 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedXIAOHE: A Comprehensive Recipe for Building Medical MLLMs
Feb 16, 2026We present MedXIAOHE, a medical vision-language foundation model designed to advance general-purpose medical understanding and reasoning in real-world clinical applications. MedXIAOHE achieves state-of-the-art performance across diverse medical benchmarks and surpasses leading closed-source multimodal systems on multiple capabilities. To achieve this, we propose an entity-aware continual pretraining framework that organizes heterogeneous medical corpora to broaden knowledge coverage and reduce long-tail gaps (e.g., rare diseases). For medical expert-level reasoning and interaction, MedXIAOHE incorporates diverse medical reasoning patterns via reinforcement learning and tool-augmented agentic training, enabling multi-step diagnostic reasoning with verifiable decision traces. To improve reliability in real-world use, MedXIAOHE integrates user-preference rubrics, evidence-grounded reasoning, and low-hallucination long-form report generation, with improved adherence to medical instructions. We release this report to document our practical design choices, scaling insights, and evaluation framework, hoping to inspire further research.
SynapseRoute: An Auto-Route Switching Framework on Dual-State Large Language Model
Jul 03, 2025



With the widespread adoption of large language models (LLMs) in practical applications, selecting an appropriate model requires balancing not only performance but also operational cost. The emergence of reasoning-capable models has further widened the cost gap between "thinking" (high reasoning) and "non-thinking" (fast, low-cost) modes. In this work, we reveal that approximately 58% of medical questions can be accurately answered by the non-thinking mode alone, without requiring the high-cost reasoning process. This highlights a clear dichotomy in problem complexity and suggests that dynamically routing queries to the appropriate mode based on complexity could optimize accuracy, cost-efficiency, and overall user experience. Based on this, we further propose SynapseRoute, a machine learning-based dynamic routing framework that intelligently assigns input queries to either thinking or non-thinking modes. Experimental results on several medical datasets demonstrate that SynapseRoute not only improves overall accuracy (0.8390 vs. 0.8272) compared to the thinking mode alone but also reduces inference time by 36.8% and token consumption by 39.66%. Importantly, qualitative analysis indicates that over-reasoning on simpler queries can lead to unnecessary delays and even decreased accuracy, a pitfall avoided by our adaptive routing. Finally, this work further introduces the Accuracy-Inference-Token (AIT) index to comprehensively evaluate the trade-offs among accuracy, latency, and token cost.
Align and Surpass Human Camouflaged Perception: Visual Refocus Reinforcement Fine-Tuning
May 26, 2025



Current multi-modal models exhibit a notable misalignment with the human visual system when identifying objects that are visually assimilated into the background. Our observations reveal that these multi-modal models cannot distinguish concealed objects, demonstrating an inability to emulate human cognitive processes which effectively utilize foreground-background similarity principles for visual analysis. To analyze this hidden human-model visual thinking discrepancy, we build a visual system that mimicks human visual camouflaged perception to progressively and iteratively `refocus' visual concealed content. The refocus is a progressive guidance mechanism enabling models to logically localize objects in visual images through stepwise reasoning. The localization process of concealed objects requires hierarchical attention shifting with dynamic adjustment and refinement of prior cognitive knowledge. In this paper, we propose a visual refocus reinforcement framework via the policy optimization algorithm to encourage multi-modal models to think and refocus more before answering, and achieve excellent reasoning abilities to align and even surpass human camouflaged perception systems. Our extensive experiments on camouflaged perception successfully demonstrate the emergence of refocus visual phenomena, characterized by multiple reasoning tokens and dynamic adjustment of the detection box. Besides, experimental results on both camouflaged object classification and detection tasks exhibit significantly superior performance compared to Supervised Fine-Tuning (SFT) baselines.
A Fleet of Miniature Cars for Experiments in Cooperative Driving
Feb 16, 2019

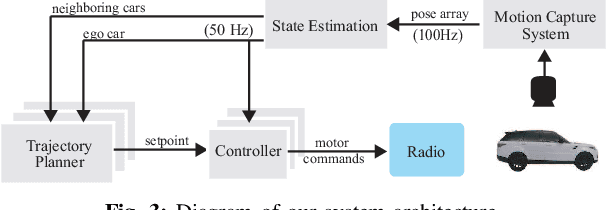
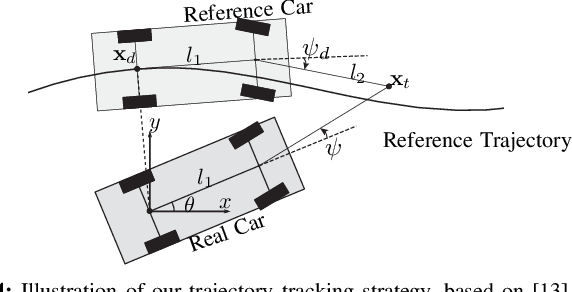
We introduce a unique experimental testbed that consists of a fleet of 16 miniature Ackermann-steering vehicles. We are motivated by a lack of available low-cost platforms to support research and education in multi-car navigation and trajectory planning. This article elaborates the design of our miniature robotic car, the Cambridge Minicar, as well as the fleet's control architecture. Our experimental testbed allows us to implement state-of-the-art driver models as well as autonomous control strategies, and test their validity in a real, physical multi-lane setup. Through experiments on our miniature highway, we are able to tangibly demonstrate the benefits of cooperative driving on multi-lane road topographies. Our setup paves the way for indoor large-fleet experimental research.