 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYing Huang
Online Knowledge Distillation via Multi-branch Diversity Enhancement
Oct 02, 2020
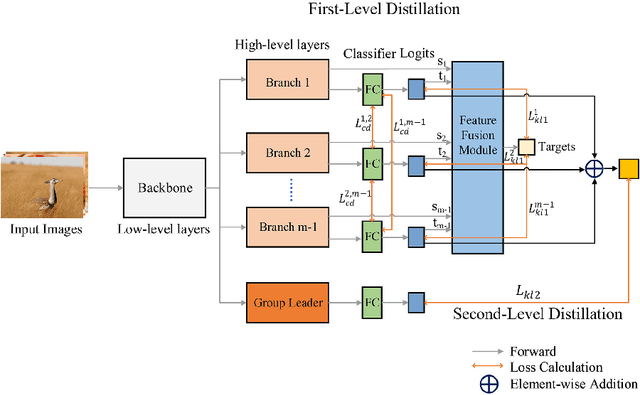
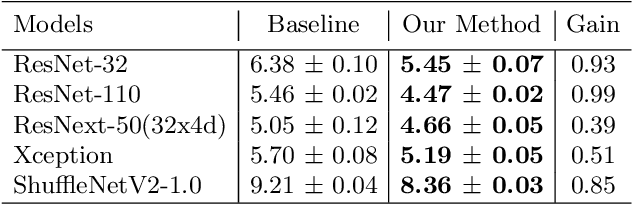
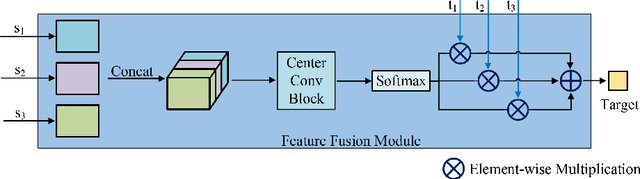
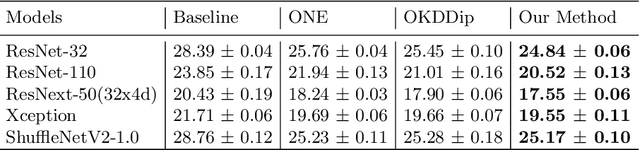
Knowledge distillation is an effective method to transfer the knowledge from the cumbersome teacher model to the lightweight student model. Online knowledge distillation uses the ensembled prediction results of multiple student models as soft targets to train each student model. However, the homogenization problem will lead to difficulty in further improving model performance. In this work, we propose a new distillation method to enhance the diversity among multiple student models. We introduce Feature Fusion Module (FFM), which improves the performance of the attention mechanism in the network by integrating rich semantic information contained in the last block of multiple student models. Furthermore, we use the Classifier Diversification(CD) loss function to strengthen the differences between the student models and deliver a better ensemble result. Extensive experiments proved that our method significantly enhances the diversity among student models and brings better distillation performance. We evaluate our method on three image classification datasets: CIFAR-10/100 and CINIC-10. The results show that our method achieves state-of-the-art performance on these datasets.
More Information Supervised Probabilistic Deep Face Embedding Learning
Jun 11, 2020

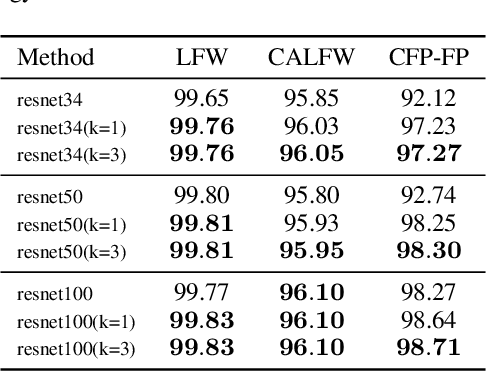
Researches using margin based comparison loss demonstrate the effectiveness of penalizing the distance between face feature and their corresponding class centers. Despite their popularity and excellent performance, they do not explicitly encourage the generic embedding learning for an open set recognition problem. In this paper, we analyse margin based softmax loss in probability view. With this perspective, we propose two general principles: 1) monotonic decreasing and 2) margin probability penalty, for designing new margin loss functions. Unlike methods optimized with single comparison metric, we provide a new perspective to treat open set face recognition as a problem of information transmission. And the generalization capability for face embedding is gained with more clean information. An auto-encoder architecture called Linear-Auto-TS-Encoder(LATSE) is proposed to corroborate this finding. Extensive experiments on several benchmarks demonstrate that LATSE help face embedding to gain more generalization capability and it boosted the single model performance with open training dataset to more than $99\%$ on MegaFace test.
Joint Deep Learning of Facial Expression Synthesis and Recognition
Feb 06, 2020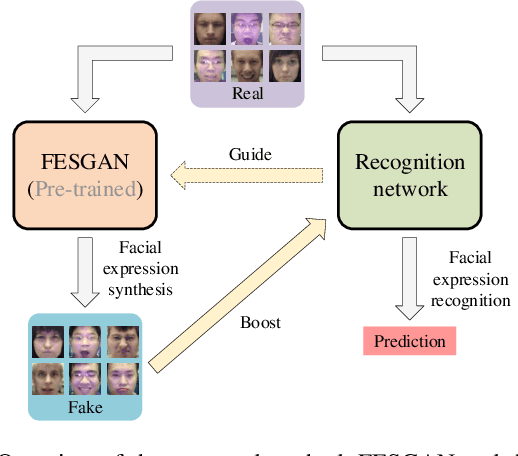
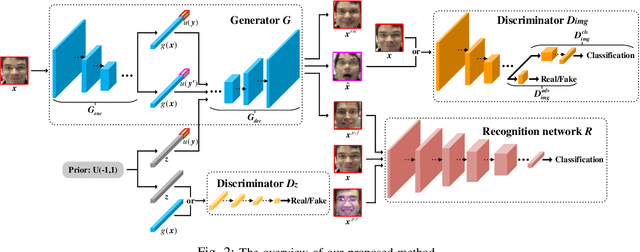
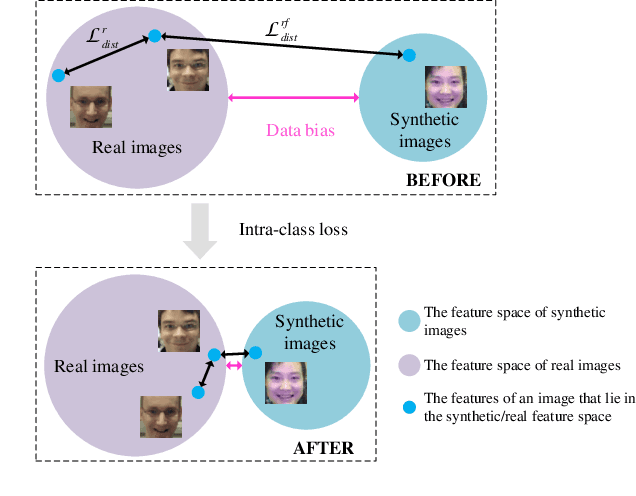

Recently, deep learning based facial expression recognition (FER) methods have attracted considerable attention and they usually require large-scale labelled training data. Nonetheless, the publicly available facial expression databases typically contain a small amount of labelled data. In this paper, to overcome the above issue, we propose a novel joint deep learning of facial expression synthesis and recognition method for effective FER. More specifically, the proposed method involves a two-stage learning procedure. Firstly, a facial expression synthesis generative adversarial network (FESGAN) is pre-trained to generate facial images with different facial expressions. To increase the diversity of the training images, FESGAN is elaborately designed to generate images with new identities from a prior distribution. Secondly, an expression recognition network is jointly learned with the pre-trained FESGAN in a unified framework. In particular, the classification loss computed from the recognition network is used to simultaneously optimize the performance of both the recognition network and the generator of FESGAN. Moreover, in order to alleviate the problem of data bias between the real images and the synthetic images, we propose an intra-class loss with a novel real data-guided back-propagation (RDBP) algorithm to reduce the intra-class variations of images from the same class, which can significantly improve the final performance. Extensive experimental results on public facial expression databases demonstrate the superiority of the proposed method compared with several state-of-the-art FER methods.
Deep Frequent Spatial Temporal Learning for Face Anti-Spoofing
Jan 20, 2020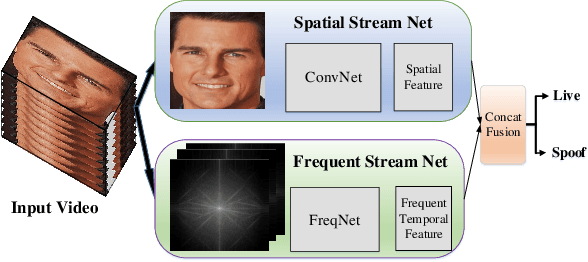
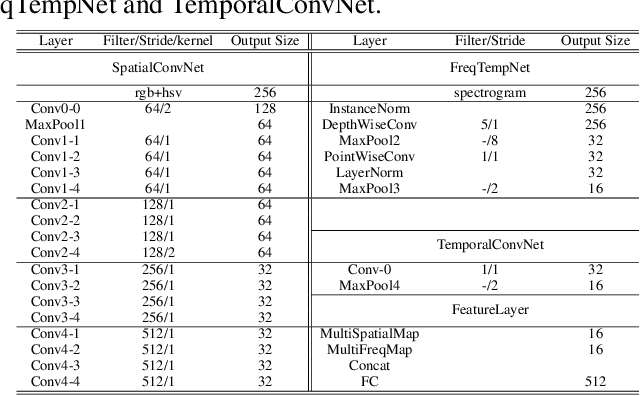
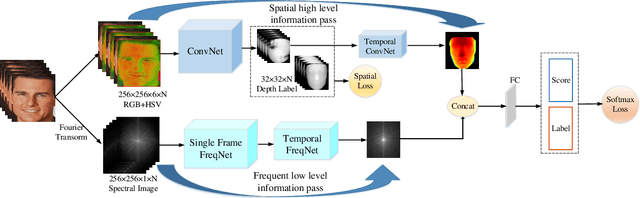
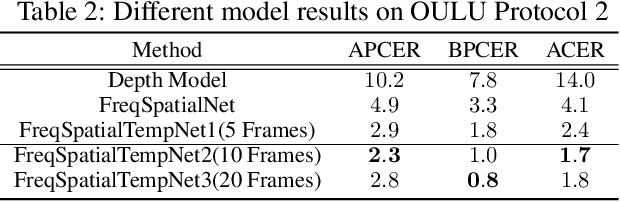
Face anti-spoofing is crucial for the security of face recognition system, by avoiding invaded with presentation attack. Previous works have shown the effectiveness of using depth and temporal supervision for this task. However, depth supervision is often considered only in a single frame, and temporal supervision is explored by utilizing certain signals which is not robust to the change of scenes. In this work, motivated by two stream ConvNets, we propose a novel two stream FreqSaptialTemporalNet for face anti-spoofing which simultaneously takes advantage of frequent, spatial and temporal information. Compared with existing methods which mine spoofing cues in multi-frame RGB image, we make multi-frame spectrum image as one input stream for the discriminative deep neural network, encouraging the primary difference between live and fake video to be automatically unearthed. Extensive experiments show promising improvement results using the proposed architecture. Meanwhile, we proposed a concise method to obtain a large amount of spoofing training data by utilizing a frequent augmentation pipeline, which contributes detail visualization between live and fake images as well as data insufficiency issue when training large networks.
Multi-Level Network for High-Speed Multi-Person Pose Estimation
Nov 26, 2019
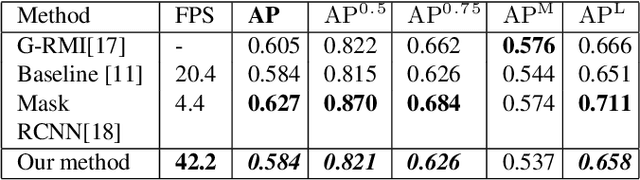
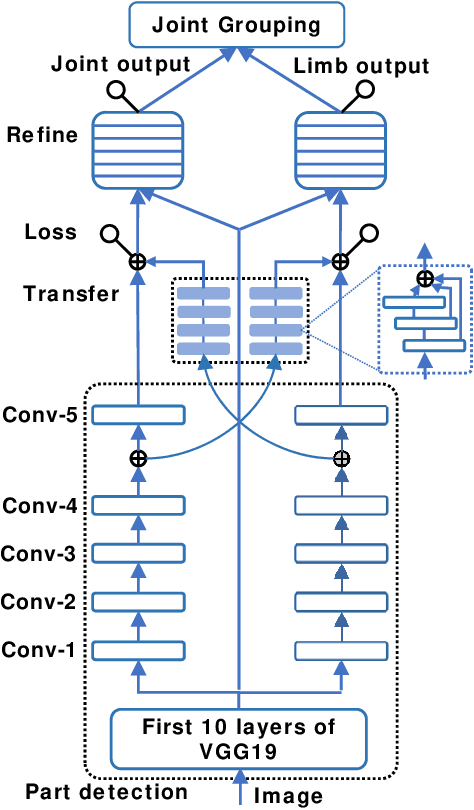

In multi-person pose estimation, the left/right joint type discrimination is always a hard problem because of the similar appearance. Traditionally, we solve this problem by stacking multiple refinement modules to increase network's receptive fields and capture more global context, which can also increase a great amount of computation. In this paper, we propose a Multi-level Network (MLN) that learns to aggregate features from lower-level (left/right information), upper-level (localization information), joint-limb level (complementary information) and global-level (context) information for discrimination of joint type. Through feature reuse and its intra-relation, MLN can attain comparable performance to other conventional methods while runtime speed retains at 42.2 FPS.
FollowMeUp Sports: New Benchmark for 2D Human Keypoint Recognition
Nov 19, 2019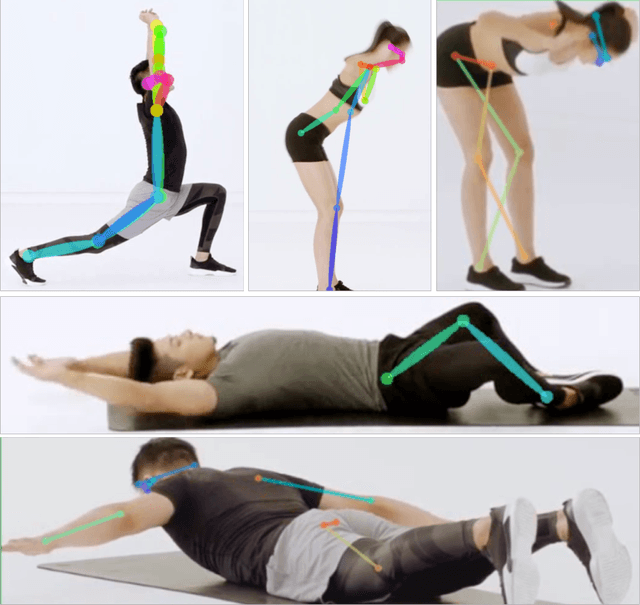

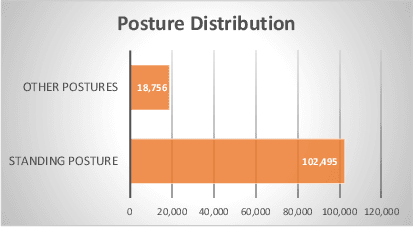
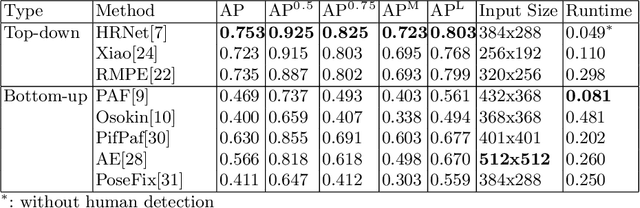
Human pose estimation has made significant advancement in recent years. However, the existing datasets are limited in their coverage of pose variety. In this paper, we introduce a novel benchmark FollowMeUp Sports that makes an important advance in terms of specific postures, self-occlusion and class balance, a contribution that we feel is required for future development in human body models. This comprehensive dataset was collected using an established taxonomy of over 200 standard workout activities with three different shot angles. The collected videos cover a wider variety of specific workout activities than previous datasets including push-up, squat and body moving near the ground with severe self-occlusion or occluded by some sport equipment and outfits. Given these rich images, we perform a detailed analysis of the leading human pose estimation approaches gaining insights for the success and failures of these methods.
Selecting Biomarkers for building optimal treatment selection rules using Kernel Machines
Jun 06, 2019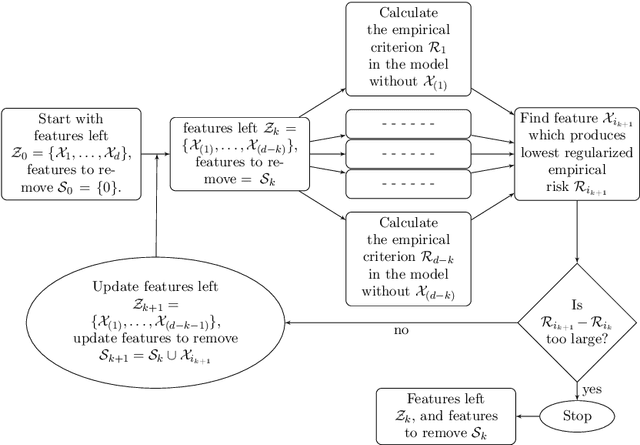
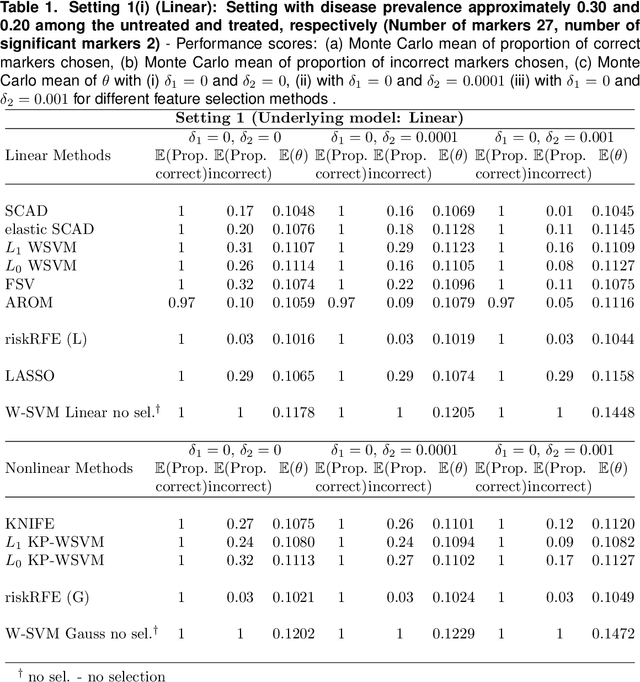
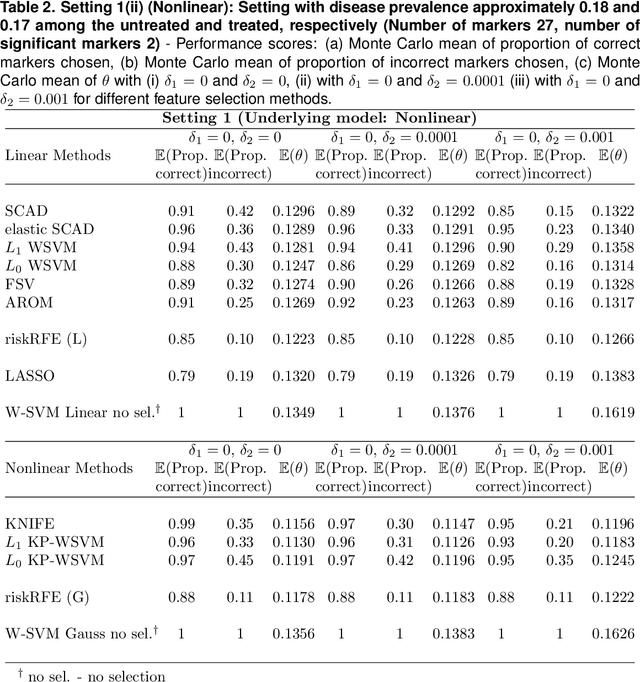

Optimal biomarker combinations for treatment-selection can be derived by minimizing total burden to the population caused by the targeted disease and its treatment. However, when multiple biomarkers are present, including all in the model can be expensive and hurt model performance. To remedy this, we consider feature selection in optimization by minimizing an extended total burden that additionally incorporates biomarker measurement costs. Formulating it as a 0-norm penalized weighted classification, we develop various procedures for estimating linear and nonlinear combinations. Through simulations and a real data example, we demonstrate the importance of incorporating feature-selection and marker cost when deriving treatment-selection rules.
Optimization Design of Decentralized Control for Complex Decentralized Systems
Sep 03, 2018
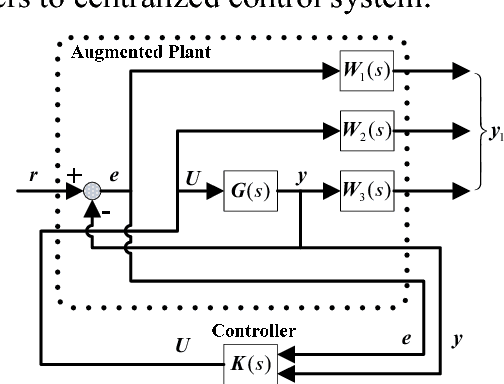
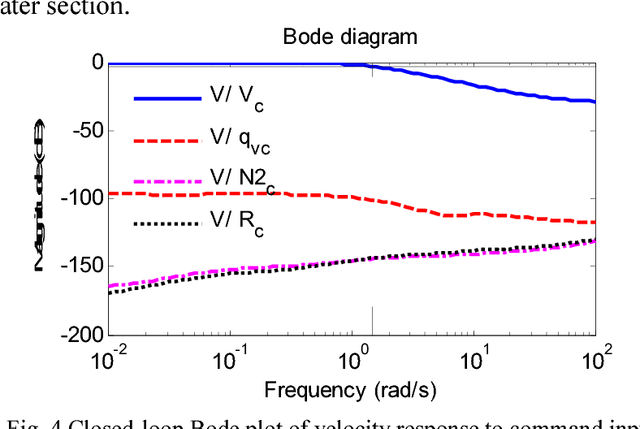
A new method is developed to deal with the problem that a complex decentralized control system needs to keep centralized control performance. The systematic procedure emphasizes quickly finding the decentralized subcontrollers that matching the closed-loop performance and robustness characteristics of the centralized controller, which is featured by the fact that GA is used to optimize the design of centralized H-infinity controller K(s) and decentralized engine subcontroller KT(s), and that only one interface variable needs to satisfy decentralized control system requirement according to the proposed selection principle. The optimization design is motivated by the implementation issues where it is desirable to reduce the time in trial and error process and accurately find the best decentralized subcontrollers. The method is applied to decentralized control system design for a short takeoff and landing fighter. By comparing the simulation results of the decentralized control system with those of the centralized control system, the target of the decentralized control attains the performance and robustness of centralized control is validated.
IR2VI: Enhanced Night Environmental Perception by Unsupervised Thermal Image Translation
Jun 25, 2018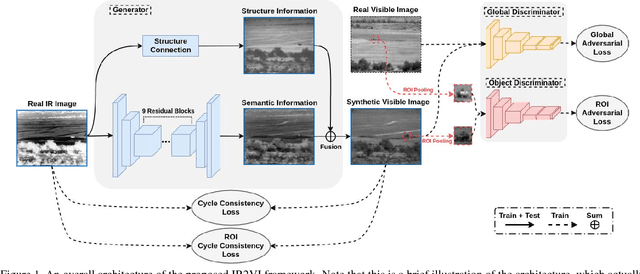



Context enhancement is critical for night vision (NV) applications, especially for the dark night situation without any artificial lights. In this paper, we present the infrared-to-visual (IR2VI) algorithm, a novel unsupervised thermal-to-visible image translation framework based on generative adversarial networks (GANs). IR2VI is able to learn the intrinsic characteristics from VI images and integrate them into IR images. Since the existing unsupervised GAN-based image translation approaches face several challenges, such as incorrect mapping and lack of fine details, we propose a structure connection module and a region-of-interest (ROI) focal loss method to address the current limitations. Experimental results show the superiority of the IR2VI algorithm over baseline methods.