 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap: Standard 3DGS Evaluation Primarily Measures Near-Trajectory Interpolation
Jul 02, 2026Standard MipNeRF360-style 3D Gaussian Splatting (3DGS) evaluation holds out every N-th frame -- but these frames have trained neighbors on both sides, so the metric measures near-trajectory interpolation rather than spatial generalization. We introduce a fair matched-count protocol that isolates this effect: both arms train on the same number of images and differ only in whether the holdout is spread evenly (interpolation) or forms a contiguous spatial sector (extrapolation). Our primary finding is a large, consistent interpolation-extrapolation gap of 3~12dB -- several times the differences typically reported between competing methods. The gap is robust to training noise, is in two cases large enough to flip a method ranking under multi-seed confirmation, and -- crucially -- persists across three representation families, including a non-Gaussian volumetric neural radiance field (NeRF), so it reflects spatial coverage rather than any one representation. Diagnostically, it is dominated by a diffuse/geometry-proxy component and tracks each view's angular distance to its nearest training view, a zero-cost signal that also guides capture planning; loss-side regularization yields only marginal gains. Standard holdouts remain useful for near-trajectory rendering but should not, alone, be read as evidence of spatial generalization. Prior work notes protocol sensitivity; ours is, to our knowledge, the first to combine matched-count paired holdout, cross-representation quantification, and a diagnostic analysis Table 1. We describe a spatial-holdout benchmark toolkit with standardized splits and baselines for 16 scenes, which we are preparing for public release.
Long-Context Aware Upcycling: A New Frontier for Hybrid LLM Scaling
Apr 27, 2026Hybrid sequence models that combine efficient Transformer components with linear sequence modeling blocks are a promising alternative to pure Transformers, but most are still pretrained from scratch and therefore fail to reuse existing Transformer checkpoints. We study upcycling as a practical path to convert pretrained Transformer LLMs into hybrid architectures while preserving short-context quality and improving long-context capability. We call our solution \emph{HyLo} (HYbrid LOng-context): a long-context upcycling recipe that combines architectural adaptation with efficient Transformer blocks, Multi-Head Latent Attention (MLA), and linear blocks (Mamba2 or Gated DeltaNet), together with staged long-context training and teacher-guided distillation for stable optimization. HyLo extends usable context length by up to $32\times$ through efficient post-training and reduces KV-cache memory by more than $90\%$, enabling up to 2M-token prefill and decoding in our \texttt{vLLM} inference stack, while comparable Llama baselines run out of memory beyond 64K context. Across 1B- and 3B-scale settings (Llama- and Qwen-based variants), HyLo delivers consistently strong short- and long-context performance and significantly outperforms state-of-the-art upcycled hybrid baselines on long-context evaluations such as RULER. Notably, at similar scale, HyLo-Qwen-1.7B trained on only 10B tokens significantly outperforms JetNemotron (trained on 400B tokens) on GSM8K, Lm-Harness common sense reasoning and RULER-64K.
FarSkip-Collective: Unhobbling Blocking Communication in Mixture of Experts Models
Nov 14, 2025



Blocking communication presents a major hurdle in running MoEs efficiently in distributed settings. To address this, we present FarSkip-Collective which modifies the architecture of modern models to enable overlapping of their computation with communication. Our approach modifies the architecture to skip connections in the model and it is unclear a priori whether the modified model architecture can remain as capable, especially for large state-of-the-art models and while modifying all of the model layers. We answer this question in the affirmative and fully convert a series of state-of-the-art models varying from 16B to 109B parameters to enable overlapping of their communication while achieving accuracy on par with their original open-source releases. For example, we convert Llama 4 Scout (109B) via self-distillation and achieve average accuracy within 1% of its instruction tuned release averaged across a wide range of downstream evaluations. In addition to demonstrating retained accuracy of the large modified models, we realize the benefits of FarSkip-Collective through optimized implementations that explicitly overlap communication with computation, accelerating both training and inference in existing frameworks.
Zebra-Llama: Towards Extremely Efficient Hybrid Models
May 22, 2025With the growing demand for deploying large language models (LLMs) across diverse applications, improving their inference efficiency is crucial for sustainable and democratized access. However, retraining LLMs to meet new user-specific requirements is prohibitively expensive and environmentally unsustainable. In this work, we propose a practical and scalable alternative: composing efficient hybrid language models from existing pre-trained models. Our approach, Zebra-Llama, introduces a family of 1B, 3B, and 8B hybrid models by combining State Space Models (SSMs) and Multi-head Latent Attention (MLA) layers, using a refined initialization and post-training pipeline to efficiently transfer knowledge from pre-trained Transformers. Zebra-Llama achieves Transformer-level accuracy with near-SSM efficiency using only 7-11B training tokens (compared to trillions of tokens required for pre-training) and an 8B teacher. Moreover, Zebra-Llama dramatically reduces KV cache size -down to 3.9%, 2%, and 2.73% of the original for the 1B, 3B, and 8B variants, respectively-while preserving 100%, 100%, and >97% of average zero-shot performance on LM Harness tasks. Compared to models like MambaInLLaMA, X-EcoMLA, Minitron, and Llamba, Zebra-Llama consistently delivers competitive or superior accuracy while using significantly fewer tokens, smaller teachers, and vastly reduced KV cache memory. Notably, Zebra-Llama-8B surpasses Minitron-8B in few-shot accuracy by 7% while using 8x fewer training tokens, over 12x smaller KV cache, and a smaller teacher (8B vs. 15B). It also achieves 2.6x-3.8x higher throughput (tokens/s) than MambaInLlama up to a 32k context length. We will release code and model checkpoints upon acceptance.
X-EcoMLA: Upcycling Pre-Trained Attention into MLA for Efficient and Extreme KV Compression
Mar 14, 2025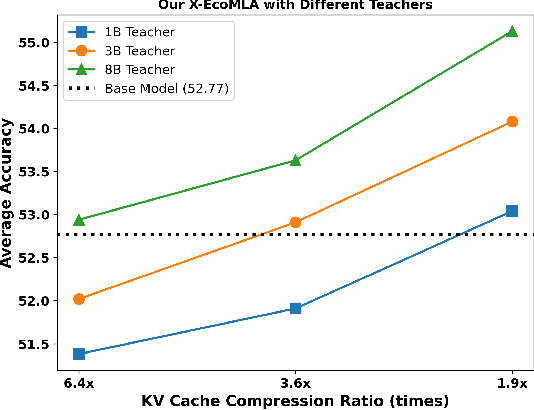
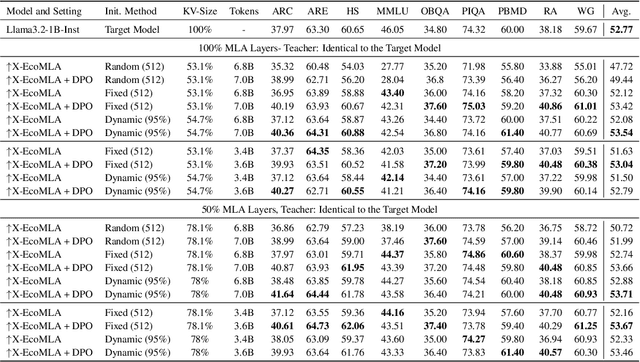
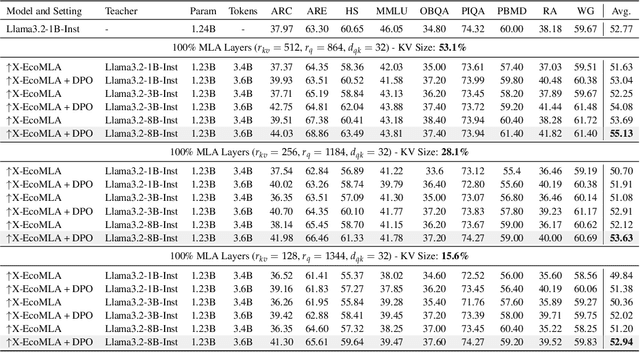
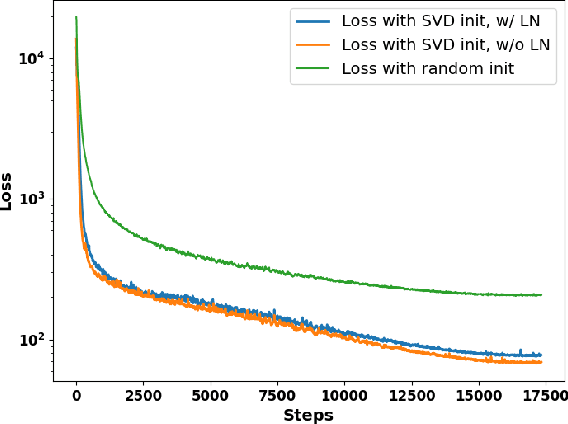
Multi-head latent attention (MLA) is designed to optimize KV cache memory through low-rank key-value joint compression. Rather than caching keys and values separately, MLA stores their compressed latent representations, reducing memory overhead while maintaining the performance. While MLA improves memory efficiency without compromising language model accuracy, its major limitation lies in its integration during the pre-training phase, requiring models to be trained from scratch. This raises a key question: can we use MLA's benefits fully or partially in models that have already been pre-trained with different attention mechanisms? In this paper, we propose X-EcoMLA to deploy post training distillation to enable the upcycling of Transformer-based attention into an efficient hybrid (i.e., combination of regular attention and MLA layers) or full MLA variant through lightweight post-training adaptation, bypassing the need for extensive pre-training. We demonstrate that leveraging the dark knowledge of a well-trained model can enhance training accuracy and enable extreme KV cache compression in MLA without compromising model performance. Our results show that using an 8B teacher model allows us to compress the KV cache size of the Llama3.2-1B-Inst baseline by 6.4x while preserving 100% of its average score across multiple tasks on the LM Harness Evaluation benchmark. This is achieved with only 3.6B training tokens and about 70 GPU hours on AMD MI300 GPUs, compared to the 370K GPU hours required for pre-training the Llama3.2-1B model.