruning experiments reveal that high CCS heads are critical for preserving model performance, as pruning them leads to a significantly larger performance drop than pruning random or low CCS heads. Notably, we find that high CCS heads capture essential concepts and play a key role in out-of-domain detection, concept-specific reasoning, and video-language understanding. These results position CCS as a powerful interpretability metric for analyzing CLIP-like models.