 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntSQL: A Benchmark for Grounding Text-to-SQL in Long-Context Enterprise Knowledge
Jun 02, 2026Text-to-SQL enables natural language access to databases, and recent LLMs have substantially advanced its capabilities. Existing benchmarks such as Spider, BIRD, and Spider~2.0 evaluate schema generalization, large-scale databases, and realistic workflows, but largely overlook enterprise scenarios where SQL generation depends on private business knowledge, such as internal metrics, reporting conventions, and organizational rules. We introduce EntSQL, an enterprise-oriented Text-to-SQL benchmark for evaluating long-context grounding over proprietary business documents. EntSQL contains 1,066 aligned Chinese-English semantic examples across five business domains, with most examples requiring domain knowledge beyond the question and schema and involving complex SQL structures. On English inputs, the best evaluated system reaches only 15.9\% when long-form documents are provided, highlighting the difficulty of grounding SQL generation in enterprise knowledge.
MatPhys: Learning Material-Aware Physics Parameters for Deformable Object Simulation from Videos
May 19, 2026Reconstructing simulation-ready deformable objects is important for vision, graphics, and robotics. Existing physics-driven methods can recover physical digital twins from videos, but they suffer from two fundamental limitations: they typically assume a homogeneous material across the whole object, and their scene-specific inverse optimization, combined with the inherent ambiguity of monocular observation, yields inconsistent parameters for the same material across different scenes or interactions. We propose MatPhys, a material-aware feed-forward framework that predicts spring-mass parameters from a single-view video, addressing these two issues with two coupled designs. To relax the homogeneous material assumption, we use DINO features to decompose the object into semantically meaningful parts and to query a part-level material prior, assigning each part its own physical behavior. To enforce cross-scene consistency, we introduce a learned material codebook of shared material embeddings as the bridge between appearance and physics, and further use the part-level prior as a reference distribution that constrains the decoder so that the same material yields consistent parameters across scenes and interactions. Together, these designs turn an under-constrained monocular problem into feed-forward inference grounded on shared, reusable material concepts. Experiments show that our method matches per-scene optimization baselines in reconstruction and future prediction, while achieving stronger generalization to unseen interactions and objects with more consistent physical parameters.
UniGarmentManip: A Unified Framework for Category-Level Garment Manipulation via Dense Visual Correspondence
May 11, 2024



Garment manipulation (e.g., unfolding, folding and hanging clothes) is essential for future robots to accomplish home-assistant tasks, while highly challenging due to the diversity of garment configurations, geometries and deformations. Although able to manipulate similar shaped garments in a certain task, previous works mostly have to design different policies for different tasks, could not generalize to garments with diverse geometries, and often rely heavily on human-annotated data. In this paper, we leverage the property that, garments in a certain category have similar structures, and then learn the topological dense (point-level) visual correspondence among garments in the category level with different deformations in the self-supervised manner. The topological correspondence can be easily adapted to the functional correspondence to guide the manipulation policies for various downstream tasks, within only one or few-shot demonstrations. Experiments over garments in 3 different categories on 3 representative tasks in diverse scenarios, using one or two arms, taking one or more steps, inputting flat or messy garments, demonstrate the effectiveness of our proposed method. Project page: https://warshallrho.github.io/unigarmentmanip.
Joint Bayesian Gaussian discriminant analysis for speaker verification
Jan 19, 2017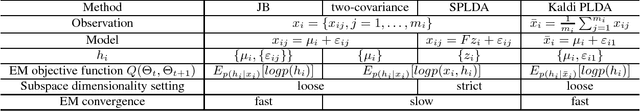



State-of-the-art i-vector based speaker verification relies on variants of Probabilistic Linear Discriminant Analysis (PLDA) for discriminant analysis. We are mainly motivated by the recent work of the joint Bayesian (JB) method, which is originally proposed for discriminant analysis in face verification. We apply JB to speaker verification and make three contributions beyond the original JB. 1) In contrast to the EM iterations with approximated statistics in the original JB, the EM iterations with exact statistics are employed and give better performance. 2) We propose to do simultaneous diagonalization (SD) of the within-class and between-class covariance matrices to achieve efficient testing, which has broader application scope than the SVD-based efficient testing method in the original JB. 3) We scrutinize similarities and differences between various Gaussian PLDAs and JB, complementing the previous analysis of comparing JB only with Prince-Elder PLDA. Extensive experiments are conducted on NIST SRE10 core condition 5, empirically validating the superiority of JB with faster convergence rate and 9-13% EER reduction compared with state-of-the-art PLDA.