 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA2.1: Speeding Up Text Diffusion via Token Editing
Feb 09, 2026While LLaDA2.0 showcased the scaling potential of 100B-level block-diffusion models and their inherent parallelization, the delicate equilibrium between decoding speed and generation quality has remained an elusive frontier. Today, we unveil LLaDA2.1, a paradigm shift designed to transcend this trade-off. By seamlessly weaving Token-to-Token (T2T) editing into the conventional Mask-to-Token (M2T) scheme, we introduce a joint, configurable threshold-decoding scheme. This structural innovation gives rise to two distinct personas: the Speedy Mode (S Mode), which audaciously lowers the M2T threshold to bypass traditional constraints while relying on T2T to refine the output; and the Quality Mode (Q Mode), which leans into conservative thresholds to secure superior benchmark performances with manageable efficiency degrade. Furthering this evolution, underpinned by an expansive context window, we implement the first large-scale Reinforcement Learning (RL) framework specifically tailored for dLLMs, anchored by specialized techniques for stable gradient estimation. This alignment not only sharpens reasoning precision but also elevates instruction-following fidelity, bridging the chasm between diffusion dynamics and complex human intent. We culminate this work by releasing LLaDA2.1-Mini (16B) and LLaDA2.1-Flash (100B). Across 33 rigorous benchmarks, LLaDA2.1 delivers strong task performance and lightning-fast decoding speed. Despite its 100B volume, on coding tasks it attains an astounding 892 TPS on HumanEval+, 801 TPS on BigCodeBench, and 663 TPS on LiveCodeBench.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
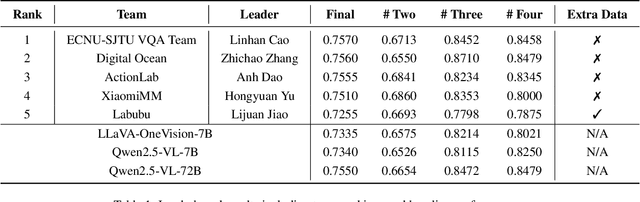
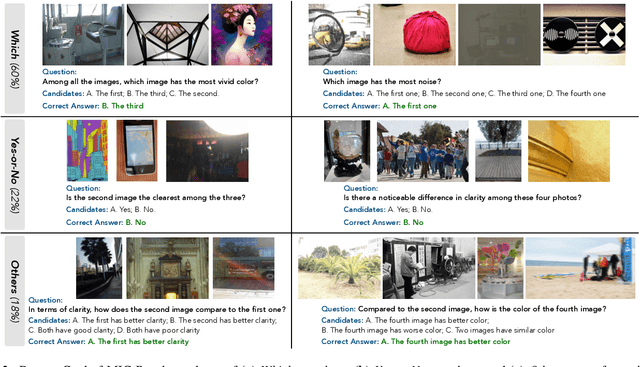
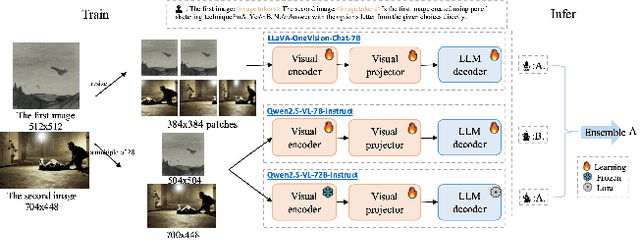
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
A Graph Traversal Based Approach to Answer Non-Aggregation Questions Over DBpedia
Aug 16, 2018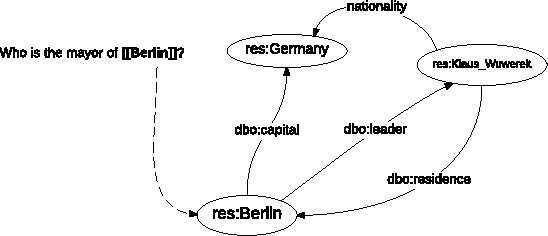

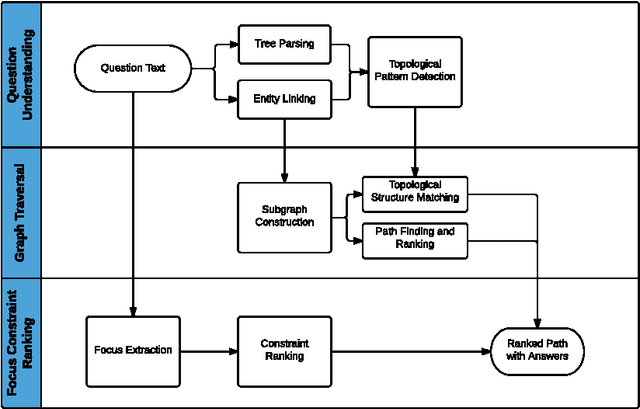

We present a question answering system over DBpedia, filling the gap between user information needs expressed in natural language and a structured query interface expressed in SPARQL over the underlying knowledge base (KB). Given the KB, our goal is to comprehend a natural language query and provide corresponding accurate answers. Focusing on solving the non-aggregation questions, in this paper, we construct a subgraph of the knowledge base from the detected entities and propose a graph traversal method to solve both the semantic item mapping problem and the disambiguation problem in a joint way. Compared with existing work, we simplify the process of query intention understanding and pay more attention to the answer path ranking. We evaluate our method on a non-aggregation question dataset and further on a complete dataset. Experimental results show that our method achieves best performance compared with several state-of-the-art systems.