 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrownGen: Patient-customized Crown Generation via Point Diffusion Model
Dec 26, 2025



Digital crown design remains a labor-intensive bottleneck in restorative dentistry. We present \textbf{CrownGen}, a generative framework that automates patient-customized crown design using a denoising diffusion model on a novel tooth-level point cloud representation. The system employs two core components: a boundary prediction module to establish spatial priors and a diffusion-based generative module to synthesize high-fidelity morphology for multiple teeth in a single inference pass. We validated CrownGen through a quantitative benchmark on 496 external scans and a clinical study of 26 restoration cases. Results demonstrate that CrownGen surpasses state-of-the-art models in geometric fidelity and significantly reduces active design time. Clinical assessments by trained dentists confirmed that CrownGen-assisted crowns are statistically non-inferior in quality to those produced by expert technicians using manual workflows. By automating complex prosthetic modeling, CrownGen offers a scalable solution to lower costs, shorten turnaround times, and enhance patient access to high-quality dental care.
GaTector: A Unified Framework for Gaze Object Prediction
Dec 07, 2021
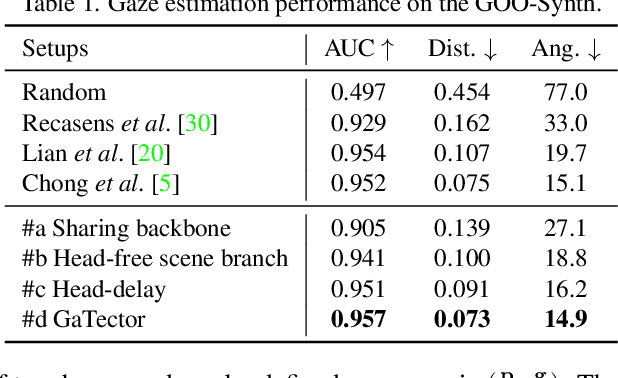
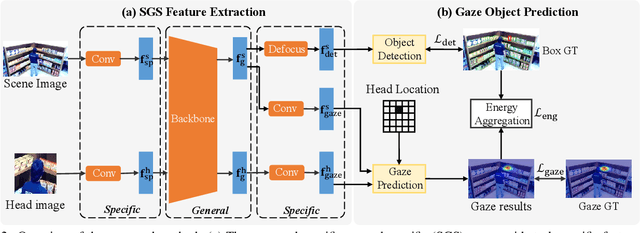
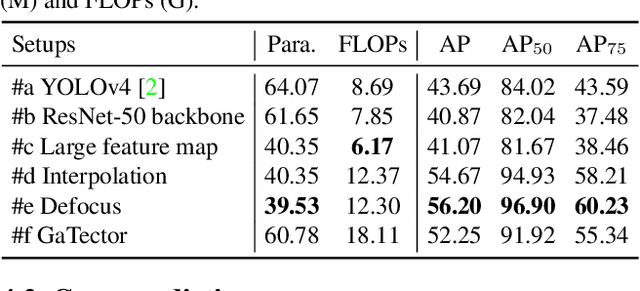
Gaze object prediction (GOP) is a newly proposed task that aims to discover the objects being stared at by humans. It is of great application significance but still lacks a unified solution framework. An intuitive solution is to incorporate an object detection branch into an existing gaze prediction method. However, previous gaze prediction methods usually use two different networks to extract features from scene image and head image, which would lead to heavy network architecture and prevent each branch from joint optimization. In this paper, we build a novel framework named GaTector to tackle the gaze object prediction problem in a unified way. Particularly, a specific-general-specific (SGS) feature extractor is firstly proposed to utilize a shared backbone to extract general features for both scene and head images. To better consider the specificity of inputs and tasks, SGS introduces two input-specific blocks before the shared backbone and three task-specific blocks after the shared backbone. Specifically, a novel defocus layer is designed to generate object-specific features for object detection task without losing information or requiring extra computations. Moreover, the energy aggregation loss is introduced to guide the gaze heatmap to concentrate on the stared box. In the end, we propose a novel mDAP metric that can reveal the difference between boxes even when they share no overlapping area. Extensive experiments on the GOO dataset verify the superiority of our method in all three tracks, i.e. object detection, gaze estimation, and gaze object prediction.