 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Machine Learning to Robotics: Challenges and Opportunities for Embodied Intelligence
Oct 28, 2021
Machine learning has long since become a keystone technology, accelerating science and applications in a broad range of domains. Consequently, the notion of applying learning methods to a particular problem set has become an established and valuable modus operandi to advance a particular field. In this article we argue that such an approach does not straightforwardly extended to robotics -- or to embodied intelligence more generally: systems which engage in a purposeful exchange of energy and information with a physical environment. In particular, the purview of embodied intelligent agents extends significantly beyond the typical considerations of main-stream machine learning approaches, which typically (i) do not consider operation under conditions significantly different from those encountered during training; (ii) do not consider the often substantial, long-lasting and potentially safety-critical nature of interactions during learning and deployment; (iii) do not require ready adaptation to novel tasks while at the same time (iv) effectively and efficiently curating and extending their models of the world through targeted and deliberate actions. In reality, therefore, these limitations result in learning-based systems which suffer from many of the same operational shortcomings as more traditional, engineering-based approaches when deployed on a robot outside a well defined, and often narrow operating envelope. Contrary to viewing embodied intelligence as another application domain for machine learning, here we argue that it is in fact a key driver for the advancement of machine learning technology. In this article our goal is to highlight challenges and opportunities that are specific to embodied intelligence and to propose research directions which may significantly advance the state-of-the-art in robot learning.
Chunked Autoregressive GAN for Conditional Waveform Synthesis
Oct 19, 2021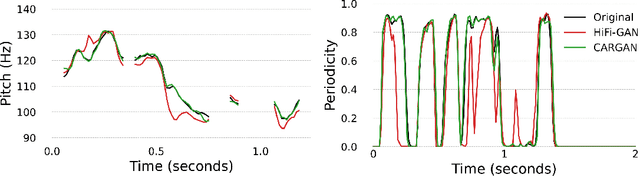

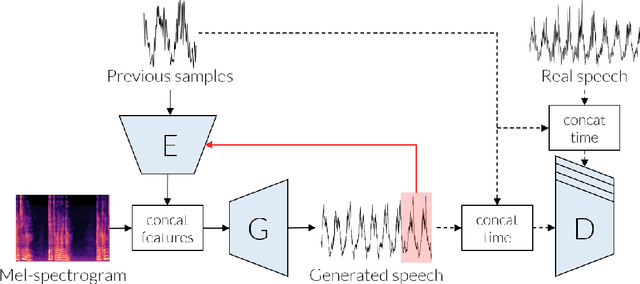
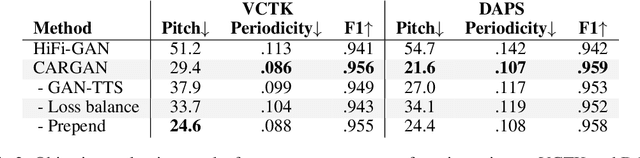
Conditional waveform synthesis models learn a distribution of audio waveforms given conditioning such as text, mel-spectrograms, or MIDI. These systems employ deep generative models that model the waveform via either sequential (autoregressive) or parallel (non-autoregressive) sampling. Generative adversarial networks (GANs) have become a common choice for non-autoregressive waveform synthesis. However, state-of-the-art GAN-based models produce artifacts when performing mel-spectrogram inversion. In this paper, we demonstrate that these artifacts correspond with an inability for the generator to learn accurate pitch and periodicity. We show that simple pitch and periodicity conditioning is insufficient for reducing this error relative to using autoregression. We discuss the inductive bias that autoregression provides for learning the relationship between instantaneous frequency and phase, and show that this inductive bias holds even when autoregressively sampling large chunks of the waveform during each forward pass. Relative to prior state-of- the-art GAN-based models, our proposed model, Chunked Autoregressive GAN (CARGAN) reduces pitch error by 40-60%, reduces training time by 58%, maintains a fast generation speed suitable for real-time or interactive applications, and maintains or improves subjective quality.
Compositional Attention: Disentangling Search and Retrieval
Oct 18, 2021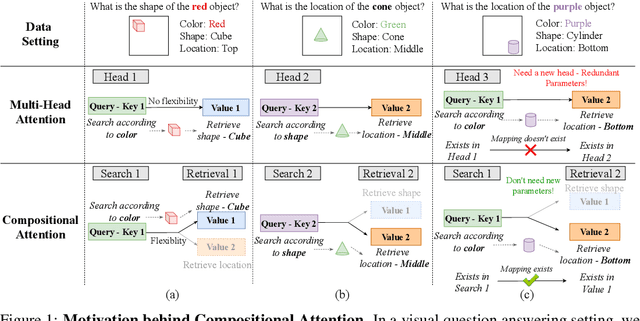
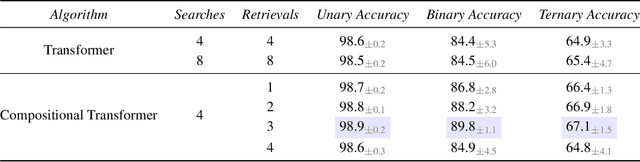
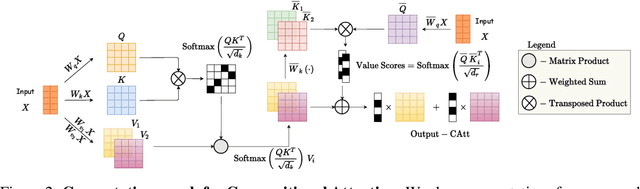

Multi-head, key-value attention is the backbone of the widely successful Transformer model and its variants. This attention mechanism uses multiple parallel key-value attention blocks (called heads), each performing two fundamental computations: (1) search - selection of a relevant entity from a set via query-key interactions, and (2) retrieval - extraction of relevant features from the selected entity via a value matrix. Importantly, standard attention heads learn a rigid mapping between search and retrieval. In this work, we first highlight how this static nature of the pairing can potentially: (a) lead to learning of redundant parameters in certain tasks, and (b) hinder generalization. To alleviate this problem, we propose a novel attention mechanism, called Compositional Attention, that replaces the standard head structure. The proposed mechanism disentangles search and retrieval and composes them in a dynamic, flexible and context-dependent manner through an additional soft competition stage between the query-key combination and value pairing. Through a series of numerical experiments, we show that it outperforms standard multi-head attention on a variety of tasks, including some out-of-distribution settings. Through our qualitative analysis, we demonstrate that Compositional Attention leads to dynamic specialization based on the type of retrieval needed. Our proposed mechanism generalizes multi-head attention, allows independent scaling of search and retrieval, and can easily be implemented in lieu of standard attention heads in any network architecture.
Graph Neural Networks with Learnable Structural and Positional Representations
Oct 15, 2021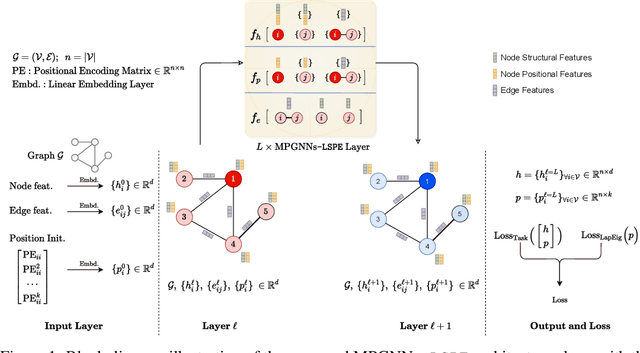
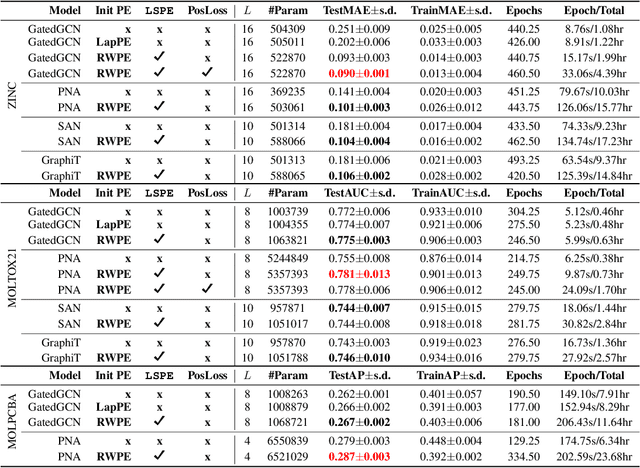
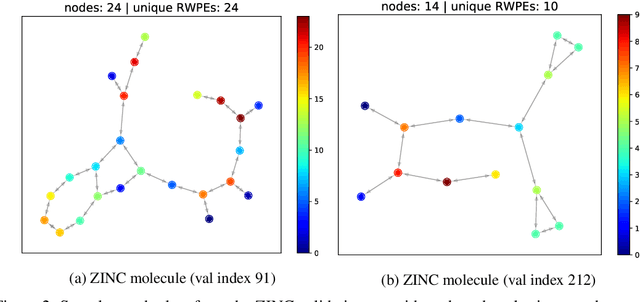
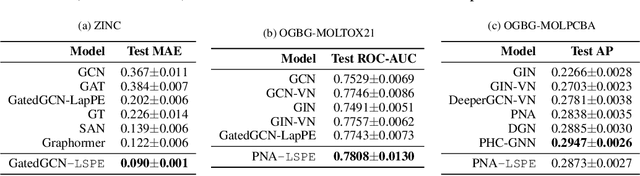
Graph neural networks (GNNs) have become the standard learning architectures for graphs. GNNs have been applied to numerous domains ranging from quantum chemistry, recommender systems to knowledge graphs and natural language processing. A major issue with arbitrary graphs is the absence of canonical positional information of nodes, which decreases the representation power of GNNs to distinguish e.g. isomorphic nodes and other graph symmetries. An approach to tackle this issue is to introduce Positional Encoding (PE) of nodes, and inject it into the input layer, like in Transformers. Possible graph PE are Laplacian eigenvectors. In this work, we propose to decouple structural and positional representations to make easy for the network to learn these two essential properties. We introduce a novel generic architecture which we call LSPE (Learnable Structural and Positional Encodings). We investigate several sparse and fully-connected (Transformer-like) GNNs, and observe a performance increase for molecular datasets, from 2.87% up to 64.14% when considering learnable PE for both GNN classes.
Dynamic Inference with Neural Interpreters
Oct 12, 2021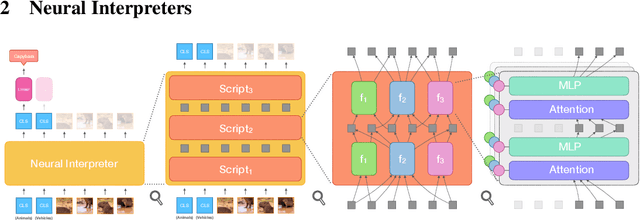
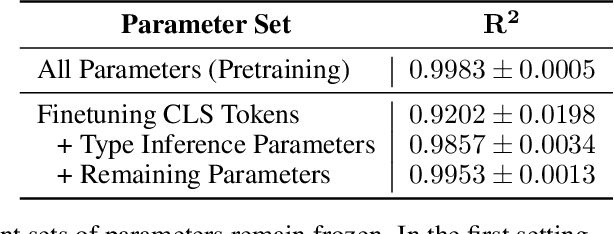
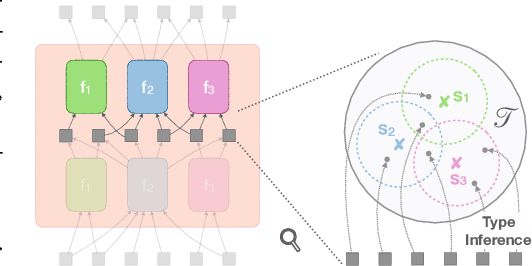
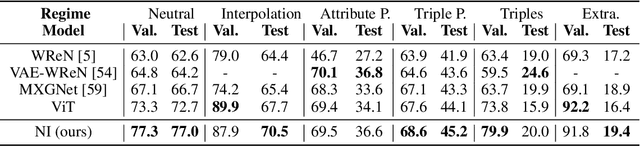
Modern neural network architectures can leverage large amounts of data to generalize well within the training distribution. However, they are less capable of systematic generalization to data drawn from unseen but related distributions, a feat that is hypothesized to require compositional reasoning and reuse of knowledge. In this work, we present Neural Interpreters, an architecture that factorizes inference in a self-attention network as a system of modules, which we call \emph{functions}. Inputs to the model are routed through a sequence of functions in a way that is end-to-end learned. The proposed architecture can flexibly compose computation along width and depth, and lends itself well to capacity extension after training. To demonstrate the versatility of Neural Interpreters, we evaluate it in two distinct settings: image classification and visual abstract reasoning on Raven Progressive Matrices. In the former, we show that Neural Interpreters perform on par with the vision transformer using fewer parameters, while being transferrable to a new task in a sample efficient manner. In the latter, we find that Neural Interpreters are competitive with respect to the state-of-the-art in terms of systematic generalization
ClimateGAN: Raising Climate Change Awareness by Generating Images of Floods
Oct 06, 2021
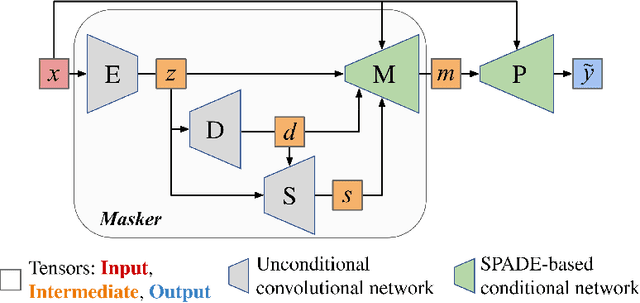

Climate change is a major threat to humanity, and the actions required to prevent its catastrophic consequences include changes in both policy-making and individual behaviour. However, taking action requires understanding the effects of climate change, even though they may seem abstract and distant. Projecting the potential consequences of extreme climate events such as flooding in familiar places can help make the abstract impacts of climate change more concrete and encourage action. As part of a larger initiative to build a website that projects extreme climate events onto user-chosen photos, we present our solution to simulate photo-realistic floods on authentic images. To address this complex task in the absence of suitable training data, we propose ClimateGAN, a model that leverages both simulated and real data for unsupervised domain adaptation and conditional image generation. In this paper, we describe the details of our framework, thoroughly evaluate components of our architecture and demonstrate that our model is capable of robustly generating photo-realistic flooding.
Unifying Likelihood-free Inference with Black-box Sequence Design and Beyond
Oct 06, 2021
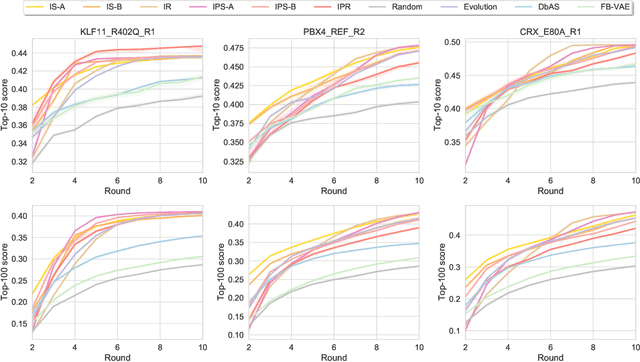

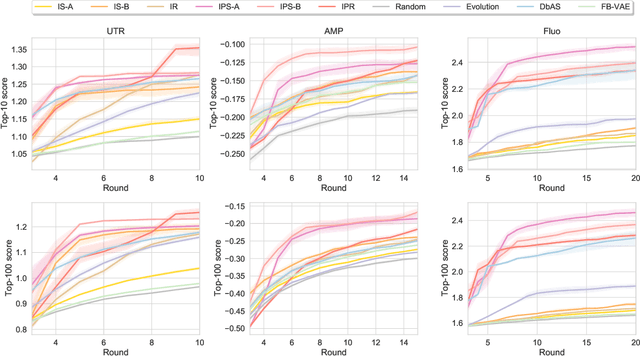
Black-box optimization formulations for biological sequence design have drawn recent attention due to their promising potential impact on the pharmaceutical industry. In this work, we propose to unify two seemingly distinct worlds: likelihood-free inference and black-box sequence design, under one probabilistic framework. In tandem, we provide a recipe for constructing various sequence design methods based on this framework. We show how previous drug discovery approaches can be "reinvented" in our framework, and further propose new probabilistic sequence design algorithms. Extensive experiments illustrate the benefits of the proposed methodology.
Learning Neural Causal Models with Active Interventions
Sep 06, 2021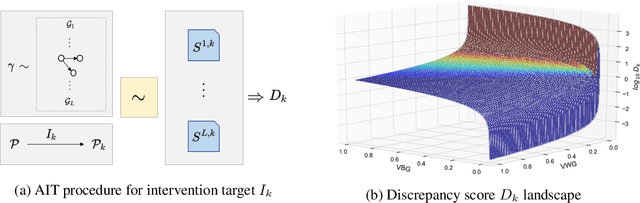
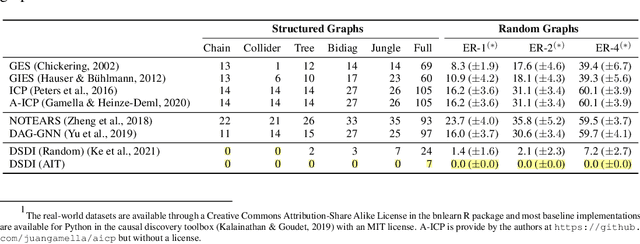
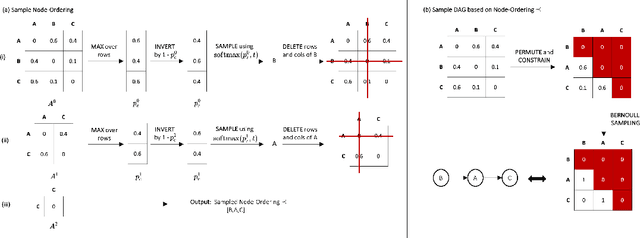
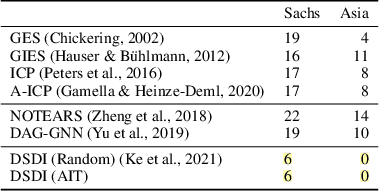
Discovering causal structures from data is a challenging inference problem of fundamental importance in all areas of science. The appealing scaling properties of neural networks have recently led to a surge of interest in differentiable neural network-based methods for learning causal structures from data. So far differentiable causal discovery has focused on static datasets of observational or interventional origin. In this work, we introduce an active intervention-targeting mechanism which enables a quick identification of the underlying causal structure of the data-generating process. Our method significantly reduces the required number of interactions compared with random intervention targeting and is applicable for both discrete and continuous optimization formulations of learning the underlying directed acyclic graph (DAG) from data. We examine the proposed method across a wide range of settings and demonstrate superior performance on multiple benchmarks from simulated to real-world data.
The Causal-Neural Connection: Expressiveness, Learnability, and Inference
Jul 14, 2021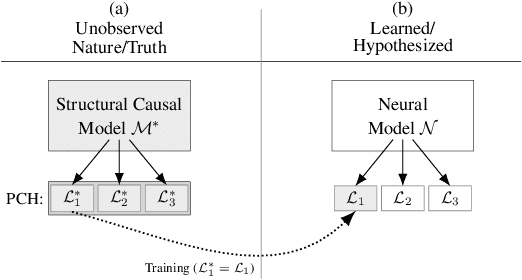
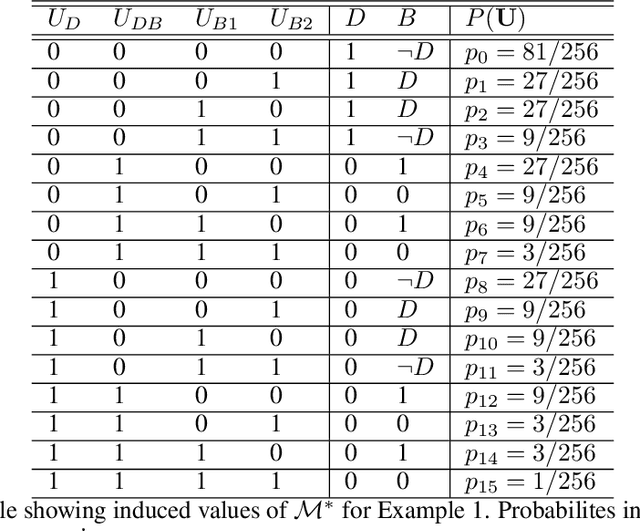
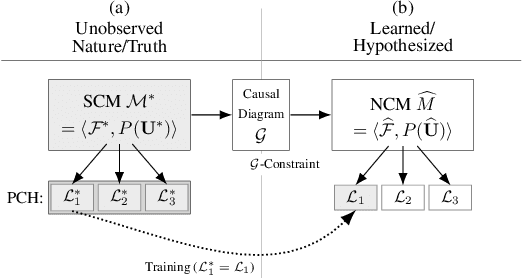
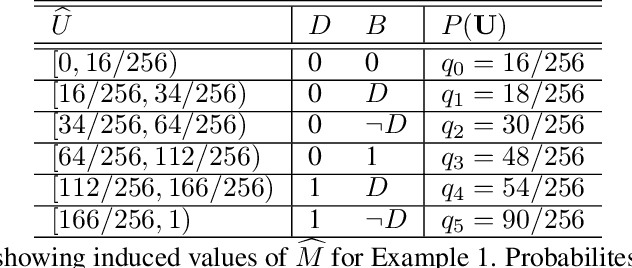
One of the central elements of any causal inference is an object called structural causal model (SCM), which represents a collection of mechanisms and exogenous sources of random variation of the system under investigation (Pearl, 2000). An important property of many kinds of neural networks is universal approximability: the ability to approximate any function to arbitrary precision. Given this property, one may be tempted to surmise that a collection of neural nets is capable of learning any SCM by training on data generated by that SCM. In this paper, we show this is not the case by disentangling the notions of expressivity and learnability. Specifically, we show that the causal hierarchy theorem (Thm. 1, Bareinboim et al., 2020), which describes the limits of what can be learned from data, still holds for neural models. For instance, an arbitrarily complex and expressive neural net is unable to predict the effects of interventions given observational data alone. Given this result, we introduce a special type of SCM called a neural causal model (NCM), and formalize a new type of inductive bias to encode structural constraints necessary for performing causal inferences. Building on this new class of models, we focus on solving two canonical tasks found in the literature known as causal identification and estimation. Leveraging the neural toolbox, we develop an algorithm that is both sufficient and necessary to determine whether a causal effect can be learned from data (i.e., causal identifiability); it then estimates the effect whenever identifiability holds (causal estimation). Simulations corroborate the proposed approach.
Discrete-Valued Neural Communication
Jul 10, 2021

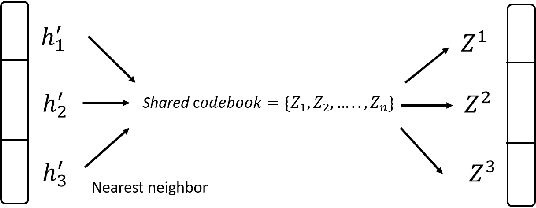
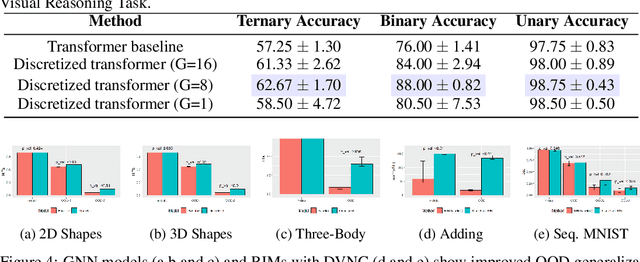
Deep learning has advanced from fully connected architectures to structured models organized into components, e.g., the transformer composed of positional elements, modular architectures divided into slots, and graph neural nets made up of nodes. In structured models, an interesting question is how to conduct dynamic and possibly sparse communication among the separate components. Here, we explore the hypothesis that restricting the transmitted information among components to discrete representations is a beneficial bottleneck. The motivating intuition is human language in which communication occurs through discrete symbols. Even though individuals have different understandings of what a "cat" is based on their specific experiences, the shared discrete token makes it possible for communication among individuals to be unimpeded by individual differences in internal representation. To discretize the values of concepts dynamically communicated among specialist components, we extend the quantization mechanism from the Vector-Quantized Variational Autoencoder to multi-headed discretization with shared codebooks and use it for discrete-valued neural communication (DVNC). Our experiments show that DVNC substantially improves systematic generalization in a variety of architectures -- transformers, modular architectures, and graph neural networks. We also show that the DVNC is robust to the choice of hyperparameters, making the method very useful in practice. Moreover, we establish a theoretical justification of our discretization process, proving that it has the ability to increase noise robustness and reduce the underlying dimensionality of the model.