 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2Restore: Mixture-of-Experts-based Mamba-CNN Fusion Framework for All-in-One Image Restoration
Jun 09, 2025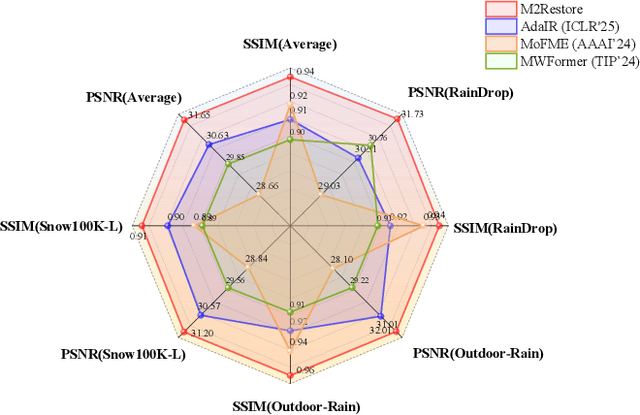
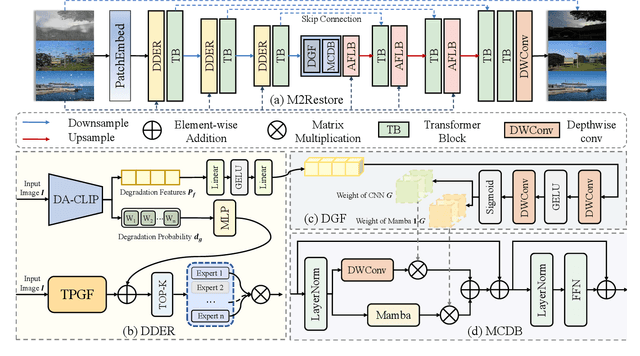
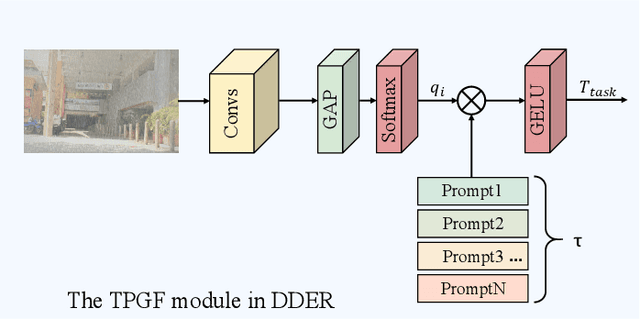

Natural images are often degraded by complex, composite degradations such as rain, snow, and haze, which adversely impact downstream vision applications. While existing image restoration efforts have achieved notable success, they are still hindered by two critical challenges: limited generalization across dynamically varying degradation scenarios and a suboptimal balance between preserving local details and modeling global dependencies. To overcome these challenges, we propose M2Restore, a novel Mixture-of-Experts (MoE)-based Mamba-CNN fusion framework for efficient and robust all-in-one image restoration. M2Restore introduces three key contributions: First, to boost the model's generalization across diverse degradation conditions, we exploit a CLIP-guided MoE gating mechanism that fuses task-conditioned prompts with CLIP-derived semantic priors. This mechanism is further refined via cross-modal feature calibration, which enables precise expert selection for various degradation types. Second, to jointly capture global contextual dependencies and fine-grained local details, we design a dual-stream architecture that integrates the localized representational strength of CNNs with the long-range modeling efficiency of Mamba. This integration enables collaborative optimization of global semantic relationships and local structural fidelity, preserving global coherence while enhancing detail restoration. Third, we introduce an edge-aware dynamic gating mechanism that adaptively balances global modeling and local enhancement by reallocating computational attention to degradation-sensitive regions. This targeted focus leads to more efficient and precise restoration. Extensive experiments across multiple image restoration benchmarks validate the superiority of M2Restore in both visual quality and quantitative performance.
WDMamba: When Wavelet Degradation Prior Meets Vision Mamba for Image Dehazing
May 07, 2025In this paper, we reveal a novel haze-specific wavelet degradation prior observed through wavelet transform analysis, which shows that haze-related information predominantly resides in low-frequency components. Exploiting this insight, we propose a novel dehazing framework, WDMamba, which decomposes the image dehazing task into two sequential stages: low-frequency restoration followed by detail enhancement. This coarse-to-fine strategy enables WDMamba to effectively capture features specific to each stage of the dehazing process, resulting in high-quality restored images. Specifically, in the low-frequency restoration stage, we integrate Mamba blocks to reconstruct global structures with linear complexity, efficiently removing overall haze and producing a coarse restored image. Thereafter, the detail enhancement stage reinstates fine-grained information that may have been overlooked during the previous phase, culminating in the final dehazed output. Furthermore, to enhance detail retention and achieve more natural dehazing, we introduce a self-guided contrastive regularization during network training. By utilizing the coarse restored output as a hard negative example, our model learns more discriminative representations, substantially boosting the overall dehazing performance. Extensive evaluations on public dehazing benchmarks demonstrate that our method surpasses state-of-the-art approaches both qualitatively and quantitatively. Code is available at https://github.com/SunJ000/WDMamba.
DA2Diff: Exploring Degradation-aware Adaptive Diffusion Priors for All-in-One Weather Restoration
Apr 07, 2025



Image restoration under adverse weather conditions is a critical task for many vision-based applications. Recent all-in-one frameworks that handle multiple weather degradations within a unified model have shown potential. However, the diversity of degradation patterns across different weather conditions, as well as the complex and varied nature of real-world degradations, pose significant challenges for multiple weather removal. To address these challenges, we propose an innovative diffusion paradigm with degradation-aware adaptive priors for all-in-one weather restoration, termed DA2Diff. It is a new exploration that applies CLIP to perceive degradation-aware properties for better multi-weather restoration. Specifically, we deploy a set of learnable prompts to capture degradation-aware representations by the prompt-image similarity constraints in the CLIP space. By aligning the snowy/hazy/rainy images with snow/haze/rain prompts, each prompt contributes to different weather degradation characteristics. The learned prompts are then integrated into the diffusion model via the designed weather specific prompt guidance module, making it possible to restore multiple weather types. To further improve the adaptiveness to complex weather degradations, we propose a dynamic expert selection modulator that employs a dynamic weather-aware router to flexibly dispatch varying numbers of restoration experts for each weather-distorted image, allowing the diffusion model to restore diverse degradations adaptively. Experimental results substantiate the favorable performance of DA2Diff over state-of-the-arts in quantitative and qualitative evaluation. Source code will be available after acceptance.
RSHazeDiff: A Unified Fourier-aware Diffusion Model for Remote Sensing Image Dehazing
May 15, 2024



Haze severely degrades the visual quality of remote sensing images and hampers the performance of automotive navigation, intelligent monitoring, and urban management. The emerging denoising diffusion probabilistic model (DDPM) exhibits the significant potential for dense haze removal with its strong generation ability. Since remote sensing images contain extensive small-scale texture structures, it is important to effectively restore image details from hazy images. However, current wisdom of DDPM fails to preserve image details and color fidelity well, limiting its dehazing capacity for remote sensing images. In this paper, we propose a novel unified Fourier-aware diffusion model for remote sensing image dehazing, termed RSHazeDiff. From a new perspective, RSHazeDiff explores the conditional DDPM to improve image quality in dense hazy scenarios, and it makes three key contributions. First, RSHazeDiff refines the training phase of diffusion process by performing noise estimation and reconstruction constraints in a coarse-to-fine fashion. Thus, it remedies the unpleasing results caused by the simple noise estimation constraint in DDPM. Second, by taking the frequency information as important prior knowledge during iterative sampling steps, RSHazeDiff can preserve more texture details and color fidelity in dehazed images. Third, we design a global compensated learning module to utilize the Fourier transform to capture the global dependency features of input images, which can effectively mitigate the effects of boundary artifacts when processing fixed-size patches. Experiments on both synthetic and real-world benchmarks validate the favorable performance of RSHazeDiff over multiple state-of-the-art methods. Source code will be released at https://github.com/jm-xiong/RSHazeDiff.
FriendNet: Detection-Friendly Dehazing Network
Mar 07, 2024



Adverse weather conditions often impair the quality of captured images, inevitably inducing cutting-edge object detection models for advanced driver assistance systems (ADAS) and autonomous driving. In this paper, we raise an intriguing question: can the combination of image restoration and object detection enhance detection performance in adverse weather conditions? To answer it, we propose an effective architecture that bridges image dehazing and object detection together via guidance information and task-driven learning to achieve detection-friendly dehazing, termed FriendNet. FriendNet aims to deliver both high-quality perception and high detection capacity. Different from existing efforts that intuitively treat image dehazing as pre-processing, FriendNet establishes a positive correlation between these two tasks. Clean features generated by the dehazing network potentially contribute to improvements in object detection performance. Conversely, object detection crucially guides the learning process of the image dehazing network under the task-driven learning scheme. We shed light on how downstream tasks can guide upstream dehazing processes, considering both network architecture and learning objectives. We design Guidance Fusion Block (GFB) and Guidance Attention Block (GAB) to facilitate the integration of detection information into the network. Furthermore, the incorporation of the detection task loss aids in refining the optimization process. Additionally, we introduce a new Physics-aware Feature Enhancement Block (PFEB), which integrates physics-based priors to enhance the feature extraction and representation capabilities. Extensive experiments on synthetic and real-world datasets demonstrate the superiority of our method over state-of-the-art methods on both image quality and detection precision. Our source code is available at https://github.com/fanyihua0309/FriendNet.
Knowledge Pyramid: A Novel Hierarchical Reasoning Structure for Generalized Knowledge Augmentation and Inference
Jan 17, 2024Knowledge graph (KG) based reasoning has been regarded as an effective means for the analysis of semantic networks and is of great usefulness in areas of information retrieval, recommendation, decision-making, and man-machine interaction. It is widely used in recommendation, decision-making, question-answering, search, and other fields. However, previous studies mainly used low-level knowledge in the KG for reasoning, which may result in insufficient generalization and poor robustness of reasoning. To this end, this paper proposes a new inference approach using a novel knowledge augmentation strategy to improve the generalization capability of KG. This framework extracts high-level pyramidal knowledge from low-level knowledge and applies it to reasoning in a multi-level hierarchical KG, called knowledge pyramid in this paper. We tested some medical data sets using the proposed approach, and the experimental results show that the proposed knowledge pyramid has improved the knowledge inference performance with better generalization. Especially, when there are fewer training samples, the inference accuracy can be significantly improved.
Uncertainty-Driven Multi-Scale Feature Fusion Network for Real-time Image Deraining
Jul 19, 2023



Visual-based measurement systems are frequently affected by rainy weather due to the degradation caused by rain streaks in captured images, and existing imaging devices struggle to address this issue in real-time. While most efforts leverage deep networks for image deraining and have made progress, their large parameter sizes hinder deployment on resource-constrained devices. Additionally, these data-driven models often produce deterministic results, without considering their inherent epistemic uncertainty, which can lead to undesired reconstruction errors. Well-calibrated uncertainty can help alleviate prediction errors and assist measurement devices in mitigating risks and improving usability. Therefore, we propose an Uncertainty-Driven Multi-Scale Feature Fusion Network (UMFFNet) that learns the probability mapping distribution between paired images to estimate uncertainty. Specifically, we introduce an uncertainty feature fusion block (UFFB) that utilizes uncertainty information to dynamically enhance acquired features and focus on blurry regions obscured by rain streaks, reducing prediction errors. In addition, to further boost the performance of UMFFNet, we fused feature information from multiple scales to guide the network for efficient collaborative rain removal. Extensive experiments demonstrate that UMFFNet achieves significant performance improvements with few parameters, surpassing state-of-the-art image deraining methods.
Joint Depth Estimation and Mixture of Rain Removal From a Single Image
Mar 31, 2023



Rainy weather significantly deteriorates the visibility of scene objects, particularly when images are captured through outdoor camera lenses or windshields. Through careful observation of numerous rainy photos, we have found that the images are generally affected by various rainwater artifacts such as raindrops, rain streaks, and rainy haze, which impact the image quality from both near and far distances, resulting in a complex and intertwined process of image degradation. However, current deraining techniques are limited in their ability to address only one or two types of rainwater, which poses a challenge in removing the mixture of rain (MOR). In this study, we propose an effective image deraining paradigm for Mixture of rain REmoval, called DEMore-Net, which takes full account of the MOR effect. Going beyond the existing deraining wisdom, DEMore-Net is a joint learning paradigm that integrates depth estimation and MOR removal tasks to achieve superior rain removal. The depth information can offer additional meaningful guidance information based on distance, thus better helping DEMore-Net remove different types of rainwater. Moreover, this study explores normalization approaches in image deraining tasks and introduces a new Hybrid Normalization Block (HNB) to enhance the deraining performance of DEMore-Net. Extensive experiments conducted on synthetic datasets and real-world MOR photos fully validate the superiority of the proposed DEMore-Net. Code is available at https://github.com/yz-wang/DEMore-Net.
RainDiffusion:When Unsupervised Learning Meets Diffusion Models for Real-world Image Deraining
Jan 23, 2023



What will happen when unsupervised learning meets diffusion models for real-world image deraining? To answer it, we propose RainDiffusion, the first unsupervised image deraining paradigm based on diffusion models. Beyond the traditional unsupervised wisdom of image deraining, RainDiffusion introduces stable training of unpaired real-world data instead of weakly adversarial training. RainDiffusion consists of two cooperative branches: Non-diffusive Translation Branch (NTB) and Diffusive Translation Branch (DTB). NTB exploits a cycle-consistent architecture to bypass the difficulty in unpaired training of standard diffusion models by generating initial clean/rainy image pairs. DTB leverages two conditional diffusion modules to progressively refine the desired output with initial image pairs and diffusive generative prior, to obtain a better generalization ability of deraining and rain generation. Rain-Diffusion is a non adversarial training paradigm, serving as a new standard bar for real-world image deraining. Extensive experiments confirm the superiority of our RainDiffusion over un/semi-supervised methods and show its competitive advantages over fully-supervised ones.
iSmallNet: Densely Nested Network with Label Decoupling for Infrared Small Target Detection
Oct 29, 2022



Small targets are often submerged in cluttered backgrounds of infrared images. Conventional detectors tend to generate false alarms, while CNN-based detectors lose small targets in deep layers. To this end, we propose iSmallNet, a multi-stream densely nested network with label decoupling for infrared small object detection. On the one hand, to fully exploit the shape information of small targets, we decouple the original labeled ground-truth (GT) map into an interior map and a boundary one. The GT map, in collaboration with the two additional maps, tackles the unbalanced distribution of small object boundaries. On the other hand, two key modules are delicately designed and incorporated into the proposed network to boost the overall performance. First, to maintain small targets in deep layers, we develop a multi-scale nested interaction module to explore a wide range of context information. Second, we develop an interior-boundary fusion module to integrate multi-granularity information. Experiments on NUAA-SIRST and NUDT-SIRST clearly show the superiority of iSmallNet over 11 state-of-the-art detectors.