 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the tendency of CNNs to Learn Surface Statistical Regularities
Nov 30, 2017

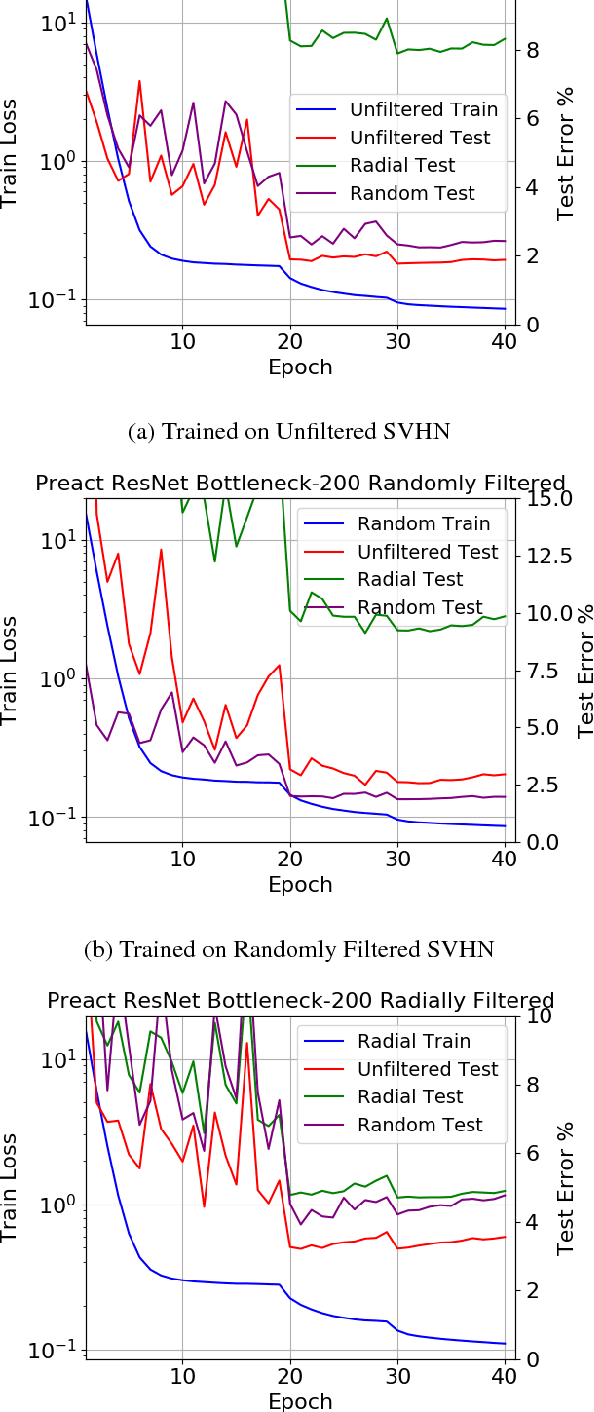
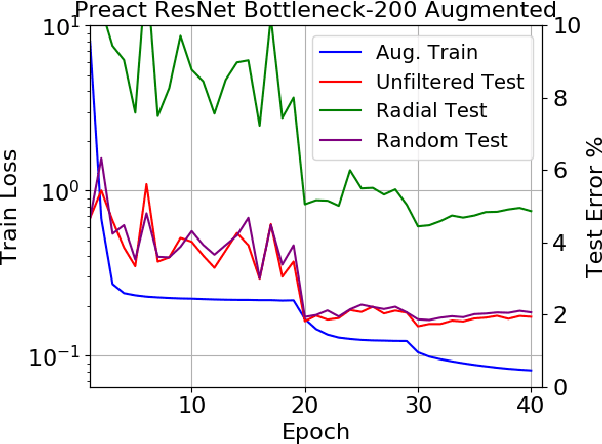
Deep CNNs are known to exhibit the following peculiarity: on the one hand they generalize extremely well to a test set, while on the other hand they are extremely sensitive to so-called adversarial perturbations. The extreme sensitivity of high performance CNNs to adversarial examples casts serious doubt that these networks are learning high level abstractions in the dataset. We are concerned with the following question: How can a deep CNN that does not learn any high level semantics of the dataset manage to generalize so well? The goal of this article is to measure the tendency of CNNs to learn surface statistical regularities of the dataset. To this end, we use Fourier filtering to construct datasets which share the exact same high level abstractions but exhibit qualitatively different surface statistical regularities. For the SVHN and CIFAR-10 datasets, we present two Fourier filtered variants: a low frequency variant and a randomly filtered variant. Each of the Fourier filtering schemes is tuned to preserve the recognizability of the objects. Our main finding is that CNNs exhibit a tendency to latch onto the Fourier image statistics of the training dataset, sometimes exhibiting up to a 28% generalization gap across the various test sets. Moreover, we observe that significantly increasing the depth of a network has a very marginal impact on closing the aforementioned generalization gap. Thus we provide quantitative evidence supporting the hypothesis that deep CNNs tend to learn surface statistical regularities in the dataset rather than higher-level abstract concepts.
Plan, Attend, Generate: Planning for Sequence-to-Sequence Models
Nov 28, 2017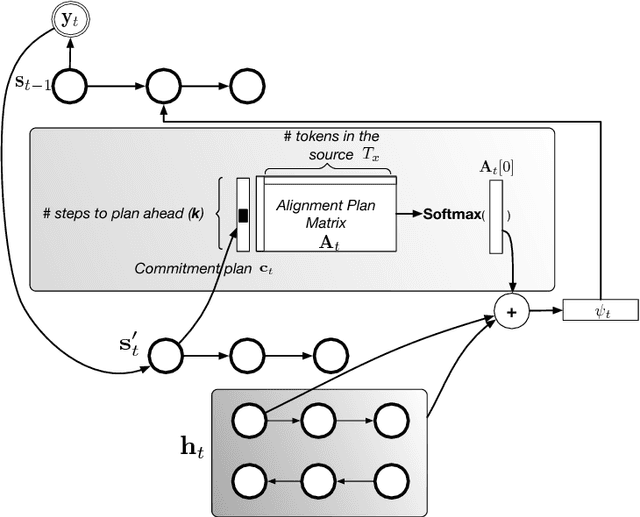
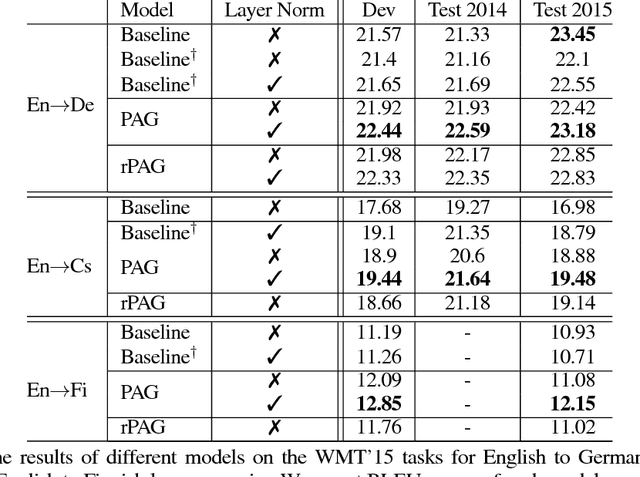

We investigate the integration of a planning mechanism into sequence-to-sequence models using attention. We develop a model which can plan ahead in the future when it computes its alignments between input and output sequences, constructing a matrix of proposed future alignments and a commitment vector that governs whether to follow or recompute the plan. This mechanism is inspired by the recently proposed strategic attentive reader and writer (STRAW) model for Reinforcement Learning. Our proposed model is end-to-end trainable using primarily differentiable operations. We show that it outperforms a strong baseline on character-level translation tasks from WMT'15, the algorithmic task of finding Eulerian circuits of graphs, and question generation from the text. Our analysis demonstrates that the model computes qualitatively intuitive alignments, converges faster than the baselines, and achieves superior performance with fewer parameters.
Z-Forcing: Training Stochastic Recurrent Networks
Nov 16, 2017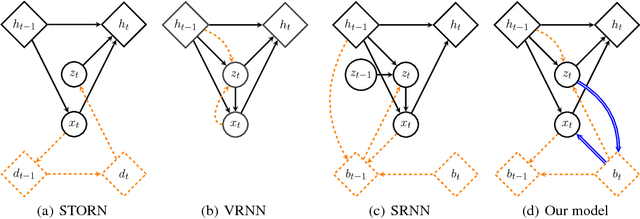
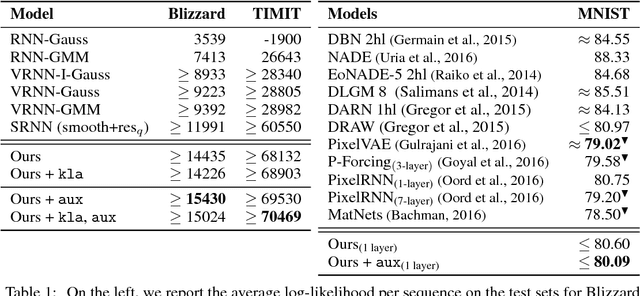

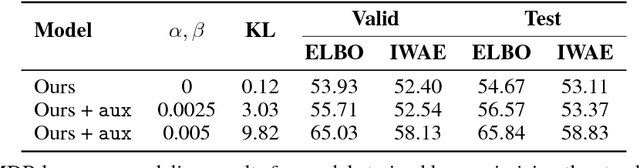
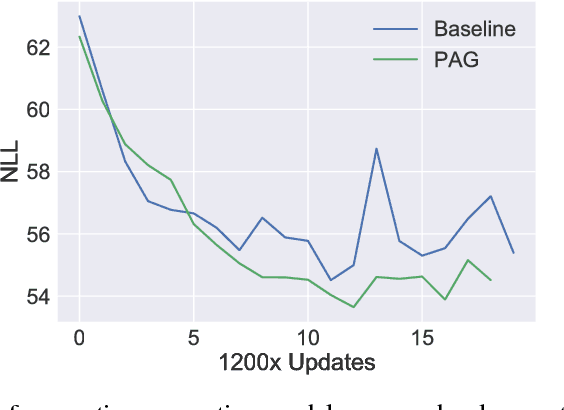
Many efforts have been devoted to training generative latent variable models with autoregressive decoders, such as recurrent neural networks (RNN). Stochastic recurrent models have been successful in capturing the variability observed in natural sequential data such as speech. We unify successful ideas from recently proposed architectures into a stochastic recurrent model: each step in the sequence is associated with a latent variable that is used to condition the recurrent dynamics for future steps. Training is performed with amortized variational inference where the approximate posterior is augmented with a RNN that runs backward through the sequence. In addition to maximizing the variational lower bound, we ease training of the latent variables by adding an auxiliary cost which forces them to reconstruct the state of the backward recurrent network. This provides the latent variables with a task-independent objective that enhances the performance of the overall model. We found this strategy to perform better than alternative approaches such as KL annealing. Although being conceptually simple, our model achieves state-of-the-art results on standard speech benchmarks such as TIMIT and Blizzard and competitive performance on sequential MNIST. Finally, we apply our model to language modeling on the IMDB dataset where the auxiliary cost helps in learning interpretable latent variables. Source Code: \url{https://github.com/anirudh9119/zforcing_nips17}
Variational Bi-LSTMs
Nov 15, 2017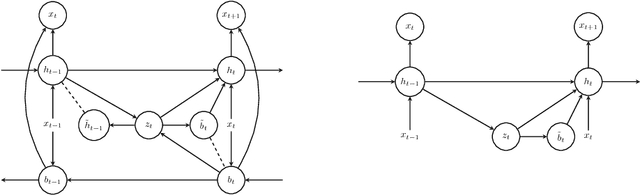
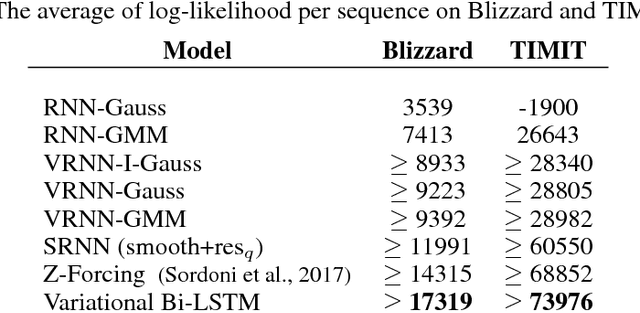
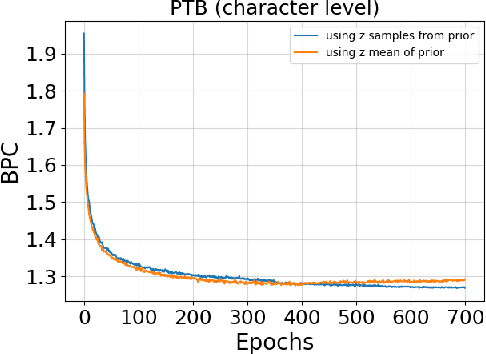
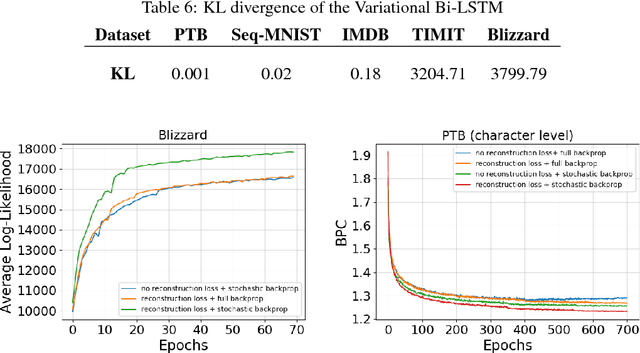
Recurrent neural networks like long short-term memory (LSTM) are important architectures for sequential prediction tasks. LSTMs (and RNNs in general) model sequences along the forward time direction. Bidirectional LSTMs (Bi-LSTMs) on the other hand model sequences along both forward and backward directions and are generally known to perform better at such tasks because they capture a richer representation of the data. In the training of Bi-LSTMs, the forward and backward paths are learned independently. We propose a variant of the Bi-LSTM architecture, which we call Variational Bi-LSTM, that creates a channel between the two paths (during training, but which may be omitted during inference); thus optimizing the two paths jointly. We arrive at this joint objective for our model by minimizing a variational lower bound of the joint likelihood of the data sequence. Our model acts as a regularizer and encourages the two networks to inform each other in making their respective predictions using distinct information. We perform ablation studies to better understand the different components of our model and evaluate the method on various benchmarks, showing state-of-the-art performance.
ACtuAL: Actor-Critic Under Adversarial Learning
Nov 13, 2017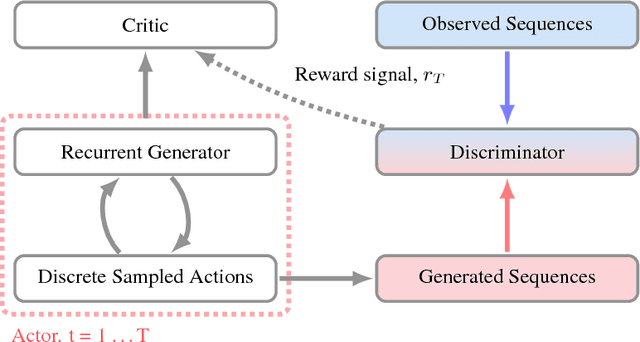
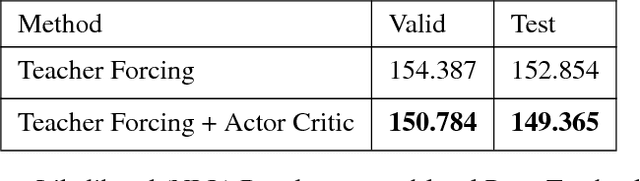
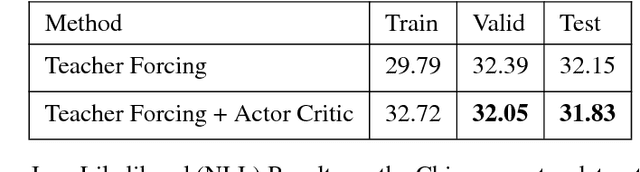

Generative Adversarial Networks (GANs) are a powerful framework for deep generative modeling. Posed as a two-player minimax problem, GANs are typically trained end-to-end on real-valued data and can be used to train a generator of high-dimensional and realistic images. However, a major limitation of GANs is that training relies on passing gradients from the discriminator through the generator via back-propagation. This makes it fundamentally difficult to train GANs with discrete data, as generation in this case typically involves a non-differentiable function. These difficulties extend to the reinforcement learning setting when the action space is composed of discrete decisions. We address these issues by reframing the GAN framework so that the generator is no longer trained using gradients through the discriminator, but is instead trained using a learned critic in the actor-critic framework with a Temporal Difference (TD) objective. This is a natural fit for sequence modeling and we use it to achieve improvements on language modeling tasks over the standard Teacher-Forcing methods.
Sparse Attentive Backtracking: Long-Range Credit Assignment in Recurrent Networks
Nov 07, 2017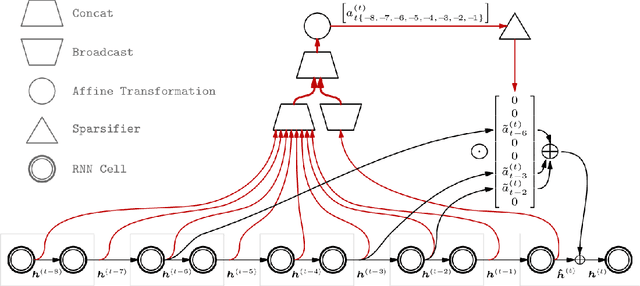
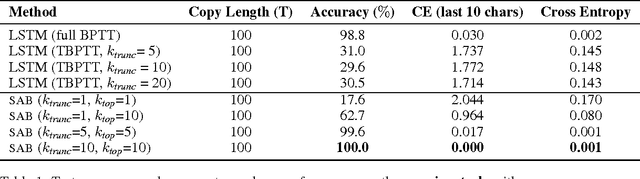
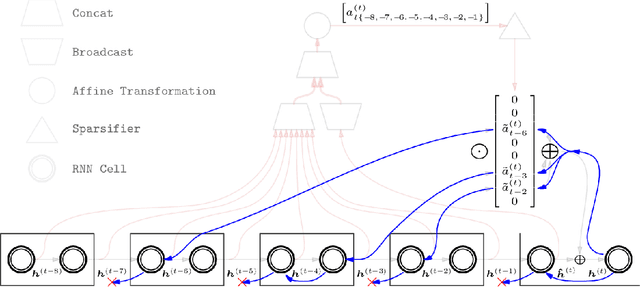
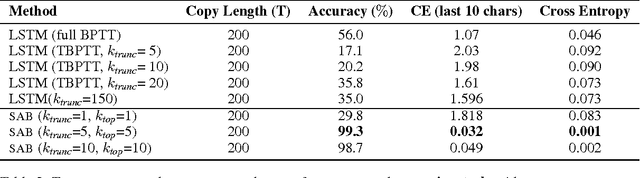
A major drawback of backpropagation through time (BPTT) is the difficulty of learning long-term dependencies, coming from having to propagate credit information backwards through every single step of the forward computation. This makes BPTT both computationally impractical and biologically implausible. For this reason, full backpropagation through time is rarely used on long sequences, and truncated backpropagation through time is used as a heuristic. However, this usually leads to biased estimates of the gradient in which longer term dependencies are ignored. Addressing this issue, we propose an alternative algorithm, Sparse Attentive Backtracking, which might also be related to principles used by brains to learn long-term dependencies. Sparse Attentive Backtracking learns an attention mechanism over the hidden states of the past and selectively backpropagates through paths with high attention weights. This allows the model to learn long term dependencies while only backtracking for a small number of time steps, not just from the recent past but also from attended relevant past states.
Variational Walkback: Learning a Transition Operator as a Stochastic Recurrent Net
Nov 07, 2017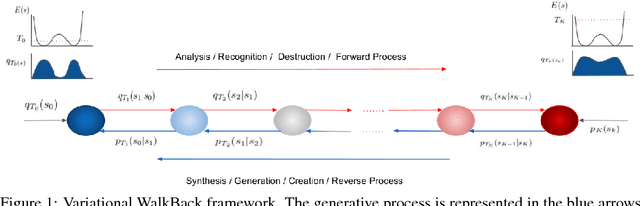

We propose a novel method to directly learn a stochastic transition operator whose repeated application provides generated samples. Traditional undirected graphical models approach this problem indirectly by learning a Markov chain model whose stationary distribution obeys detailed balance with respect to a parameterized energy function. The energy function is then modified so the model and data distributions match, with no guarantee on the number of steps required for the Markov chain to converge. Moreover, the detailed balance condition is highly restrictive: energy based models corresponding to neural networks must have symmetric weights, unlike biological neural circuits. In contrast, we develop a method for directly learning arbitrarily parameterized transition operators capable of expressing non-equilibrium stationary distributions that violate detailed balance, thereby enabling us to learn more biologically plausible asymmetric neural networks and more general non-energy based dynamical systems. The proposed training objective, which we derive via principled variational methods, encourages the transition operator to "walk back" in multi-step trajectories that start at data-points, as quickly as possible back to the original data points. We present a series of experimental results illustrating the soundness of the proposed approach, Variational Walkback (VW), on the MNIST, CIFAR-10, SVHN and CelebA datasets, demonstrating superior samples compared to earlier attempts to learn a transition operator. We also show that although each rapid training trajectory is limited to a finite but variable number of steps, our transition operator continues to generate good samples well past the length of such trajectories, thereby demonstrating the match of its non-equilibrium stationary distribution to the data distribution. Source Code: http://github.com/anirudh9119/walkback_nips17
A Deep Reinforcement Learning Chatbot
Nov 05, 2017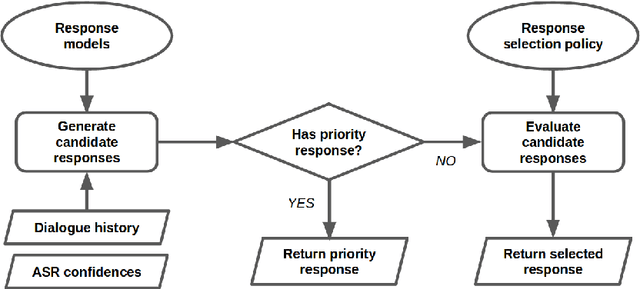
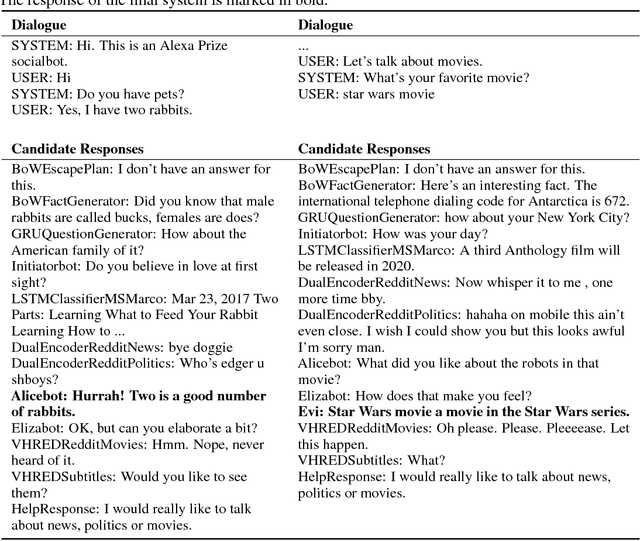
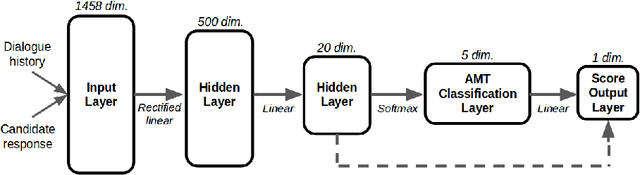

We present MILABOT: a deep reinforcement learning chatbot developed by the Montreal Institute for Learning Algorithms (MILA) for the Amazon Alexa Prize competition. MILABOT is capable of conversing with humans on popular small talk topics through both speech and text. The system consists of an ensemble of natural language generation and retrieval models, including template-based models, bag-of-words models, sequence-to-sequence neural network and latent variable neural network models. By applying reinforcement learning to crowdsourced data and real-world user interactions, the system has been trained to select an appropriate response from the models in its ensemble. The system has been evaluated through A/B testing with real-world users, where it performed significantly better than many competing systems. Due to its machine learning architecture, the system is likely to improve with additional data.
The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation
Oct 31, 2017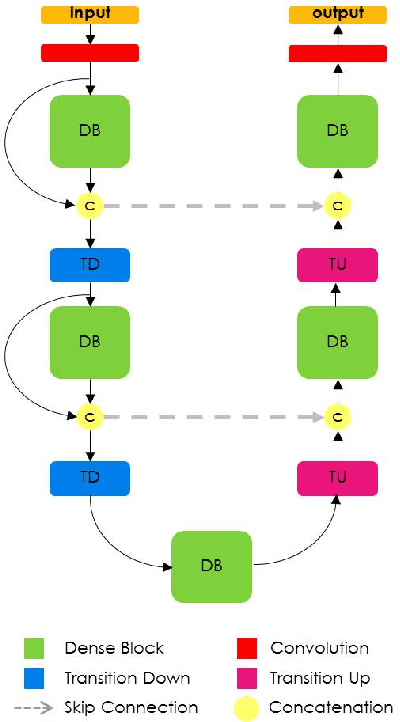

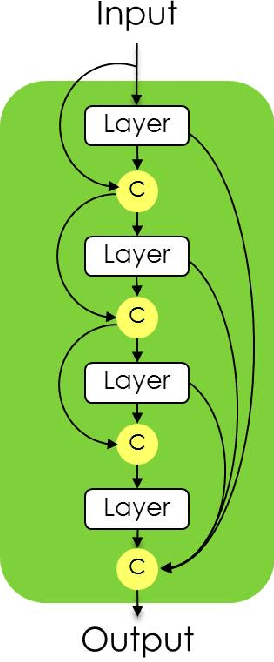

State-of-the-art approaches for semantic image segmentation are built on Convolutional Neural Networks (CNNs). The typical segmentation architecture is composed of (a) a downsampling path responsible for extracting coarse semantic features, followed by (b) an upsampling path trained to recover the input image resolution at the output of the model and, optionally, (c) a post-processing module (e.g. Conditional Random Fields) to refine the model predictions. Recently, a new CNN architecture, Densely Connected Convolutional Networks (DenseNets), has shown excellent results on image classification tasks. The idea of DenseNets is based on the observation that if each layer is directly connected to every other layer in a feed-forward fashion then the network will be more accurate and easier to train. In this paper, we extend DenseNets to deal with the problem of semantic segmentation. We achieve state-of-the-art results on urban scene benchmark datasets such as CamVid and Gatech, without any further post-processing module nor pretraining. Moreover, due to smart construction of the model, our approach has much less parameters than currently published best entries for these datasets. Code to reproduce the experiments is available here : https://github.com/SimJeg/FC-DenseNet/blob/master/train.py
Gated Orthogonal Recurrent Units: On Learning to Forget
Oct 25, 2017We present a novel recurrent neural network (RNN) based model that combines the remembering ability of unitary RNNs with the ability of gated RNNs to effectively forget redundant/irrelevant information in its memory. We achieve this by extending unitary RNNs with a gating mechanism. Our model is able to outperform LSTMs, GRUs and Unitary RNNs on several long-term dependency benchmark tasks. We empirically both show the orthogonal/unitary RNNs lack the ability to forget and also the ability of GORU to simultaneously remember long term dependencies while forgetting irrelevant information. This plays an important role in recurrent neural networks. We provide competitive results along with an analysis of our model on many natural sequential tasks including the bAbI Question Answering, TIMIT speech spectrum prediction, Penn TreeBank, and synthetic tasks that involve long-term dependencies such as algorithmic, parenthesis, denoising and copying tasks.