 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries
Oct 13, 2021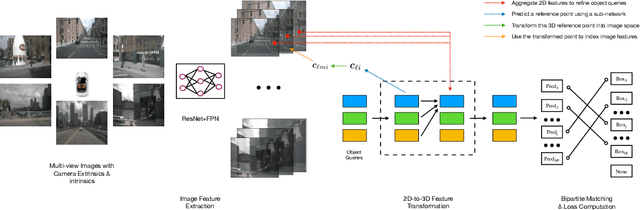
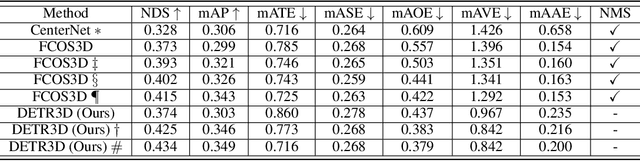
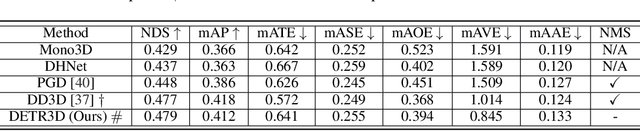
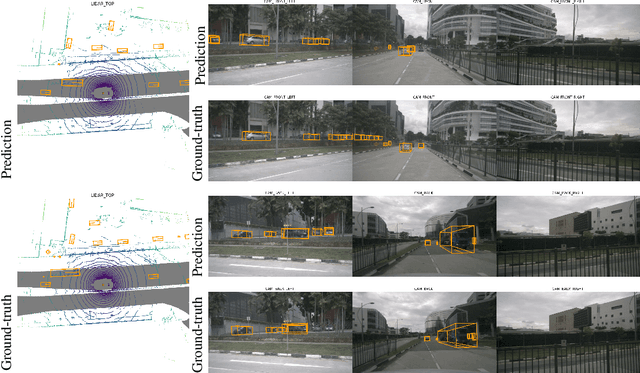
We introduce a framework for multi-camera 3D object detection. In contrast to existing works, which estimate 3D bounding boxes directly from monocular images or use depth prediction networks to generate input for 3D object detection from 2D information, our method manipulates predictions directly in 3D space. Our architecture extracts 2D features from multiple camera images and then uses a sparse set of 3D object queries to index into these 2D features, linking 3D positions to multi-view images using camera transformation matrices. Finally, our model makes a bounding box prediction per object query, using a set-to-set loss to measure the discrepancy between the ground-truth and the prediction. This top-down approach outperforms its bottom-up counterpart in which object bounding box prediction follows per-pixel depth estimation, since it does not suffer from the compounding error introduced by a depth prediction model. Moreover, our method does not require post-processing such as non-maximum suppression, dramatically improving inference speed. We achieve state-of-the-art performance on the nuScenes autonomous driving benchmark.
HDMapNet: An Online HD Map Construction and Evaluation Framework
Jul 15, 2021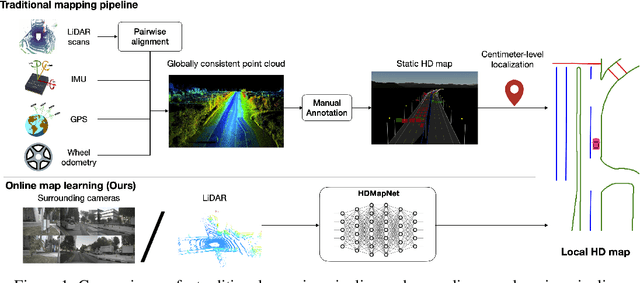

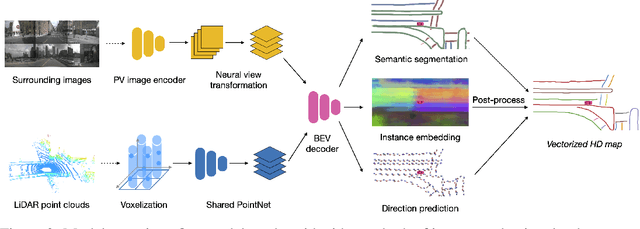

High-definition map (HD map) construction is a crucial problem for autonomous driving. This problem typically involves collecting high-quality point clouds, fusing multiple point clouds of the same scene, annotating map elements, and updating maps constantly. This pipeline, however, requires a vast amount of human efforts and resources which limits its scalability. Additionally, traditional HD maps are coupled with centimeter-level accurate localization which is unreliable in many scenarios. In this paper, we argue that online map learning, which dynamically constructs the HD maps based on local sensor observations, is a more scalable way to provide semantic and geometry priors to self-driving vehicles than traditional pre-annotated HD maps. Meanwhile, we introduce an online map learning method, titled HDMapNet. It encodes image features from surrounding cameras and/or point clouds from LiDAR, and predicts vectorized map elements in the bird's-eye view. We benchmark HDMapNet on the nuScenes dataset and show that in all settings, it performs better than baseline methods. Of note, our fusion-based HDMapNet outperforms existing methods by more than 50% in all metrics. To accelerate future research, we develop customized metrics to evaluate map learning performance, including both semantic-level and instance-level ones. By introducing this method and metrics, we invite the community to study this novel map learning problem. We will release our code and evaluation kit to facilitate future development.
Fine-Grained Car Detection for Visual Census Estimation
Sep 07, 2017
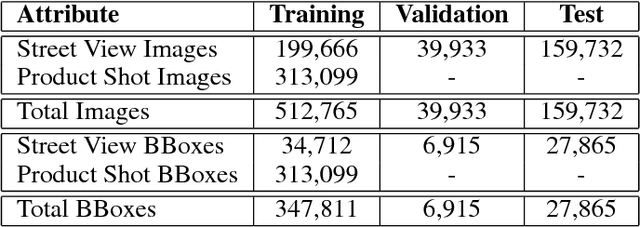
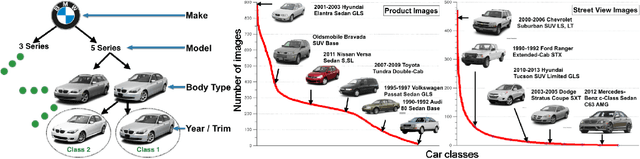

Targeted socioeconomic policies require an accurate understanding of a country's demographic makeup. To that end, the United States spends more than 1 billion dollars a year gathering census data such as race, gender, education, occupation and unemployment rates. Compared to the traditional method of collecting surveys across many years which is costly and labor intensive, data-driven, machine learning driven approaches are cheaper and faster--with the potential ability to detect trends in close to real time. In this work, we leverage the ubiquity of Google Street View images and develop a computer vision pipeline to predict income, per capita carbon emission, crime rates and other city attributes from a single source of publicly available visual data. We first detect cars in 50 million images across 200 of the largest US cities and train a model to predict demographic attributes using the detected cars. To facilitate our work, we have collected the largest and most challenging fine-grained dataset reported to date consisting of over 2600 classes of cars comprised of images from Google Street View and other web sources, classified by car experts to account for even the most subtle of visual differences. We use this data to construct the largest scale fine-grained detection system reported to date. Our prediction results correlate well with ground truth income data (r=0.82), Massachusetts department of vehicle registration, and sources investigating crime rates, income segregation, per capita carbon emission, and other market research. Finally, we learn interesting relationships between cars and neighborhoods allowing us to perform the first large scale sociological analysis of cities using computer vision techniques.
Using Deep Learning and Google Street View to Estimate the Demographic Makeup of the US
Mar 02, 2017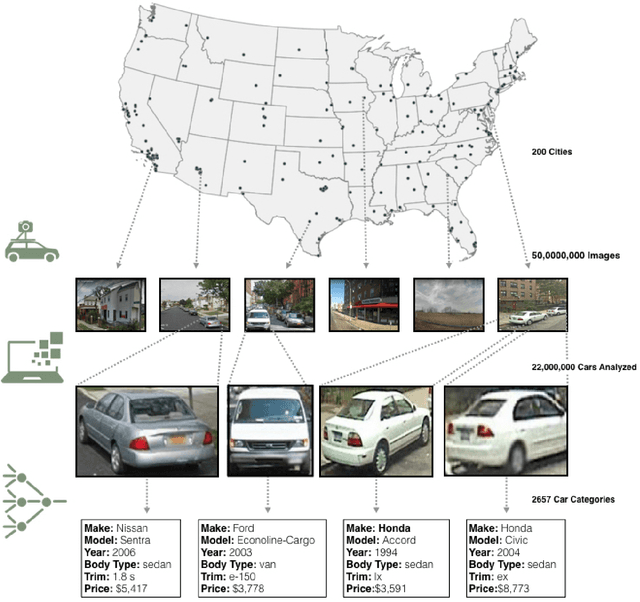
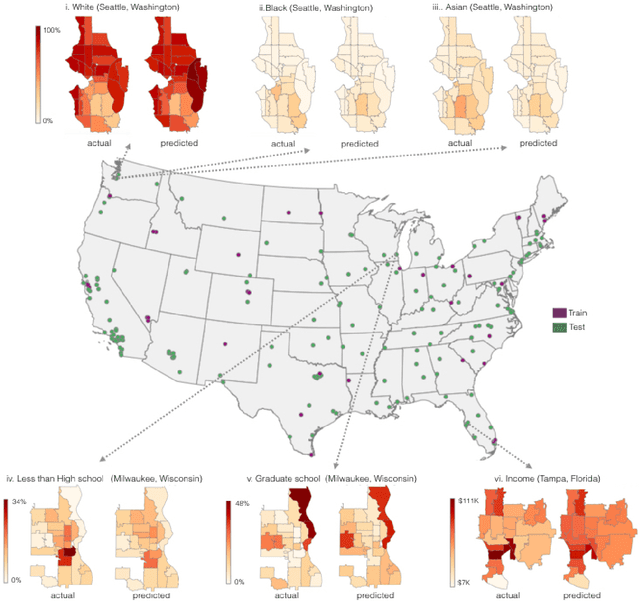
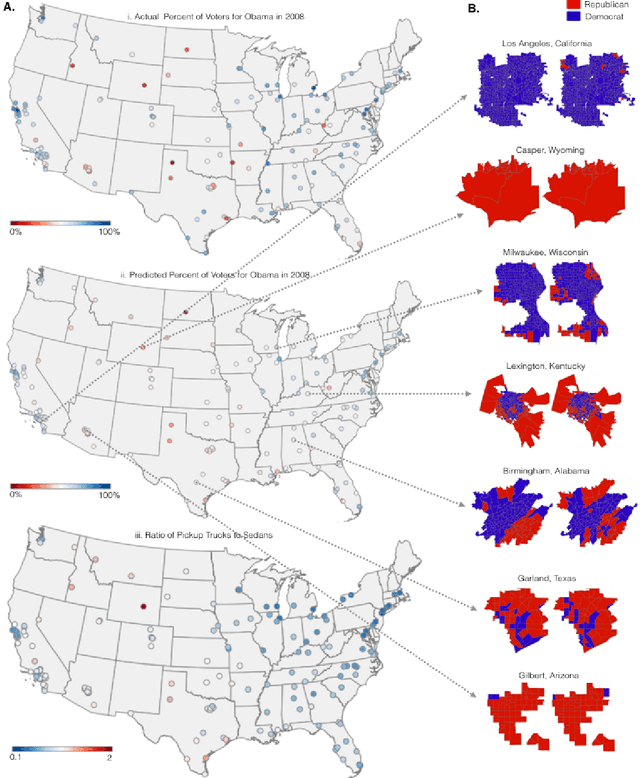
The United States spends more than $1B each year on initiatives such as the American Community Survey (ACS), a labor-intensive door-to-door study that measures statistics relating to race, gender, education, occupation, unemployment, and other demographic factors. Although a comprehensive source of data, the lag between demographic changes and their appearance in the ACS can exceed half a decade. As digital imagery becomes ubiquitous and machine vision techniques improve, automated data analysis may provide a cheaper and faster alternative. Here, we present a method that determines socioeconomic trends from 50 million images of street scenes, gathered in 200 American cities by Google Street View cars. Using deep learning-based computer vision techniques, we determined the make, model, and year of all motor vehicles encountered in particular neighborhoods. Data from this census of motor vehicles, which enumerated 22M automobiles in total (8% of all automobiles in the US), was used to accurately estimate income, race, education, and voting patterns, with single-precinct resolution. (The average US precinct contains approximately 1000 people.) The resulting associations are surprisingly simple and powerful. For instance, if the number of sedans encountered during a 15-minute drive through a city is higher than the number of pickup trucks, the city is likely to vote for a Democrat during the next Presidential election (88% chance); otherwise, it is likely to vote Republican (82%). Our results suggest that automated systems for monitoring demographic trends may effectively complement labor-intensive approaches, with the potential to detect trends with fine spatial resolution, in close to real time.
A Novel Approach for Stable Selection of Informative Redundant Features from High Dimensional fMRI Data
May 25, 2016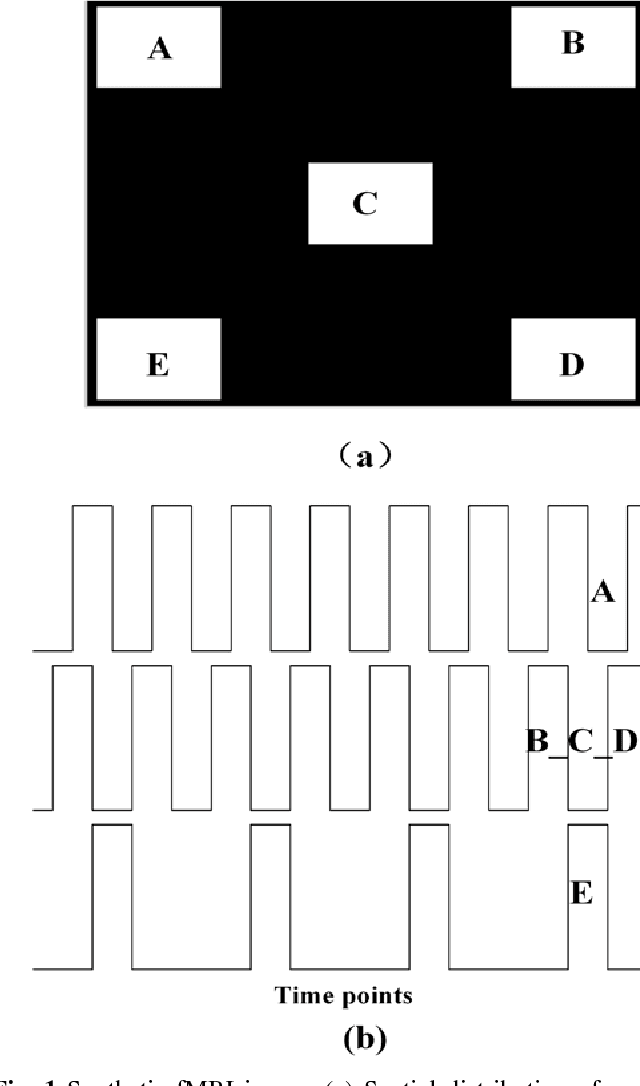
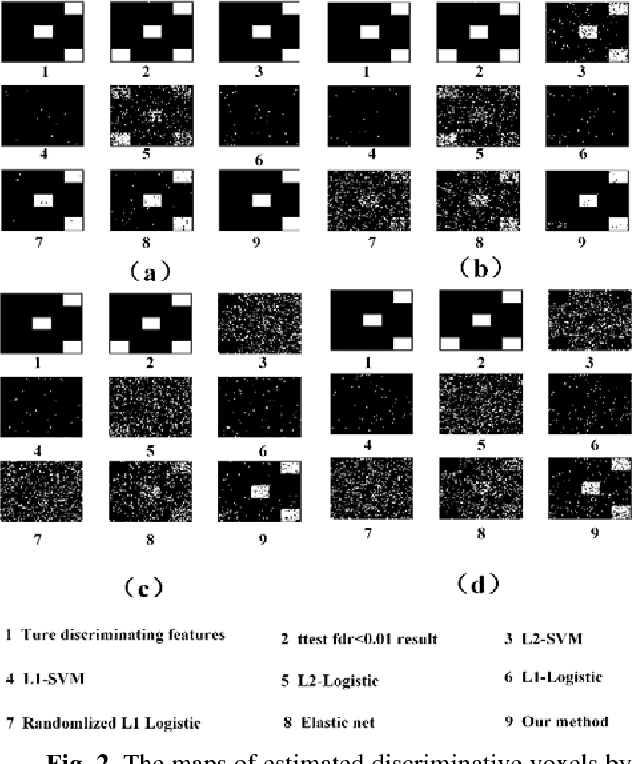
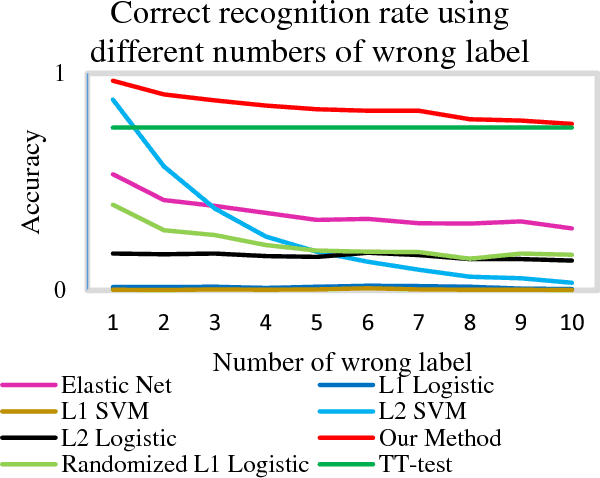
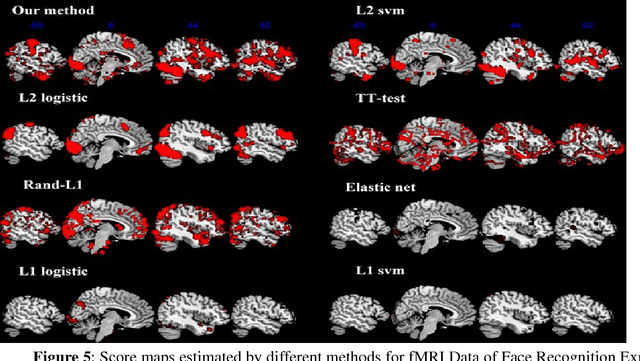
Feature selection is among the most important components because it not only helps enhance the classification accuracy, but also or even more important provides potential biomarker discovery. However, traditional multivariate methods is likely to obtain unstable and unreliable results in case of an extremely high dimensional feature space and very limited training samples, where the features are often correlated or redundant. In order to improve the stability, generalization and interpretations of the discovered potential biomarker and enhance the robustness of the resultant classifier, the redundant but informative features need to be also selected. Therefore we introduced a novel feature selection method which combines a recent implementation of the stability selection approach and the elastic net approach. The advantage in terms of better control of false discoveries and missed discoveries of our approach, and the resulted better interpretability of the obtained potential biomarker is verified in both synthetic and real fMRI experiments. In addition, we are among the first to demonstrate the robustness of feature selection benefiting from the incorporation of stability selection and also among the first to demonstrate the possible unrobustness of the classical univariate two-sample t-test method. Specifically, we show the robustness of our feature selection results in existence of noisy (wrong) training labels, as well as the robustness of the resulted classifier based on our feature selection results in the existence of data variation, demonstrated by a multi-center attention-deficit/hyperactivity disorder (ADHD) fMRI data.
Support Driven Wavelet Frame-based Image Deblurring
Mar 26, 2016
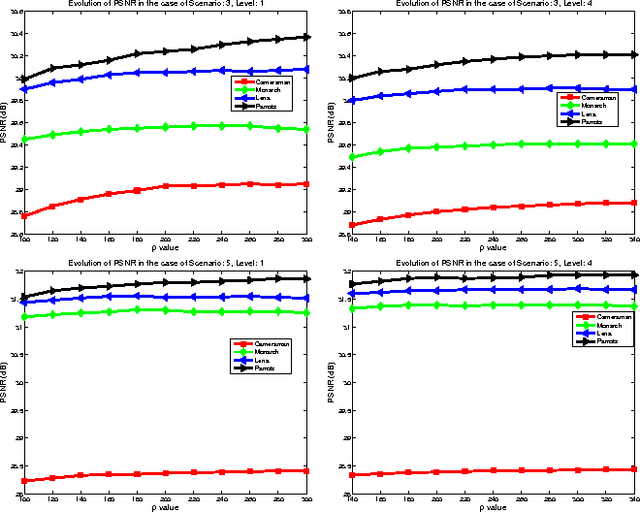
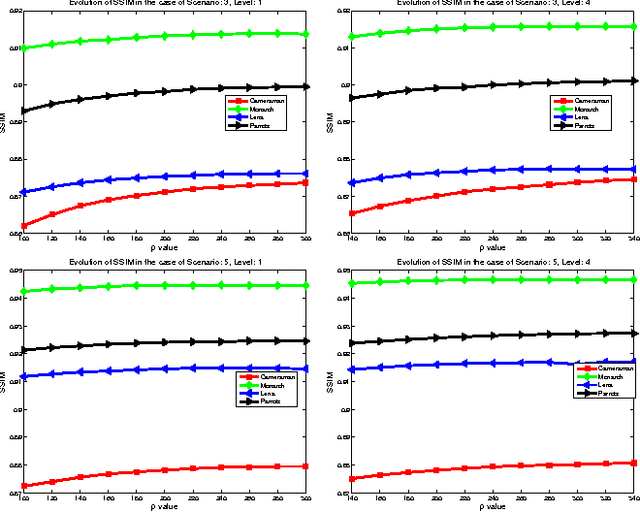
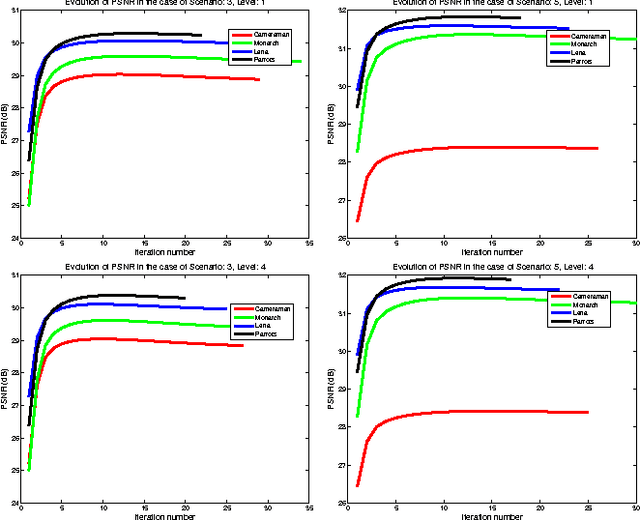
The wavelet frame systems have been playing an active role in image restoration and many other image processing fields over the past decades, owing to the good capability of sparsely approximating piece-wise smooth functions such as images. In this paper, we propose a novel wavelet frame based sparse recovery model called \textit{Support Driven Sparse Regularization} (SDSR) for image deblurring, where the partial support information of frame coefficients is attained via a self-learning strategy and exploited via the proposed truncated $\ell_0$ regularization. Moreover, the state-of-the-art image restoration methods can be naturally incorporated into our proposed wavelet frame based sparse recovery framework. In particular, in order to achieve reliable support estimation of the frame coefficients, we make use of the state-of-the-art image restoration result such as that from the IDD-BM3D method as the initial reference image for support estimation. Our extensive experimental results have shown convincing improvements over existing state-of-the-art deblurring methods.
Wavelet Frame Based Image Restoration Using Sparsity, Nonlocal and Support Prior of Frame Coefficients
Oct 10, 2015
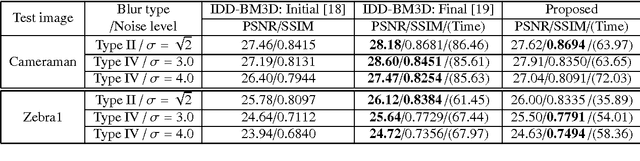
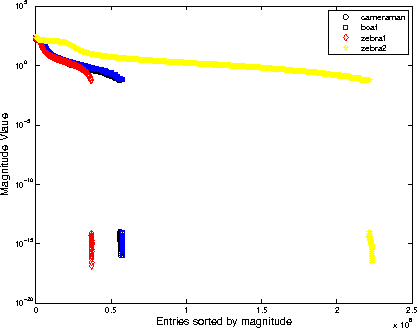

The wavelet frame systems have been widely investigated and applied for image restoration and many other image processing problems over the past decades, attributing to their good capability of sparsely approximating piece-wise smooth functions such as images. Most wavelet frame based models exploit the $l_1$ norm of frame coefficients for a sparsity constraint in the past. The authors in \cite{ZhangY2013, Dong2013} proposed an $l_0$ minimization model, where the $l_0$ norm of wavelet frame coefficients is penalized instead, and have demonstrated that significant improvements can be achieved compared to the commonly used $l_1$ minimization model. Very recently, the authors in \cite{Chen2015} proposed $l_0$-$l_2$ minimization model, where the nonlocal prior of frame coefficients is incorporated. This model proved to outperform the single $l_0$ minimization based model in terms of better recovered image quality. In this paper, we propose a truncated $l_0$-$l_2$ minimization model which combines sparsity, nonlocal and support prior of the frame coefficients. The extensive experiments have shown that the recovery results from the proposed regularization method performs better than existing state-of-the-art wavelet frame based methods, in terms of edge enhancement and texture preserving performance.
Randomized Structural Sparsity based Support Identification with Applications to Locating Activated or Discriminative Brain Areas: A Multi-center Reproducibility Study
Jun 07, 2015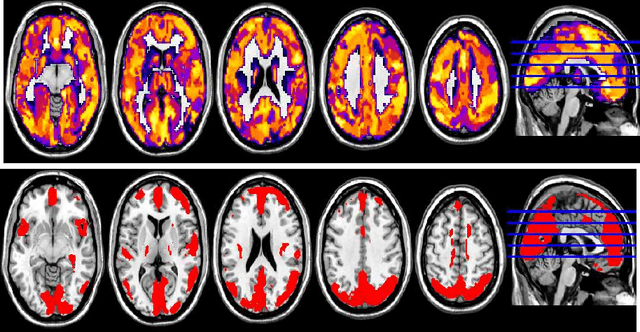
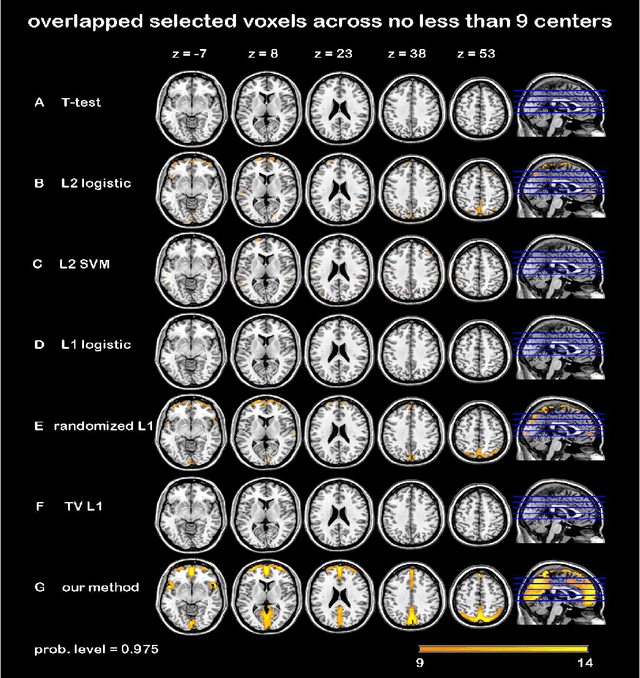
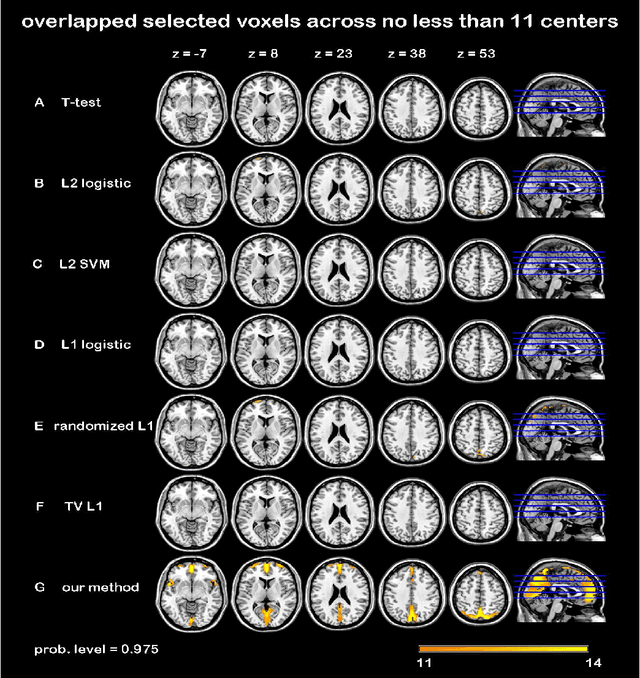
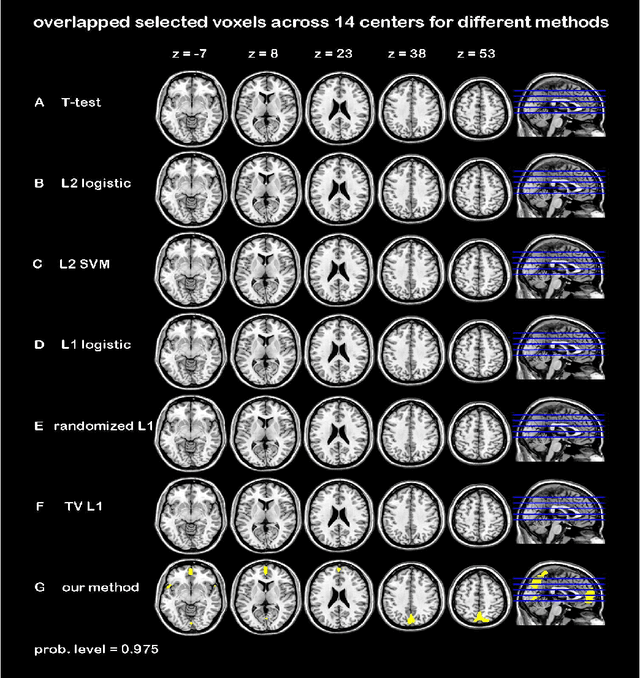
In this paper, we focus on how to locate the relevant or discriminative brain regions related with external stimulus or certain mental decease, which is also called support identification, based on the neuroimaging data. The main difficulty lies in the extremely high dimensional voxel space and relatively few training samples, easily resulting in an unstable brain region discovery (or called feature selection in context of pattern recognition). When the training samples are from different centers and have betweencenter variations, it will be even harder to obtain a reliable and consistent result. Corresponding, we revisit our recently proposed algorithm based on stability selection and structural sparsity. It is applied to the multi-center MRI data analysis for the first time. A consistent and stable result is achieved across different centers despite the between-center data variation while many other state-of-the-art methods such as two sample t-test fail. Moreover, we have empirically showed that the performance of this algorithm is robust and insensitive to several of its key parameters. In addition, the support identification results on both functional MRI and structural MRI are interpretable and can be the potential biomarkers.
Randomized Structural Sparsity via Constrained Block Subsampling for Improved Sensitivity of Discriminative Voxel Identification
Jun 07, 2015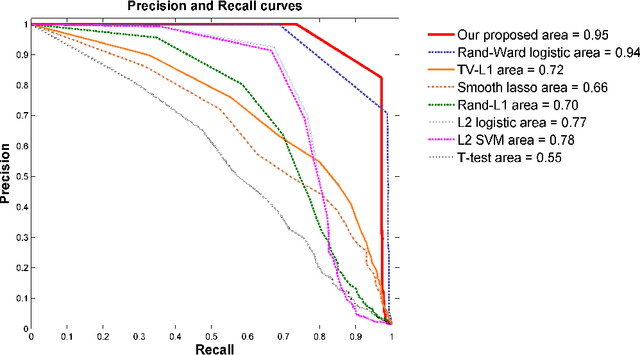

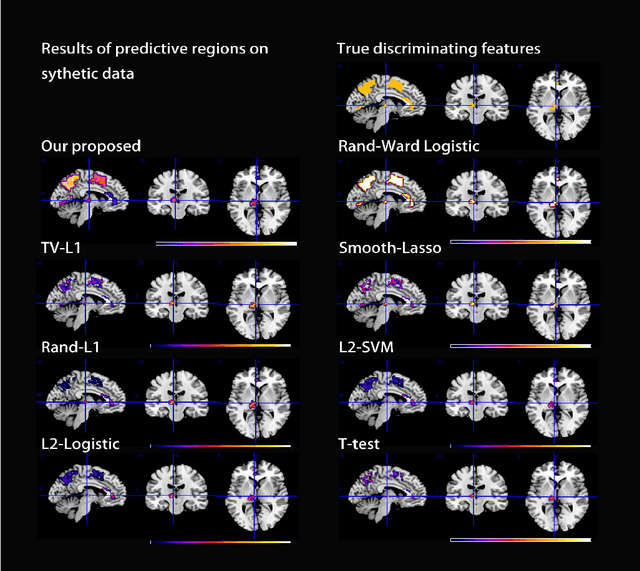

In this paper, we consider voxel selection for functional Magnetic Resonance Imaging (fMRI) brain data with the aim of finding a more complete set of probably correlated discriminative voxels, thus improving interpretation of the discovered potential biomarkers. The main difficulty in doing this is an extremely high dimensional voxel space and few training samples, resulting in unreliable feature selection. In order to deal with the difficulty, stability selection has received a great deal of attention lately, especially due to its finite sample control of false discoveries and transparent principle for choosing a proper amount of regularization. However, it fails to make explicit use of the correlation property or structural information of these discriminative features and leads to large false negative rates. In other words, many relevant but probably correlated discriminative voxels are missed. Thus, we propose a new variant on stability selection "randomized structural sparsity", which incorporates the idea of structural sparsity. Numerical experiments demonstrate that our method can be superior in controlling for false negatives while also keeping the control of false positives inherited from stability selection.
Multi-stage Multi-task feature learning via adaptive threshold
Jun 02, 2015


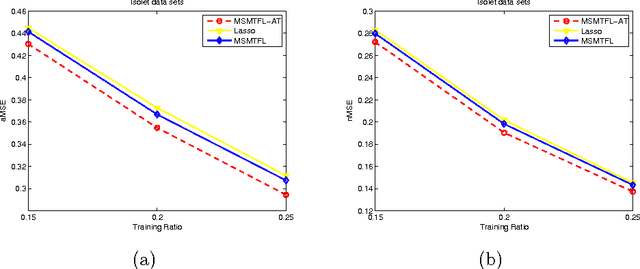
Multi-task feature learning aims to identity the shared features among tasks to improve generalization. It has been shown that by minimizing non-convex learning models, a better solution than the convex alternatives can be obtained. Therefore, a non-convex model based on the capped-$\ell_{1},\ell_{1}$ regularization was proposed in \cite{Gong2013}, and a corresponding efficient multi-stage multi-task feature learning algorithm (MSMTFL) was presented. However, this algorithm harnesses a prescribed fixed threshold in the definition of the capped-$\ell_{1},\ell_{1}$ regularization and the lack of adaptivity might result in suboptimal performance. In this paper we propose to employ an adaptive threshold in the capped-$\ell_{1},\ell_{1}$ regularized formulation, where the corresponding variant of MSMTFL will incorporate an additional component to adaptively determine the threshold value. This variant is expected to achieve a better feature selection performance over the original MSMTFL algorithm. In particular, the embedded adaptive threshold component comes from our previously proposed iterative support detection (ISD) method \cite{Wang2010}. Empirical studies on both synthetic and real-world data sets demonstrate the effectiveness of this new variant over the original MSMTFL.