 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Stega: Semantic Controllable Steganographic Text Generation Guided by Knowledge Graph
Jun 02, 2020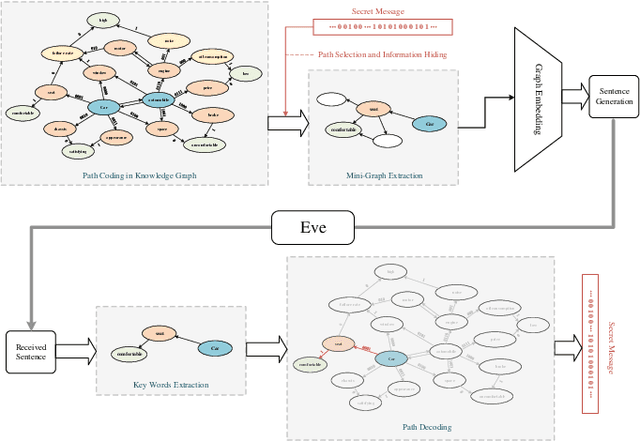
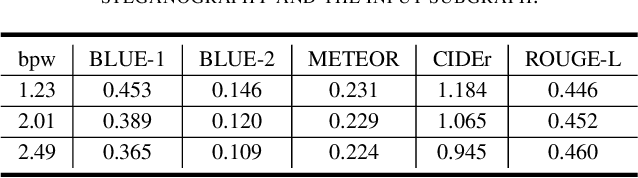
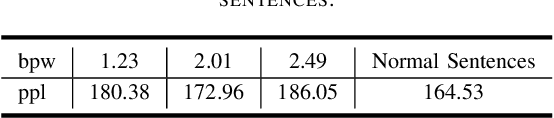

Most of the existing text generative steganographic methods are based on coding the conditional probability distribution of each word during the generation process, and then selecting specific words according to the secret information, so as to achieve information hiding. Such methods have their limitations which may bring potential security risks. Firstly, with the increase of embedding rate, these models will choose words with lower conditional probability, which will reduce the quality of the generated steganographic texts; secondly, they can not control the semantic expression of the final generated steganographic text. This paper proposes a new text generative steganography method which is quietly different from the existing models. We use a Knowledge Graph (KG) to guide the generation of steganographic sentences. On the one hand, we hide the secret information by coding the path in the knowledge graph, but not the conditional probability of each generated word; on the other hand, we can control the semantic expression of the generated steganographic text to a certain extent. The experimental results show that the proposed model can guarantee both the quality of the generated text and its semantic expression, which is a supplement and improvement to the current text generation steganography.
Graph Enhanced Representation Learning for News Recommendation
Mar 31, 2020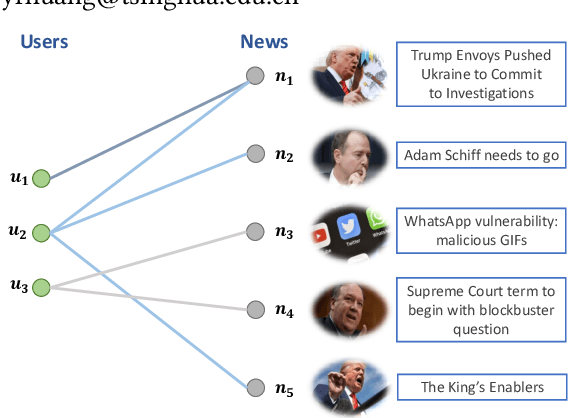
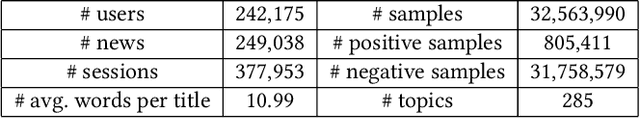
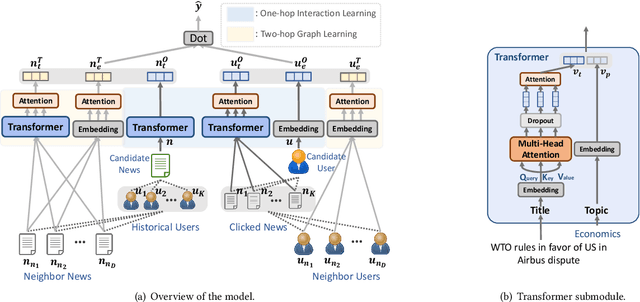
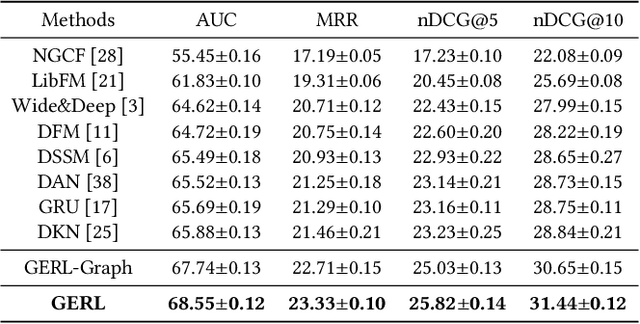
With the explosion of online news, personalized news recommendation becomes increasingly important for online news platforms to help their users find interesting information. Existing news recommendation methods achieve personalization by building accurate news representations from news content and user representations from their direct interactions with news (e.g., click), while ignoring the high-order relatedness between users and news. Here we propose a news recommendation method which can enhance the representation learning of users and news by modeling their relatedness in a graph setting. In our method, users and news are both viewed as nodes in a bipartite graph constructed from historical user click behaviors. For news representations, a transformer architecture is first exploited to build news semantic representations. Then we combine it with the information from neighbor news in the graph via a graph attention network. For user representations, we not only represent users from their historically clicked news, but also attentively incorporate the representations of their neighbor users in the graph. Improved performances on a large-scale real-world dataset validate the effectiveness of our proposed method.
FedNER: Privacy-preserving Medical Named Entity Recognition with Federated Learning
Mar 25, 2020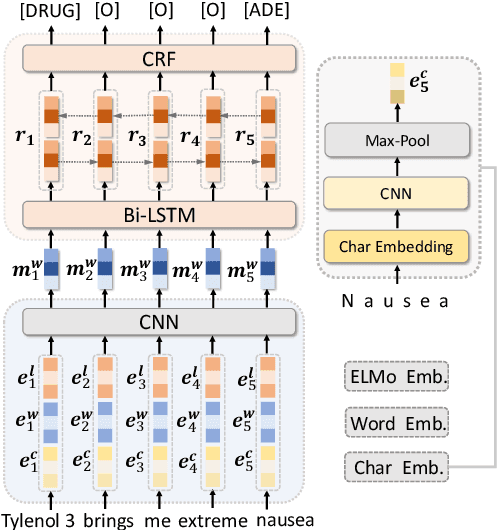
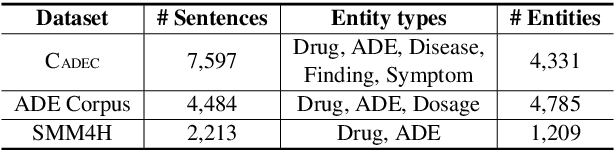
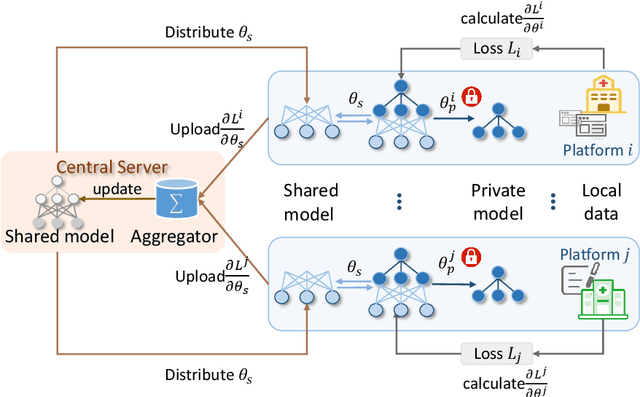
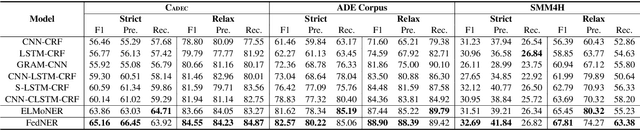
Medical named entity recognition (NER) has wide applications in intelligent healthcare. Sufficient labeled data is critical for training accurate medical NER model. However, the labeled data in a single medical platform is usually limited. Although labeled datasets may exist in many different medical platforms, they cannot be directly shared since medical data is highly privacy-sensitive. In this paper, we propose a privacy-preserving medical NER method based on federated learning, which can leverage the labeled data in different platforms to boost the training of medical NER model and remove the need of exchanging raw data among different platforms. Since the labeled data in different platforms usually has some differences in entity type and annotation criteria, instead of constraining different platforms to share the same model, we decompose the medical NER model in each platform into a shared module and a private module. The private module is used to capture the characteristics of the local data in each platform, and is updated using local labeled data. The shared module is learned across different medical platform to capture the shared NER knowledge. Its local gradients from different platforms are aggregated to update the global shared module, which is further delivered to each platform to update their local shared modules. Experiments on three publicly available datasets validate the effectiveness of our method.
IStego100K: Large-scale Image Steganalysis Dataset
Nov 13, 2019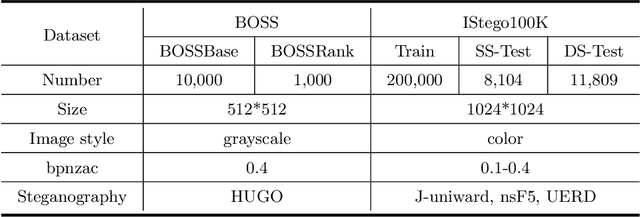

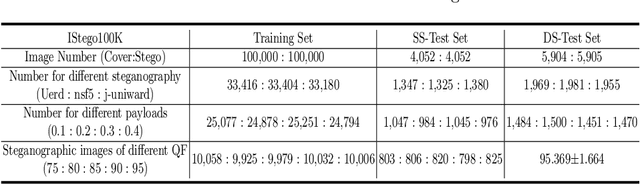
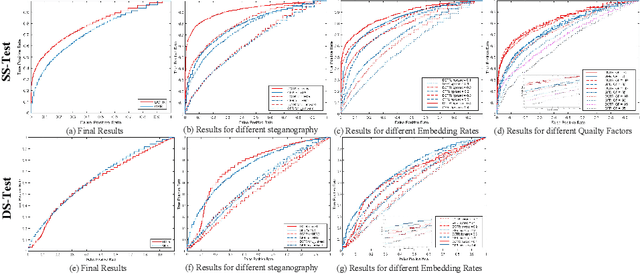
In order to promote the rapid development of image steganalysis technology, in this paper, we construct and release a multivariable large-scale image steganalysis dataset called IStego100K. It contains 208,104 images with the same size of 1024*1024. Among them, 200,000 images (100,000 cover-stego image pairs) are divided as the training set and the remaining 8,104 as testing set. In addition, we hope that IStego100K can help researchers further explore the development of universal image steganalysis algorithms, so we try to reduce limits on the images in IStego100K. For each image in IStego100K, the quality factors is randomly set in the range of 75-95, the steganographic algorithm is randomly selected from three well-known steganographic algorithms, which are J-uniward, nsF5 and UERD, and the embedding rate is also randomly set to be a value of 0.1-0.4. In addition, considering the possible mismatch between training samples and test samples in real environment, we add a test set (DS-Test) whose source of samples are different from the training set. We hope that this test set can help to evaluate the robustness of steganalysis algorithms. We tested the performance of some latest steganalysis algorithms on IStego100K, with specific results and analysis details in the experimental part. We hope that the IStego100K dataset will further promote the development of universal image steganalysis technology. The description of IStego100K and instructions for use can be found at https://github.com/YangzlTHU/IStego100K
Neural News Recommendation with Attentive Multi-View Learning
Jul 12, 2019
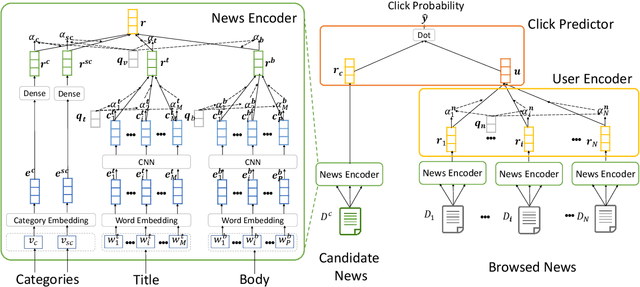
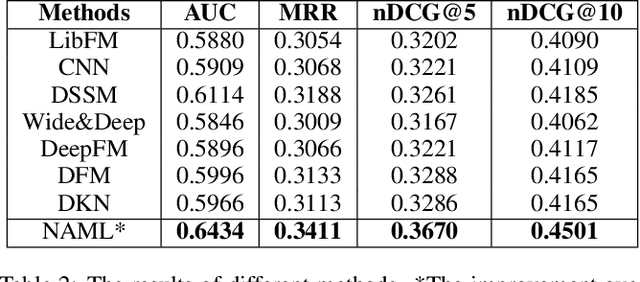
Personalized news recommendation is very important for online news platforms to help users find interested news and improve user experience. News and user representation learning is critical for news recommendation. Existing news recommendation methods usually learn these representations based on single news information, e.g., title, which may be insufficient. In this paper we propose a neural news recommendation approach which can learn informative representations of users and news by exploiting different kinds of news information. The core of our approach is a news encoder and a user encoder. In the news encoder we propose an attentive multi-view learning model to learn unified news representations from titles, bodies and topic categories by regarding them as different views of news. In addition, we apply both word-level and view-level attention mechanism to news encoder to select important words and views for learning informative news representations. In the user encoder we learn the representations of users based on their browsed news and apply attention mechanism to select informative news for user representation learning. Extensive experiments on a real-world dataset show our approach can effectively improve the performance of news recommendation.
NPA: Neural News Recommendation with Personalized Attention
Jul 12, 2019

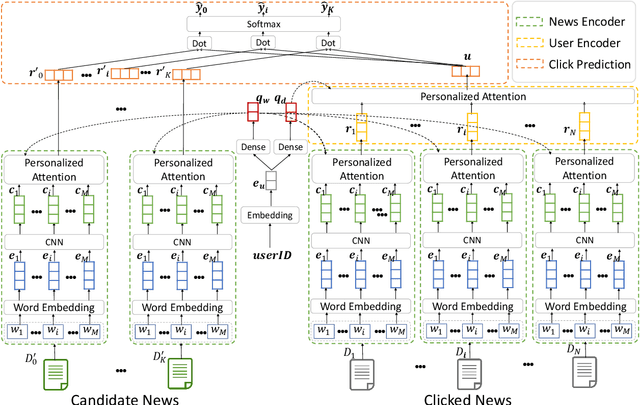
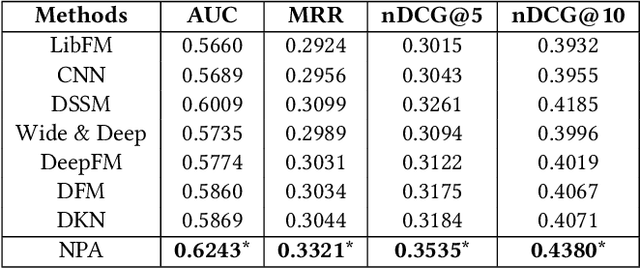
News recommendation is very important to help users find interested news and alleviate information overload. Different users usually have different interests and the same user may have various interests. Thus, different users may click the same news article with attention on different aspects. In this paper, we propose a neural news recommendation model with personalized attention (NPA). The core of our approach is a news representation model and a user representation model. In the news representation model we use a CNN network to learn hidden representations of news articles based on their titles. In the user representation model we learn the representations of users based on the representations of their clicked news articles. Since different words and different news articles may have different informativeness for representing news and users, we propose to apply both word- and news-level attention mechanism to help our model attend to important words and news articles. In addition, the same news article and the same word may have different informativeness for different users. Thus, we propose a personalized attention network which exploits the embedding of user ID to generate the query vector for the word- and news-level attentions. Extensive experiments are conducted on a real-world news recommendation dataset collected from MSN news, and the results validate the effectiveness of our approach on news recommendation.
Water Preservation in Soan River Basin using Deep Learning Techniques
Jun 26, 2019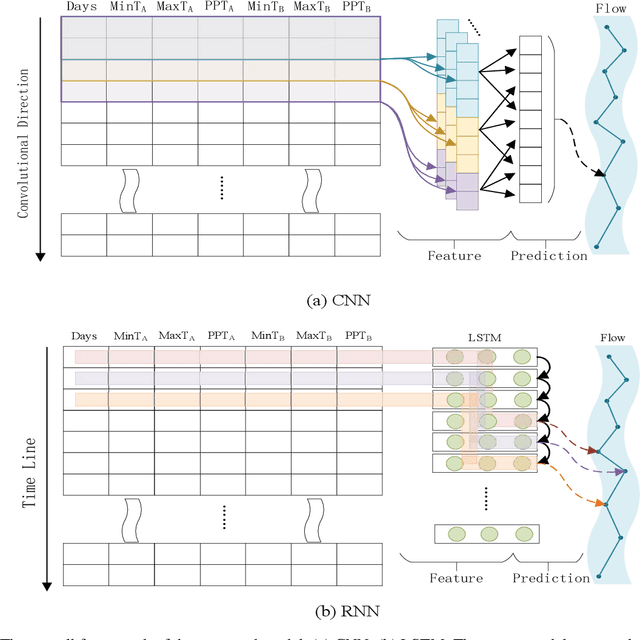

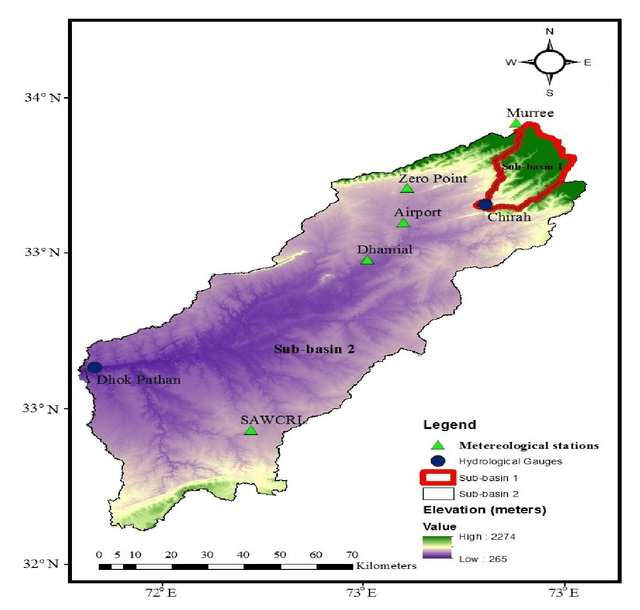
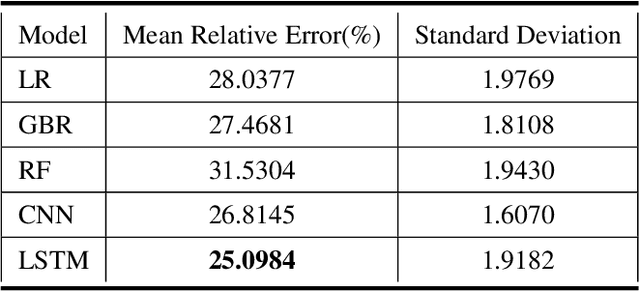
Water supplies are crucial for the development of living beings. However, change in the hydrological process i.e. climate and land usage are the key issues. Sustaining water level and accurate estimating for dynamic conditions is a critical job for hydrologists, but predicting hydrological extremes is an open issue. In this paper, we proposed two deep learning techniques and three machine learning algorithms to predict stream flow, given the present climate conditions. The results showed that the Recurrent Neural Network (RNN) or Long Short-term Memory (LSTM), an artificial neural network based method, outperform other conventional and machine-learning algorithms for predicting stream flow. Furthermore, we analyzed that stream flow is directly affected by precipitation, land usage, and temperature. These indexes are critical, which can be used by hydrologists to identify the potential for stream flow. We make the dataset publicly available (https://github.com/sadaqat007/Dataset) so that others should be able to replicate and build upon the results published.
Neural Chinese Word Segmentation with Lexicon and Unlabeled Data via Posterior Regularization
Apr 26, 2019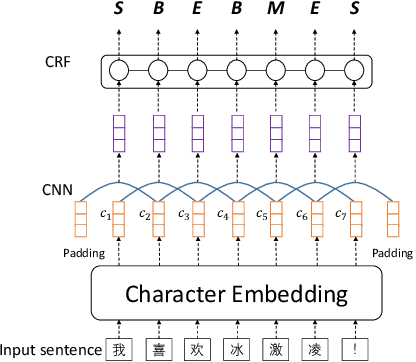
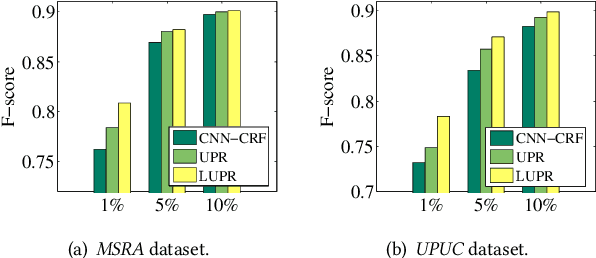
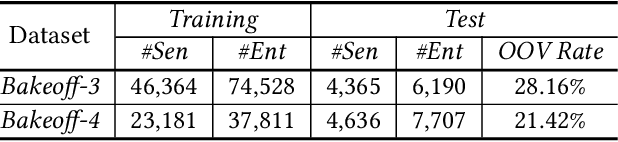
Existing methods for CWS usually rely on a large number of labeled sentences to train word segmentation models, which are expensive and time-consuming to annotate. Luckily, the unlabeled data is usually easy to collect and many high-quality Chinese lexicons are off-the-shelf, both of which can provide useful information for CWS. In this paper, we propose a neural approach for Chinese word segmentation which can exploit both lexicon and unlabeled data. Our approach is based on a variant of posterior regularization algorithm, and the unlabeled data and lexicon are incorporated into model training as indirect supervision by regularizing the prediction space of CWS models. Extensive experiments on multiple benchmark datasets in both in-domain and cross-domain scenarios validate the effectiveness of our approach.
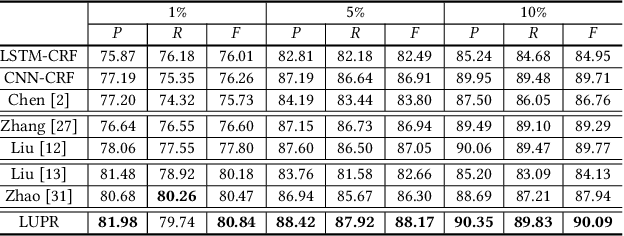
Neural Chinese Named Entity Recognition via CNN-LSTM-CRF and Joint Training with Word Segmentation
Apr 26, 2019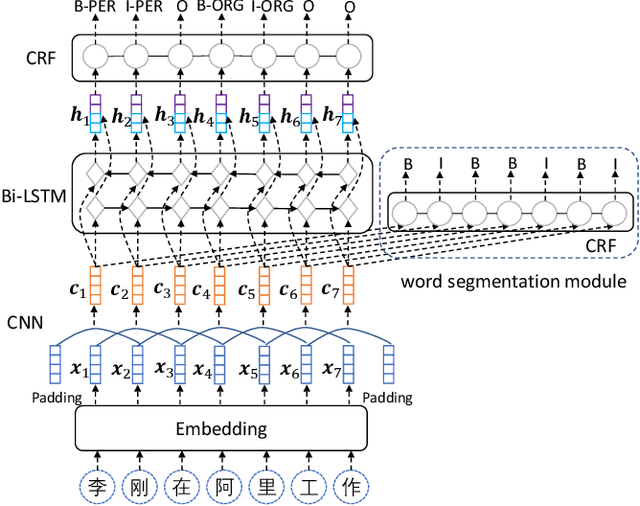
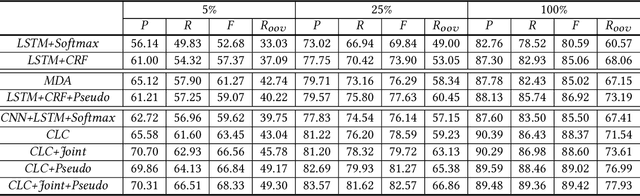
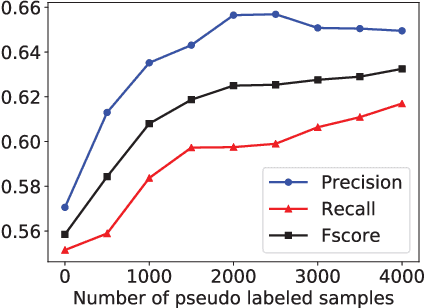
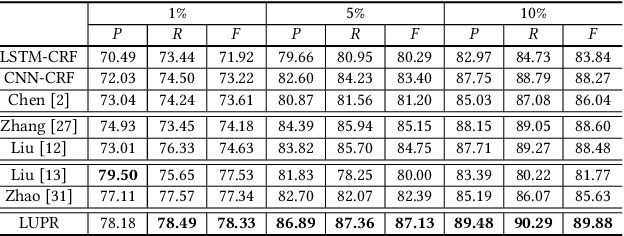
Chinese named entity recognition (CNER) is an important task in Chinese natural language processing field. However, CNER is very challenging since Chinese entity names are highly context-dependent. In addition, Chinese texts lack delimiters to separate words, making it difficult to identify the boundary of entities. Besides, the training data for CNER in many domains is usually insufficient, and annotating enough training data for CNER is very expensive and time-consuming. In this paper, we propose a neural approach for CNER. First, we introduce a CNN-LSTM-CRF neural architecture to capture both local and long-distance contexts for CNER. Second, we propose a unified framework to jointly train CNER and word segmentation models in order to enhance the ability of CNER model in identifying entity boundaries. Third, we introduce an automatic method to generate pseudo labeled samples from existing labeled data which can enrich the training data. Experiments on two benchmark datasets show that our approach can effectively improve the performance of Chinese named entity recognition, especially when training data is insufficient.
Real-Time Steganalysis for Stream Media Based on Multi-channel Convolutional Sliding Windows
Feb 04, 2019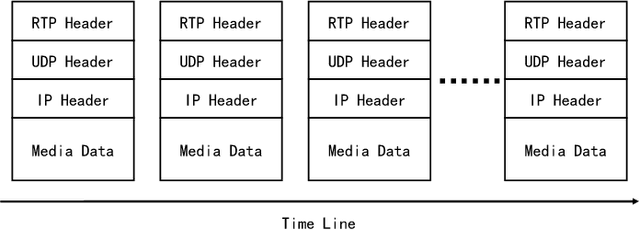
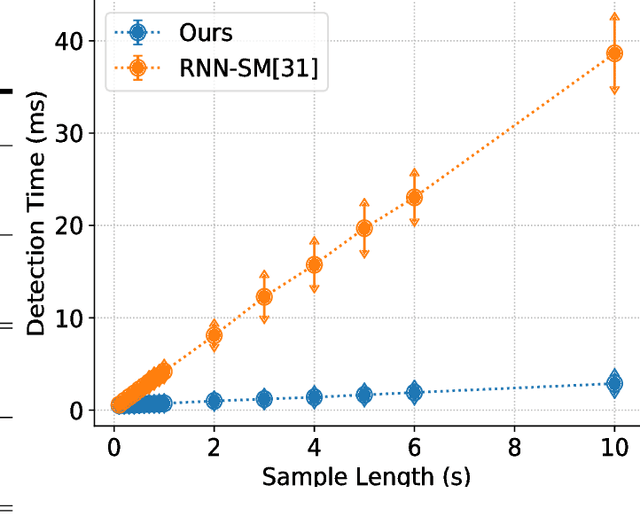
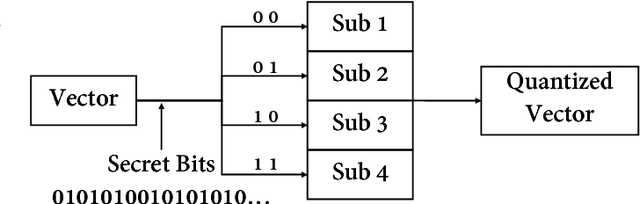
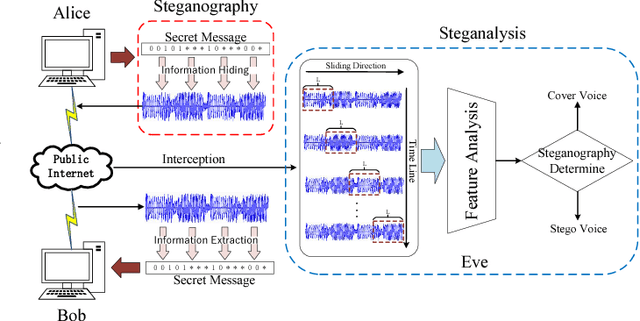
Previous VoIP steganalysis methods face great challenges in detecting speech signals at low embedding rates, and they are also generally difficult to perform real-time detection, making them hard to truly maintain cyberspace security. To solve these two challenges, in this paper, combined with the sliding window detection algorithm and Convolution Neural Network we propose a real-time VoIP steganalysis method which based on multi-channel convolution sliding windows. In order to analyze the correlations between frames and different neighborhood frames in a VoIP signal, we define multi channel sliding detection windows. Within each sliding window, we design two feature extraction channels which contain multiple convolution layers with multiple convolution kernels each layer to extract correlation features of the input signal. Then based on these extracted features, we use a forward fully connected network for feature fusion. Finally, by analyzing the statistical distribution of these features, the discriminator will determine whether the input speech signal contains covert information or not.We designed several experiments to test the proposed model's detection ability under various conditions, including different embedding rates, different speech length, etc. Experimental results showed that the proposed model outperforms all the previous methods, especially in the case of low embedding rate, which showed state-of-the-art performance. In addition, we also tested the detection efficiency of the proposed model, and the results showed that it can achieve almost real-time detection of VoIP speech signals.