 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Chinese Word Segmentation with Lexicon and Unlabeled Data via Posterior Regularization
Apr 26, 2019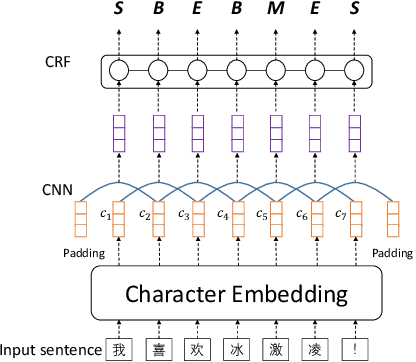
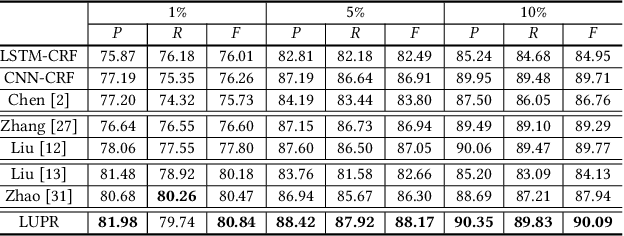
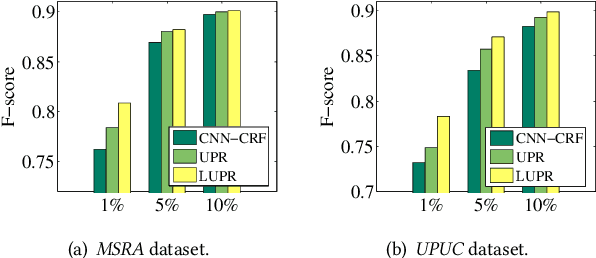
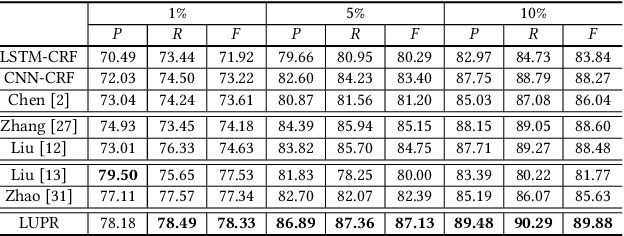
Existing methods for CWS usually rely on a large number of labeled sentences to train word segmentation models, which are expensive and time-consuming to annotate. Luckily, the unlabeled data is usually easy to collect and many high-quality Chinese lexicons are off-the-shelf, both of which can provide useful information for CWS. In this paper, we propose a neural approach for Chinese word segmentation which can exploit both lexicon and unlabeled data. Our approach is based on a variant of posterior regularization algorithm, and the unlabeled data and lexicon are incorporated into model training as indirect supervision by regularizing the prediction space of CWS models. Extensive experiments on multiple benchmark datasets in both in-domain and cross-domain scenarios validate the effectiveness of our approach.
Neural Chinese Named Entity Recognition via CNN-LSTM-CRF and Joint Training with Word Segmentation
Apr 26, 2019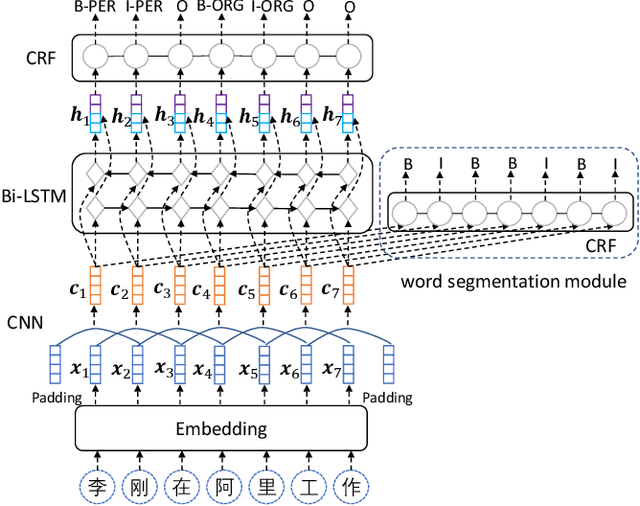
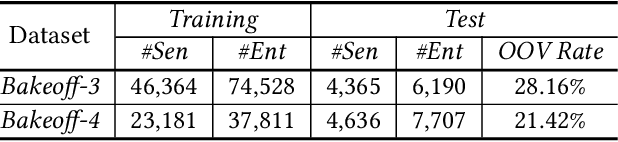
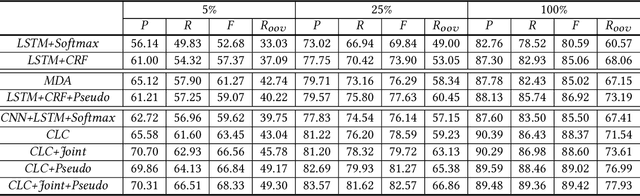
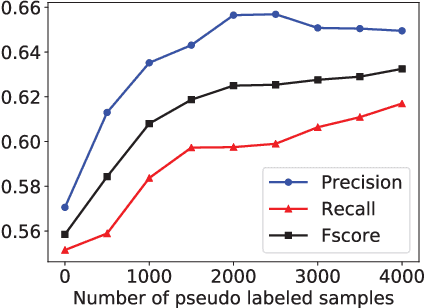
Chinese named entity recognition (CNER) is an important task in Chinese natural language processing field. However, CNER is very challenging since Chinese entity names are highly context-dependent. In addition, Chinese texts lack delimiters to separate words, making it difficult to identify the boundary of entities. Besides, the training data for CNER in many domains is usually insufficient, and annotating enough training data for CNER is very expensive and time-consuming. In this paper, we propose a neural approach for CNER. First, we introduce a CNN-LSTM-CRF neural architecture to capture both local and long-distance contexts for CNER. Second, we propose a unified framework to jointly train CNER and word segmentation models in order to enhance the ability of CNER model in identifying entity boundaries. Third, we introduce an automatic method to generate pseudo labeled samples from existing labeled data which can enrich the training data. Experiments on two benchmark datasets show that our approach can effectively improve the performance of Chinese named entity recognition, especially when training data is insufficient.
Neural Chinese Word Segmentation with Dictionary Knowledge
Jul 11, 2018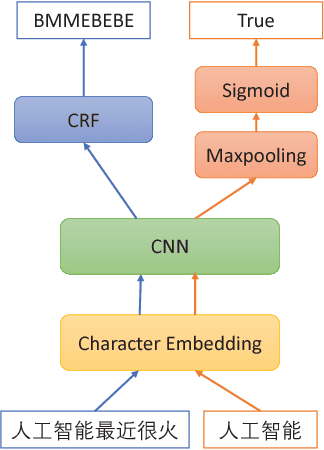
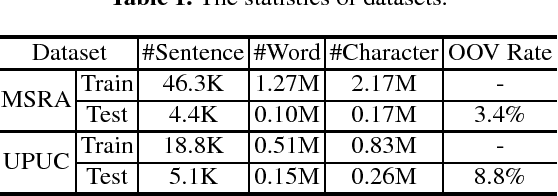
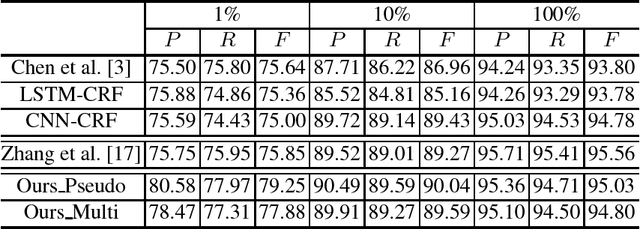
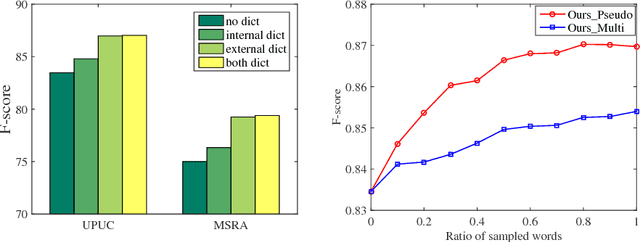
Chinese word segmentation (CWS) is an important task for Chinese NLP. Recently, many neural network based methods have been proposed for CWS. However, these methods require a large number of labeled sentences for model training, and usually cannot utilize the useful information in Chinese dictionary. In this paper, we propose two methods to exploit the dictionary information for CWS. The first one is based on pseudo labeled data generation, and the second one is based on multi-task learning. The experimental results on two benchmark datasets validate that our approach can effectively improve the performance of Chinese word segmentation, especially when training data is insufficient.