 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro- and Macro-Level Churn Analysis of Large-Scale Mobile Games
Jan 14, 2019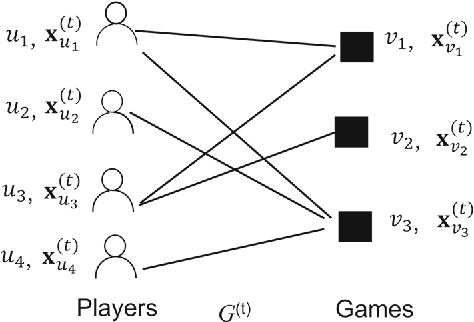

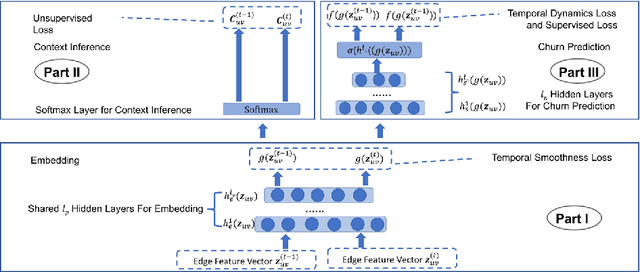
As mobile devices become more and more popular, mobile gaming has emerged as a promising market with billion-dollar revenues. A variety of mobile game platforms and services have been developed around the world. A critical challenge for these platforms and services is to understand the churn behavior in mobile games, which usually involves churn at micro level (between an app and a specific user) and macro level (between an app and all its users). Accurate micro-level churn prediction and macro-level churn ranking will benefit many stakeholders such as game developers, advertisers, and platform operators. In this paper, we present the first large-scale churn analysis for mobile games that supports both micro-level churn prediction and macro-level churn ranking. For micro-level churn prediction, in view of the common limitations of the state-of-the-art methods built upon traditional machine learning models, we devise a novel semi-supervised and inductive embedding model that jointly learns the prediction function and the embedding function for user-app relationships. We model these two functions by deep neural networks with a unique edge embedding technique that is able to capture both contextual information and relationship dynamics. We also design a novel attributed random walk technique that takes into consideration both topological adjacency and attribute similarities. To address macro-level churn ranking, we propose to construct a relationship graph with estimated micro-level churn probabilities as edge weights and adapt link analysis algorithms on the graph. We devise a simple algorithm SimSum and adapt two more advanced algorithms PageRank and HITS. The performance of our solutions for the two-level churn analysis problems is evaluated on real-world data collected from the Samsung Game Launcher platform.
A Semi-Supervised and Inductive Embedding Model for Churn Prediction of Large-Scale Mobile Games
Oct 10, 2018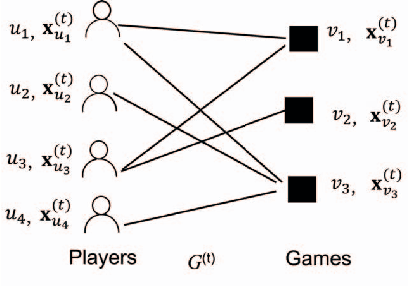
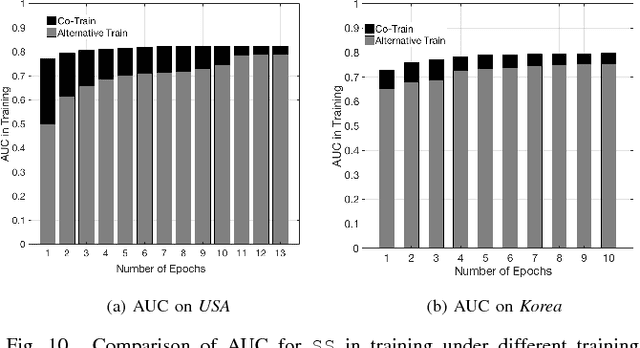
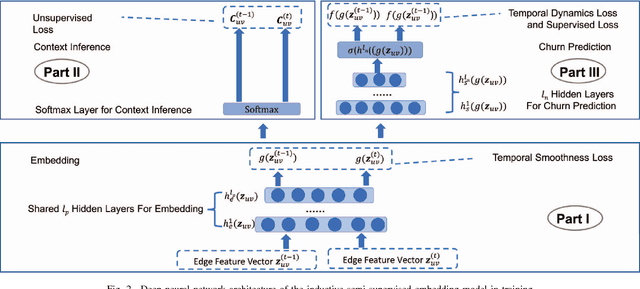
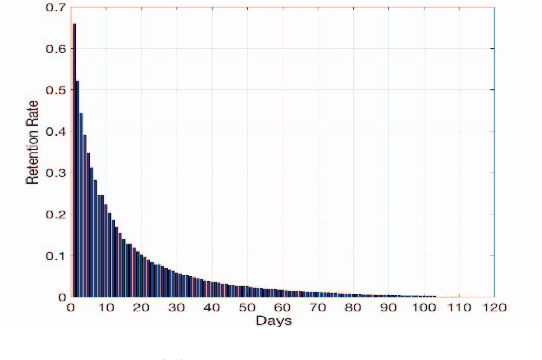
Mobile gaming has emerged as a promising market with billion-dollar revenues. A variety of mobile game platforms and services have been developed around the world. One critical challenge for these platforms and services is to understand user churn behavior in mobile games. Accurate churn prediction will benefit many stakeholders such as game developers, advertisers, and platform operators. In this paper, we present the first large-scale churn prediction solution for mobile games. In view of the common limitations of the state-of-the-art methods built upon traditional machine learning models, we devise a novel semi-supervised and inductive embedding model that jointly learns the prediction function and the embedding function for user-app relationships. We model these two functions by deep neural networks with a unique edge embedding technique that is able to capture both contextual information and relationship dynamics. We also design a novel attributed random walk technique that takes into consideration both topological adjacency and attribute similarities. To evaluate the performance of our solution, we collect real-world data from the Samsung Game Launcher platform that includes tens of thousands of games and hundreds of millions of user-app interactions. The experimental results with this data demonstrate the superiority of our proposed model against existing state-of-the-art methods.
A Context-aware Attention Network for Interactive Question Answering
Sep 03, 2017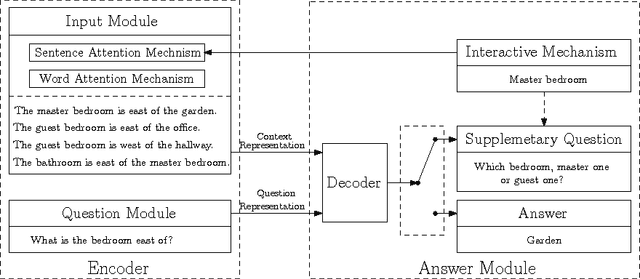
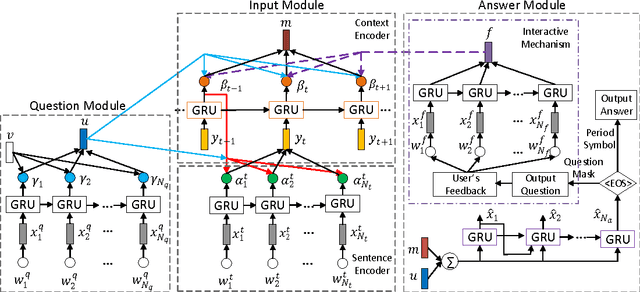

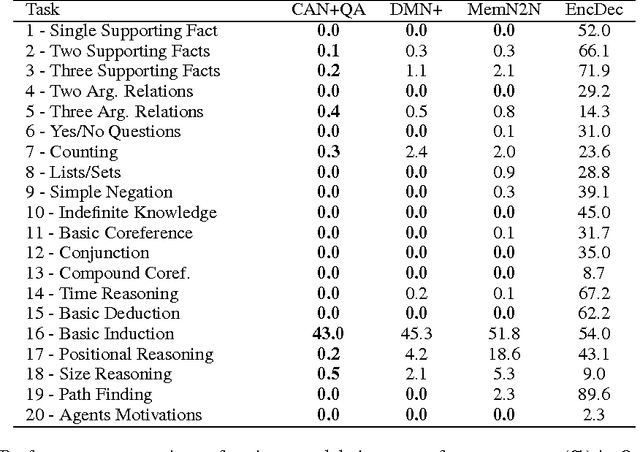
Neural network based sequence-to-sequence models in an encoder-decoder framework have been successfully applied to solve Question Answering (QA) problems, predicting answers from statements and questions. However, almost all previous models have failed to consider detailed context information and unknown states under which systems do not have enough information to answer given questions. These scenarios with incomplete or ambiguous information are very common in the setting of Interactive Question Answering (IQA). To address this challenge, we develop a novel model, employing context-dependent word-level attention for more accurate statement representations and question-guided sentence-level attention for better context modeling. We also generate unique IQA datasets to test our model, which will be made publicly available. Employing these attention mechanisms, our model accurately understands when it can output an answer or when it requires generating a supplementary question for additional input depending on different contexts. When available, user's feedback is encoded and directly applied to update sentence-level attention to infer an answer. Extensive experiments on QA and IQA datasets quantitatively demonstrate the effectiveness of our model with significant improvement over state-of-the-art conventional QA models.
Heterogeneous Metric Learning with Content-based Regularization for Software Artifact Retrieval
Sep 25, 2014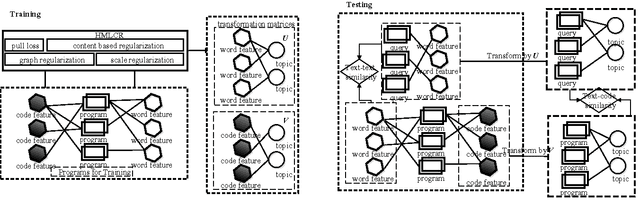
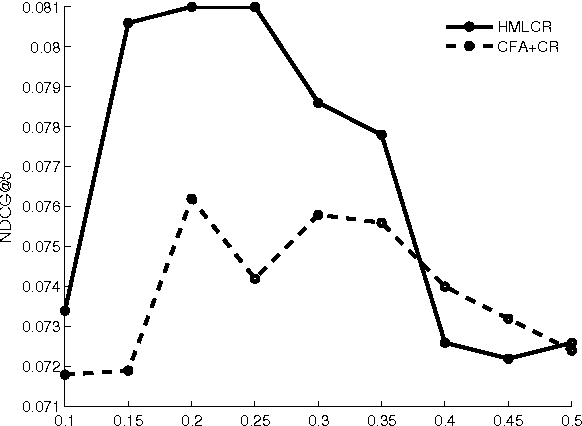

The problem of software artifact retrieval has the goal to effectively locate software artifacts, such as a piece of source code, in a large code repository. This problem has been traditionally addressed through the textual query. In other words, information retrieval techniques will be exploited based on the textual similarity between queries and textual representation of software artifacts, which is generated by collecting words from comments, identifiers, and descriptions of programs. However, in addition to these semantic information, there are rich information embedded in source codes themselves. These source codes, if analyzed properly, can be a rich source for enhancing the efforts of software artifact retrieval. To this end, in this paper, we develop a feature extraction method on source codes. Specifically, this method can capture both the inherent information in the source codes and the semantic information hidden in the comments, descriptions, and identifiers of the source codes. Moreover, we design a heterogeneous metric learning approach, which allows to integrate code features and text features into the same latent semantic space. This, in turn, can help to measure the artifact similarity by exploiting the joint power of both code and text features. Finally, extensive experiments on real-world data show that the proposed method can help to improve the performances of software artifact retrieval with a significant margin.