 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception-Aware Time-Optimal Planning for Quadrotor Waypoint Flight
Mar 04, 2026Agile quadrotor flight pushes the limits of control, actuation, and onboard perception. While time-optimal trajectory planning has been extensively studied, existing approaches typically neglect the tight coupling between vehicle dynamics, environmental geometry, and the visual requirements of onboard state estimation. As a result, trajectories that are dynamically feasible may fail in closed-loop execution due to degraded visual quality. This paper introduces a unified time-optimal trajectory optimization framework for vision-based quadrotors that explicitly incorporates perception constraints alongside full nonlinear dynamics, rotor actuation limits, aerodynamic effects, camera field-of-view constraints, and convex geometric gate representations. The proposed formulation solves minimum-time lap trajectories for arbitrary racetracks with diverse gate shapes and orientations, while remaining numerically robust and computationally efficient. We derive an information-theoretic position uncertainty metric to quantify visual state-estimation quality and integrate it into the planner through three perception objectives: position uncertainty minimization, sequential field-of-view constraints, and look-ahead alignment. This enables systematic exploration of the trade-offs between speed and perceptual reliability. To accurately track the resulting perception-aware trajectories, we develop a model predictive contouring tracking controller that separates lateral and progress errors. Experiments demonstrate real-world flight speeds up to 9.8 m/s with 0.07 m average tracking error, and closed-loop success rates improved from 55% to 100% on a challenging Split-S course. The proposed system provides a scalable benchmark for studying the fundamental limits of perception-aware, time-optimal autonomous flight.
CrownGen: Patient-customized Crown Generation via Point Diffusion Model
Dec 26, 2025



Digital crown design remains a labor-intensive bottleneck in restorative dentistry. We present \textbf{CrownGen}, a generative framework that automates patient-customized crown design using a denoising diffusion model on a novel tooth-level point cloud representation. The system employs two core components: a boundary prediction module to establish spatial priors and a diffusion-based generative module to synthesize high-fidelity morphology for multiple teeth in a single inference pass. We validated CrownGen through a quantitative benchmark on 496 external scans and a clinical study of 26 restoration cases. Results demonstrate that CrownGen surpasses state-of-the-art models in geometric fidelity and significantly reduces active design time. Clinical assessments by trained dentists confirmed that CrownGen-assisted crowns are statistically non-inferior in quality to those produced by expert technicians using manual workflows. By automating complex prosthetic modeling, CrownGen offers a scalable solution to lower costs, shorten turnaround times, and enhance patient access to high-quality dental care.
Policy Gradient Optimzation for Bayesian-Risk MDPs with General Convex Losses
Sep 19, 2025Motivated by many application problems, we consider Markov decision processes (MDPs) with a general loss function and unknown parameters. To mitigate the epistemic uncertainty associated with unknown parameters, we take a Bayesian approach to estimate the parameters from data and impose a coherent risk functional (with respect to the Bayesian posterior distribution) on the loss. Since this formulation usually does not satisfy the interchangeability principle, it does not admit Bellman equations and cannot be solved by approaches based on dynamic programming. Therefore, We propose a policy gradient optimization method, leveraging the dual representation of coherent risk measures and extending the envelope theorem to continuous cases. We then show the stationary analysis of the algorithm with a convergence rate of $O(T^{-1/2}+r^{-1/2})$, where $T$ is the number of policy gradient iterations and $r$ is the sample size of the gradient estimator. We further extend our algorithm to an episodic setting, and establish the global convergence of the extended algorithm and provide bounds on the number of iterations needed to achieve an error bound $O(\epsilon)$ in each episode.
Agentic Aerial Cinematography: From Dialogue Cues to Cinematic Trajectories
Sep 19, 2025We present Agentic Aerial Cinematography: From Dialogue Cues to Cinematic Trajectories (ACDC), an autonomous drone cinematography system driven by natural language communication between human directors and drones. The main limitation of previous drone cinematography workflows is that they require manual selection of waypoints and view angles based on predefined human intent, which is labor-intensive and yields inconsistent performance. In this paper, we propose employing large language models (LLMs) and vision foundation models (VFMs) to convert free-form natural language prompts directly into executable indoor UAV video tours. Specifically, our method comprises a vision-language retrieval pipeline for initial waypoint selection, a preference-based Bayesian optimization framework that refines poses using aesthetic feedback, and a motion planner that generates safe quadrotor trajectories. We validate ACDC through both simulation and hardware-in-the-loop experiments, demonstrating that it robustly produces professional-quality footage across diverse indoor scenes without requiring expertise in robotics or cinematography. These results highlight the potential of embodied AI agents to close the loop from open-vocabulary dialogue to real-world autonomous aerial cinematography.
Multimodal Contrastive Pretraining of CBCT and IOS for Enhanced Tooth Segmentation
Sep 09, 2025Digital dentistry represents a transformative shift in modern dental practice. The foundational step in this transformation is the accurate digital representation of the patient's dentition, which is obtained from segmented Cone-Beam Computed Tomography (CBCT) and Intraoral Scans (IOS). Despite the growing interest in digital dental technologies, existing segmentation methodologies frequently lack rigorous validation and demonstrate limited performance and clinical applicability. To the best of our knowledge, this is the first work to introduce a multimodal pretraining framework for tooth segmentation. We present ToothMCL, a Tooth Multimodal Contrastive Learning for pretraining that integrates volumetric (CBCT) and surface-based (IOS) modalities. By capturing modality-invariant representations through multimodal contrastive learning, our approach effectively models fine-grained anatomical features, enabling precise multi-class segmentation and accurate identification of F\'ed\'eration Dentaire Internationale (FDI) tooth numbering. Along with the framework, we curated CBCT-IOS3.8K, the largest paired CBCT and IOS dataset to date, comprising 3,867 patients. We then evaluated ToothMCL on a comprehensive collection of independent datasets, representing the largest and most diverse evaluation to date. Our method achieves state-of-the-art performance in both internal and external testing, with an increase of 12\% for CBCT segmentation and 8\% for IOS segmentation in the Dice Similarity Coefficient (DSC). Furthermore, ToothMCL consistently surpasses existing approaches in tooth groups and demonstrates robust generalizability across varying imaging conditions and clinical scenarios.
A Privacy-Preserving Framework for Advertising Personalization Incorporating Federated Learning and Differential Privacy
Jul 16, 2025To mitigate privacy leakage and performance issues in personalized advertising, this paper proposes a framework that integrates federated learning and differential privacy. The system combines distributed feature extraction, dynamic privacy budget allocation, and robust model aggregation to balance model accuracy, communication overhead, and privacy protection. Multi-party secure computing and anomaly detection mechanisms further enhance system resilience against malicious attacks. Experimental results demonstrate that the framework achieves dual optimization of recommendation accuracy and system efficiency while ensuring privacy, providing both a practical solution and a theoretical foundation for applying privacy protection technologies in advertisement recommendation.
Liner Shipping Network Design with Reinforcement Learning
Nov 13, 2024



This paper proposes a novel reinforcement learning framework to address the Liner Shipping Network Design Problem (LSNDP), a challenging combinatorial optimization problem focused on designing cost-efficient maritime shipping routes. Traditional methods for solving the LSNDP typically involve decomposing the problem into sub-problems, such as network design and multi-commodity flow, which are then tackled using approximate heuristics or large neighborhood search (LNS) techniques. In contrast, our approach employs a model-free reinforcement learning algorithm on the network design, integrated with a heuristic-based multi-commodity flow solver, to produce competitive results on the publicly available LINERLIB benchmark. Additionally, our method also demonstrates generalization capabilities by producing competitive solutions on the benchmark instances after training on perturbed instances.
Time-Optimal Planning for Long-Range Quadrotor Flights: An Automatic Optimal Synthesis Approach
Jul 25, 2024Time-critical tasks such as drone racing typically cover large operation areas. However, it is difficult and computationally intensive for current time-optimal motion planners to accommodate long flight distances since a large yet unknown number of knot points is required to represent the trajectory. We present a polynomial-based automatic optimal synthesis (AOS) approach that can address this challenge. Our method not only achieves superior time optimality but also maintains a consistently low computational cost across different ranges while considering the full quadrotor dynamics. First, we analyze the properties of time-optimal quadrotor maneuvers to determine the minimal number of polynomial pieces required to capture the dominant structure of time-optimal trajectories. This enables us to represent substantially long minimum-time trajectories with a minimal set of variables. Then, a robust optimization scheme is developed to handle arbitrary start and end conditions as well as intermediate waypoints. Extensive comparisons show that our approach is faster than the state-of-the-art approach by orders of magnitude with comparable time optimality. Real-world experiments further validate the quality of the resulting trajectories, demonstrating aggressive time-optimal maneuvers with a peak velocity of 8.86 m/s.
Reusing Historical Trajectories in Natural Policy Gradient via Importance Sampling: Convergence and Convergence Rate
Mar 01, 2024



Reinforcement learning provides a mathematical framework for learning-based control, whose success largely depends on the amount of data it can utilize. The efficient utilization of historical trajectories obtained from previous policies is essential for expediting policy optimization. Empirical evidence has shown that policy gradient methods based on importance sampling work well. However, existing literature often neglect the interdependence between trajectories from different iterations, and the good empirical performance lacks a rigorous theoretical justification. In this paper, we study a variant of the natural policy gradient method with reusing historical trajectories via importance sampling. We show that the bias of the proposed estimator of the gradient is asymptotically negligible, the resultant algorithm is convergent, and reusing past trajectories helps improve the convergence rate. We further apply the proposed estimator to popular policy optimization algorithms such as trust region policy optimization. Our theoretical results are verified on classical benchmarks.
Risk-averse Contextual Multi-armed Bandit Problem with Linear Payoffs
Jun 24, 2022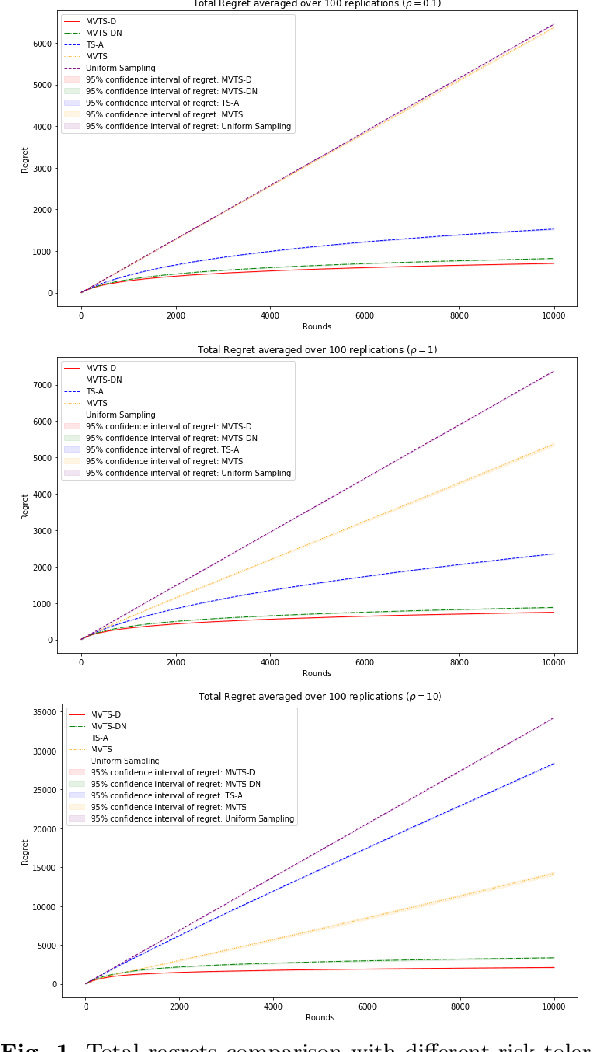
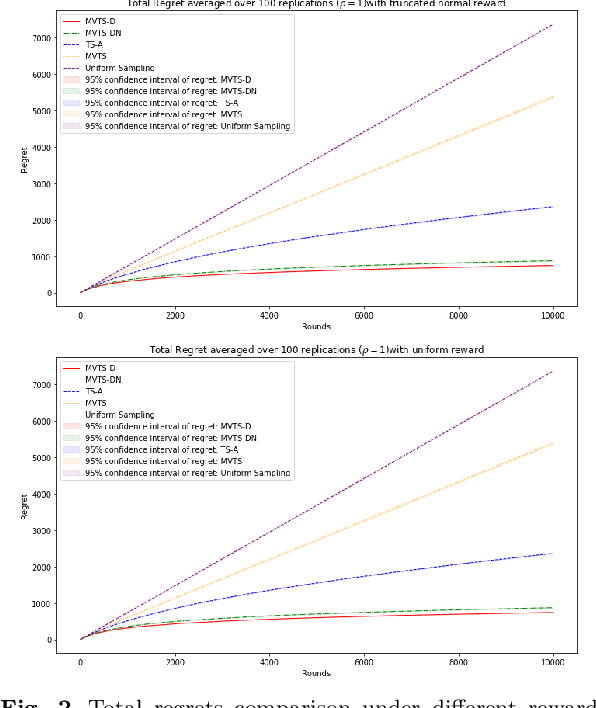
In this paper we consider the contextual multi-armed bandit problem for linear payoffs under a risk-averse criterion. At each round, contexts are revealed for each arm, and the decision maker chooses one arm to pull and receives the corresponding reward. In particular, we consider mean-variance as the risk criterion, and the best arm is the one with the largest mean-variance reward. We apply the Thompson Sampling algorithm for the disjoint model, and provide a comprehensive regret analysis for a variant of the proposed algorithm. For $T$ rounds, $K$ actions, and $d$-dimensional feature vectors, we prove a regret bound of $O((1+\rho+\frac{1}{\rho}) d\ln T \ln \frac{K}{\delta}\sqrt{d K T^{1+2\epsilon} \ln \frac{K}{\delta} \frac{1}{\epsilon}})$ that holds with probability $1-\delta$ under the mean-variance criterion with risk tolerance $\rho$, for any $0<\epsilon<\frac{1}{2}$, $0<\delta<1$. The empirical performance of our proposed algorithms is demonstrated via a portfolio selection problem.