 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMISR: Compression-Informed Video Super-Resolution
May 04, 2021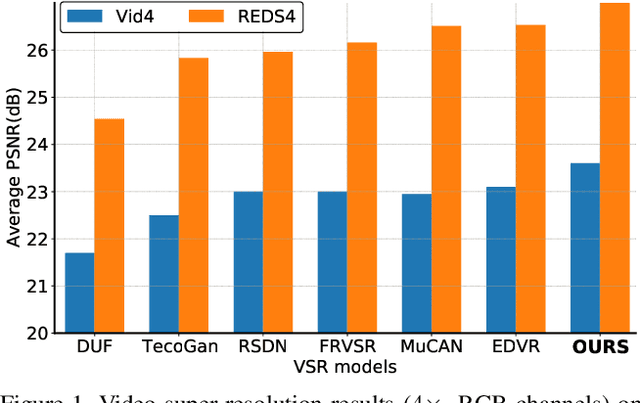
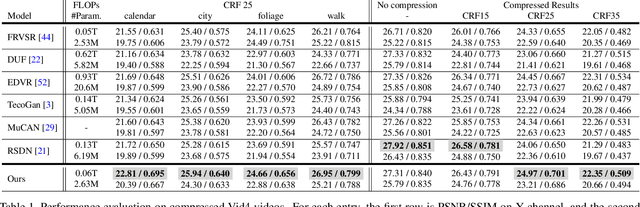
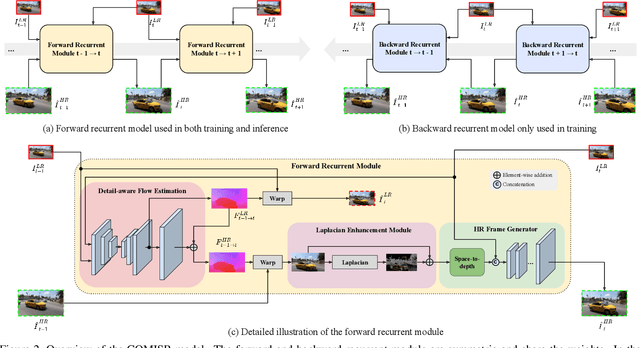
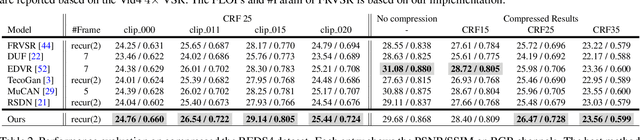
Most video super-resolution methods focus on restoring high-resolution video frames from low-resolution videos without taking into account compression. However, most videos on the web or mobile devices are compressed, and the compression can be severe when the bandwidth is limited. In this paper, we propose a new compression-informed video super-resolution model to restore high-resolution content without introducing artifacts caused by compression. The proposed model consists of three modules for video super-resolution: bi-directional recurrent warping, detail-preserving flow estimation, and Laplacian enhancement. All these three modules are used to deal with compression properties such as the location of the intra-frames in the input and smoothness in the output frames. For thorough performance evaluation, we conducted extensive experiments on standard datasets with a wide range of compression rates, covering many real video use cases. We showed that our method not only recovers high-resolution content on uncompressed frames from the widely-used benchmark datasets, but also achieves state-of-the-art performance in super-resolving compressed videos based on numerous quantitative metrics. We also evaluated the proposed method by simulating streaming from YouTube to demonstrate its effectiveness and robustness.
PERF-Net: Pose Empowered RGB-Flow Net
Sep 28, 2020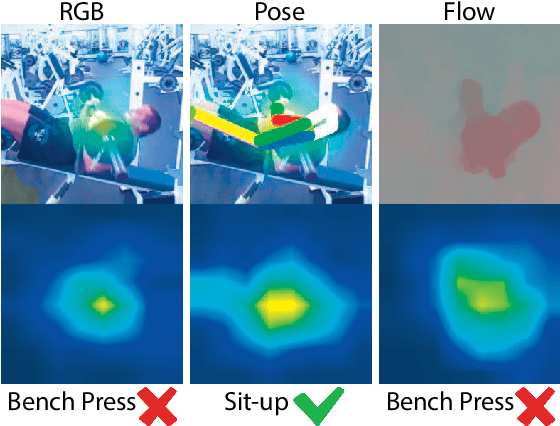
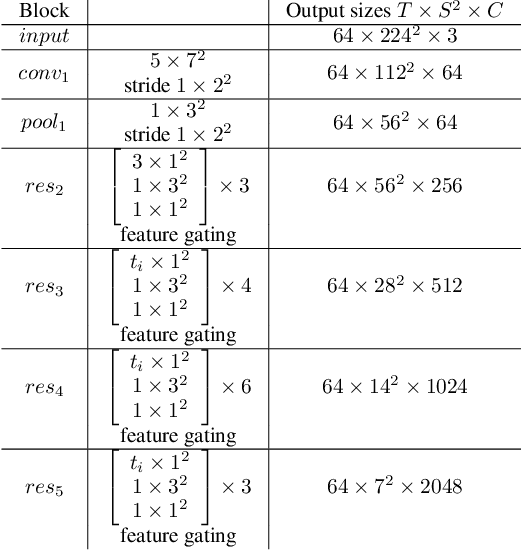

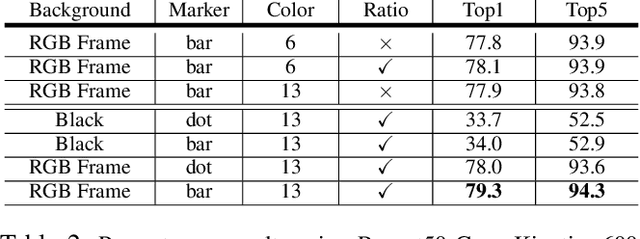
In recent years, many works in the video action recognition literature have shown that two stream models (combining spatial and temporal input streams) are necessary for achieving state of the art performance. In this paper we show the benefits of including yet another stream based on human pose estimated from each frame -- specifically by rendering pose on input RGB frames. At first blush, this additional stream may seem redundant given that human pose is fully determined by RGB pixel values -- however we show (perhaps surprisingly) that this simple and flexible addition can provide complementary gains. Using this insight, we then propose a new model, which we dub PERF-Net (short for Pose Empowered RGB-Flow Net), which combines this new pose stream with the standard RGB and flow based input streams via distillation techniques and show that our model outperforms the state-of-the-art by a large margin in a number of human action recognition datasets while not requiring flow or pose to be explicitly computed at inference time.
Handling Position Bias for Unbiased Learning to Rank in Hotels Search
Feb 28, 2020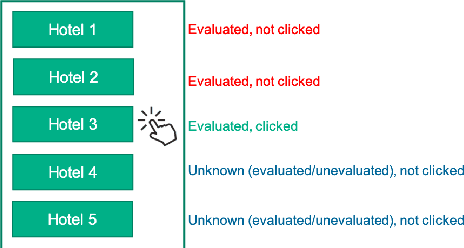
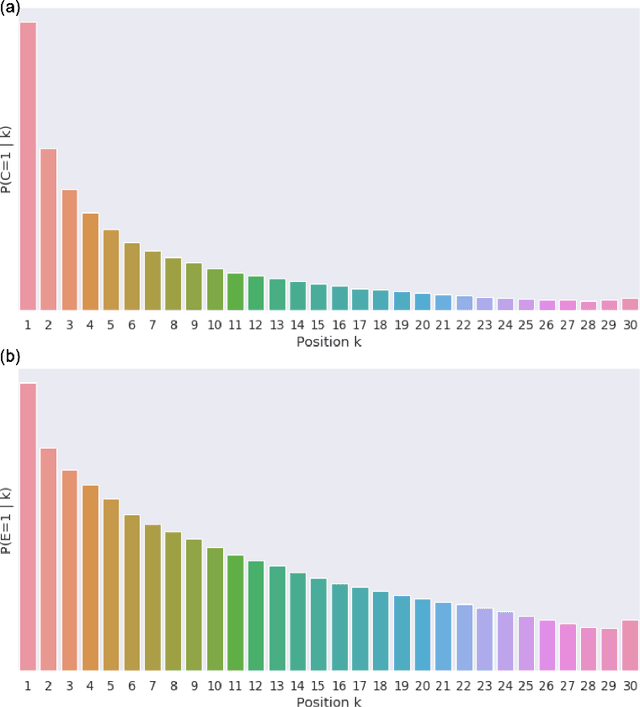
Nowadays, search ranking and recommendation systems rely on a lot of data to train machine learning models such as Learning-to-Rank (LTR) models to rank results for a given query, and implicit user feedbacks (e.g. click data) have become the dominant source of data collection due to its abundance and low cost, especially for major Internet companies. However, a drawback of this data collection approach is the data could be highly biased, and one of the most significant biases is the position bias, where users are biased towards clicking on higher ranked results. In this work, we will investigate the marginal importance of properly handling the position bias in an online test environment in Tripadvisor Hotels search. We propose an empirically effective method of handling the position bias that fully leverages the user action data. We take advantage of the fact that when user clicks a result, he has almost certainly observed all the results above, and the propensities of the results below the clicked result will be estimated by a simple but effective position bias model. The online A/B test results show that this method leads to an improved search ranking model.
Looking Fast and Slow: Memory-Guided Mobile Video Object Detection
Mar 25, 2019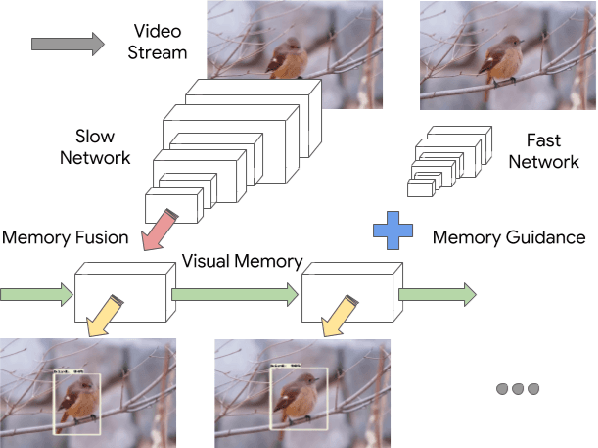
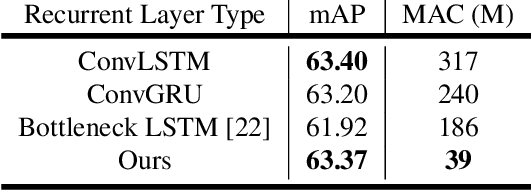
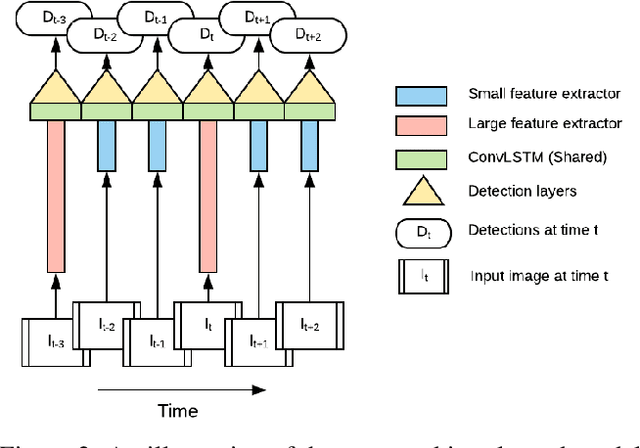
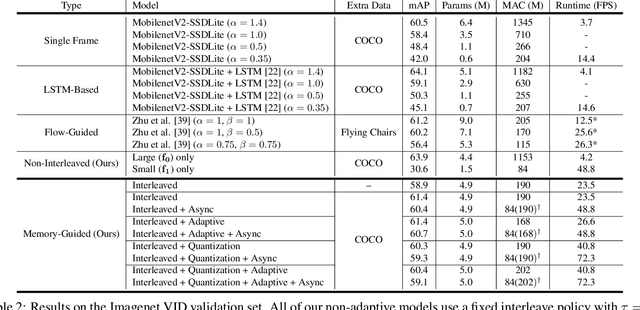
With a single eye fixation lasting a fraction of a second, the human visual system is capable of forming a rich representation of a complex environment, reaching a holistic understanding which facilitates object recognition and detection. This phenomenon is known as recognizing the "gist" of the scene and is accomplished by relying on relevant prior knowledge. This paper addresses the analogous question of whether using memory in computer vision systems can not only improve the accuracy of object detection in video streams, but also reduce the computation time. By interleaving conventional feature extractors with extremely lightweight ones which only need to recognize the gist of the scene, we show that minimal computation is required to produce accurate detections when temporal memory is present. In addition, we show that the memory contains enough information for deploying reinforcement learning algorithms to learn an adaptive inference policy. Our model achieves state-of-the-art performance among mobile methods on the Imagenet VID 2015 dataset, while running at speeds of up to 70+ FPS on a Pixel 3 phone.
Model-Driven Feed-Forward Prediction for Manipulation of Deformable Objects
Jul 15, 2016

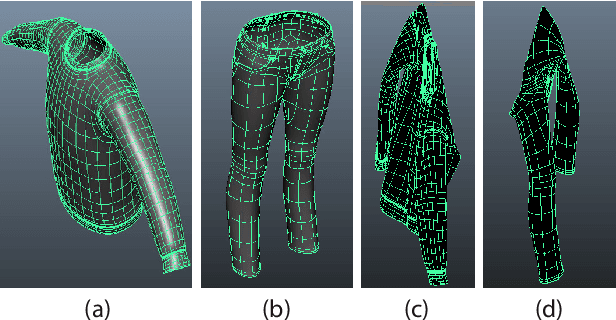
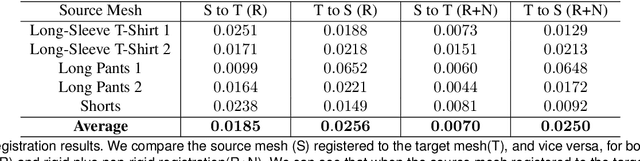
Robotic manipulation of deformable objects is a difficult problem especially because of the complexity of the many different ways an object can deform. Searching such a high dimensional state space makes it difficult to recognize, track, and manipulate deformable objects. In this paper, we introduce a predictive, model-driven approach to address this challenge, using a pre-computed, simulated database of deformable object models. Mesh models of common deformable garments are simulated with the garments picked up in multiple different poses under gravity, and stored in a database for fast and efficient retrieval. To validate this approach, we developed a comprehensive pipeline for manipulating clothing as in a typical laundry task. First, the database is used for category and pose estimation for a garment in an arbitrary position. A fully featured 3D model of the garment is constructed in real-time and volumetric features are then used to obtain the most similar model in the database to predict the object category and pose. Second, the database can significantly benefit the manipulation of deformable objects via non-rigid registration, providing accurate correspondences between the reconstructed object model and the database models. Third, the accurate model simulation can also be used to optimize the trajectories for manipulation of deformable objects, such as the folding of garments. Extensive experimental results are shown for the tasks above using a variety of different clothing.
Multi-Sensor Surface Analysis for Robotic Ironing
Feb 16, 2016
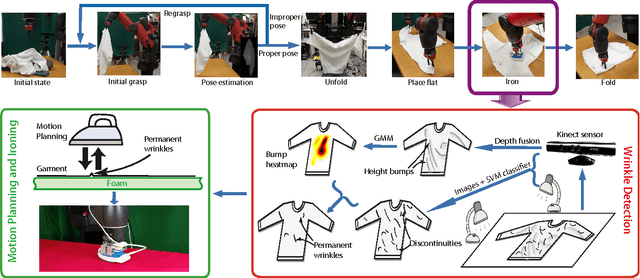


Robotic manipulation of deformable objects remains a challenging task. One such task is to iron a piece of cloth autonomously. Given a roughly flattened cloth, the goal is to have an ironing plan that can iteratively apply a regular iron to remove all the major wrinkles by a robot. We present a novel solution to analyze the cloth surface by fusing two surface scan techniques: a curvature scan and a discontinuity scan. The curvature scan can estimate the height deviation of the cloth surface, while the discontinuity scan can effectively detect sharp surface features, such as wrinkles. We use this information to detect the regions that need to be pulled and extended before ironing, and the other regions where we want to detect wrinkles and apply ironing to remove the wrinkles. We demonstrate that our hybrid scan technique is able to capture and classify wrinkles over the surface robustly. Given detected wrinkles, we enable a robot to iron them using shape features. Experimental results show that using our wrinkle analysis algorithm, our robot is able to iron the cloth surface and effectively remove the wrinkles.
Folding Deformable Objects using Predictive Simulation and Trajectory Optimization
Dec 22, 2015
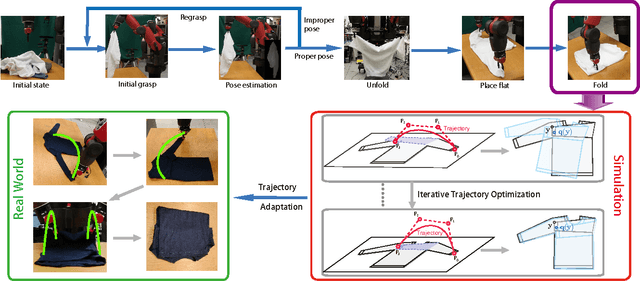


Robotic manipulation of deformable objects remains a challenging task. One such task is folding a garment autonomously. Given start and end folding positions, what is an optimal trajectory to move the robotic arm to fold a garment? Certain trajectories will cause the garment to move, creating wrinkles, and gaps, other trajectories will fail altogether. We present a novel solution to find an optimal trajectory that avoids such problematic scenarios. The trajectory is optimized by minimizing a quadratic objective function in an off-line simulator, which includes material properties of the garment and frictional force on the table. The function measures the dissimilarity between a user folded shape and the folded garment in simulation, which is then used as an error measurement to create an optimal trajectory. We demonstrate that our two-arm robot can follow the optimized trajectories, achieving accurate and efficient manipulations of deformable objects.
Articulated Pose Estimation Using Hierarchical Exemplar-Based Models
Dec 13, 2015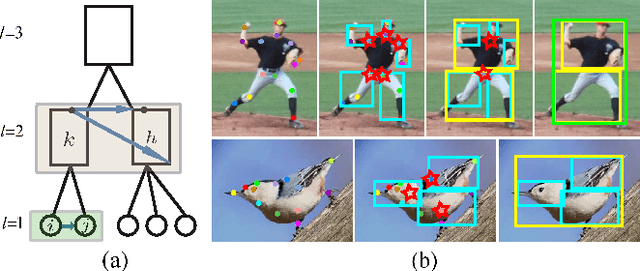
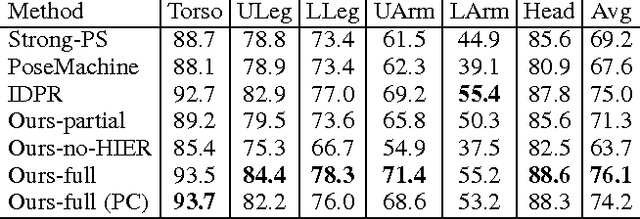
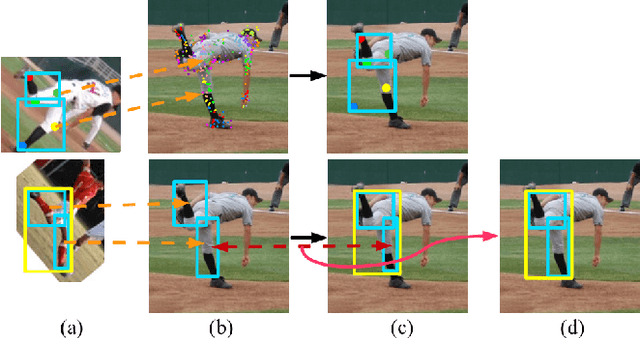

Exemplar-based models have achieved great success on localizing the parts of semi-rigid objects. However, their efficacy on highly articulated objects such as humans is yet to be explored. Inspired by hierarchical object representation and recent application of Deep Convolutional Neural Networks (DCNNs) on human pose estimation, we propose a novel formulation that incorporates both hierarchical exemplar-based models and DCNNs in the spatial terms. Specifically, we obtain more expressive spatial models by assuming independence between exemplars at different levels in the hierarchy; we also obtain stronger spatial constraints by inferring the spatial relations between parts at the same level. As our method strikes a good balance between expressiveness and strength of spatial models, it is both effective and generalizable, achieving state-of-the-art results on different benchmarks: Leeds Sports Dataset and CUB-200-2011.