 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Cross-Scale Image Alignment With Fully Spatial Correlation and Just Noticeable Difference Guidance
Nov 12, 2025Existing unsupervised image alignment methods exhibit limited accuracy and high computational complexity. To address these challenges, we propose a dense cross-scale image alignment model. It takes into account the correlations between cross-scale features to decrease the alignment difficulty. Our model supports flexible trade-offs between accuracy and efficiency by adjusting the number of scales utilized. Additionally, we introduce a fully spatial correlation module to further improve accuracy while maintaining low computational costs. We incorporate the just noticeable difference to encourage our model to focus on image regions more sensitive to distortions, eliminating noticeable alignment errors. Extensive quantitative and qualitative experiments demonstrate that our method surpasses state-of-the-art approaches.
Quaternion Infrared Visible Image Fusion
May 05, 2025Visible images provide rich details and color information only under well-lighted conditions while infrared images effectively highlight thermal targets under challenging conditions such as low visibility and adverse weather. Infrared-visible image fusion aims to integrate complementary information from infrared and visible images to generate a high-quality fused image. Existing methods exhibit critical limitations such as neglecting color structure information in visible images and performance degradation when processing low-quality color-visible inputs. To address these issues, we propose a quaternion infrared-visible image fusion (QIVIF) framework to generate high-quality fused images completely in the quaternion domain. QIVIF proposes a quaternion low-visibility feature learning model to adaptively extract salient thermal targets and fine-grained texture details from input infrared and visible images respectively under diverse degraded conditions. QIVIF then develops a quaternion adaptive unsharp masking method to adaptively improve high-frequency feature enhancement with balanced illumination. QIVIF further proposes a quaternion hierarchical Bayesian fusion model to integrate infrared saliency and enhanced visible details to obtain high-quality fused images. Extensive experiments across diverse datasets demonstrate that our QIVIF surpasses state-of-the-art methods under challenging low-visibility conditions.
Quaternion Multi-focus Color Image Fusion
May 05, 2025Multi-focus color image fusion refers to integrating multiple partially focused color images to create a single all-in-focus color image. However, existing methods struggle with complex real-world scenarios due to limitations in handling color information and intricate textures. To address these challenges, this paper proposes a quaternion multi-focus color image fusion framework to perform high-quality color image fusion completely in the quaternion domain. This framework introduces 1) a quaternion sparse decomposition model to jointly learn fine-scale image details and structure information of color images in an iterative fashion for high-precision focus detection, 2) a quaternion base-detail fusion strategy to individually fuse base-scale and detail-scale results across multiple color images for preserving structure and detail information, and 3) a quaternion structural similarity refinement strategy to adaptively select optimal patches from initial fusion results and obtain the final fused result for preserving fine details and ensuring spatially consistent outputs. Extensive experiments demonstrate that the proposed framework outperforms state-of-the-art methods.
DCT-Mamba3D: Spectral Decorrelation and Spatial-Spectral Feature Extraction for Hyperspectral Image Classification
Feb 04, 2025



Hyperspectral image classification presents challenges due to spectral redundancy and complex spatial-spectral dependencies. This paper proposes a novel framework, DCT-Mamba3D, for hyperspectral image classification. DCT-Mamba3D incorporates: (1) a 3D spectral-spatial decorrelation module that applies 3D discrete cosine transform basis functions to reduce both spectral and spatial redundancy, enhancing feature clarity across dimensions; (2) a 3D-Mamba module that leverages a bidirectional state-space model to capture intricate spatial-spectral dependencies; and (3) a global residual enhancement module that stabilizes feature representation, improving robustness and convergence. Extensive experiments on benchmark datasets show that our DCT-Mamba3D outperforms the state-of-the-art methods in challenging scenarios such as the same object in different spectra and different objects in the same spectra.
Highly Efficient Rotation-Invariant Spectral Embedding for Scalable Incomplete Multi-View Clustering
Jan 21, 2025



Incomplete multi-view clustering presents significant challenges due to missing views. Although many existing graph-based methods aim to recover missing instances or complete similarity matrices with promising results, they still face several limitations: (1) Recovered data may be unsuitable for spectral clustering, as these methods often ignore guidance from spectral analysis; (2) Complex optimization processes require high computational burden, hindering scalability to large-scale problems; (3) Most methods do not address the rotational mismatch problem in spectral embeddings. To address these issues, we propose a highly efficient rotation-invariant spectral embedding (RISE) method for scalable incomplete multi-view clustering. RISE learns view-specific embeddings from incomplete bipartite graphs to capture the complementary information. Meanwhile, a complete consensus representation with second-order rotation-invariant property is recovered from these incomplete embeddings in a unified model. Moreover, we design a fast alternating optimization algorithm with linear complexity and promising convergence to solve the proposed formulation. Extensive experiments on multiple datasets demonstrate the effectiveness, scalability, and efficiency of RISE compared to the state-of-the-art methods.
Rethinking The Training And Evaluation of Rich-Context Layout-to-Image Generation
Sep 07, 2024Recent advancements in generative models have significantly enhanced their capacity for image generation, enabling a wide range of applications such as image editing, completion and video editing. A specialized area within generative modeling is layout-to-image (L2I) generation, where predefined layouts of objects guide the generative process. In this study, we introduce a novel regional cross-attention module tailored to enrich layout-to-image generation. This module notably improves the representation of layout regions, particularly in scenarios where existing methods struggle with highly complex and detailed textual descriptions. Moreover, while current open-vocabulary L2I methods are trained in an open-set setting, their evaluations often occur in closed-set environments. To bridge this gap, we propose two metrics to assess L2I performance in open-vocabulary scenarios. Additionally, we conduct a comprehensive user study to validate the consistency of these metrics with human preferences.
Multiview Transformer: Rethinking Spatial Information in Hyperspectral Image Classification
Oct 11, 2023Identifying the land cover category for each pixel in a hyperspectral image (HSI) relies on spectral and spatial information. An HSI cuboid with a specific patch size is utilized to extract spatial-spectral feature representation for the central pixel. In this article, we investigate that scene-specific but not essential correlations may be recorded in an HSI cuboid. This additional information improves the model performance on existing HSI datasets and makes it hard to properly evaluate the ability of a model. We refer to this problem as the spatial overfitting issue and utilize strict experimental settings to avoid it. We further propose a multiview transformer for HSI classification, which consists of multiview principal component analysis (MPCA), spectral encoder-decoder (SED), and spatial-pooling tokenization transformer (SPTT). MPCA performs dimension reduction on an HSI via constructing spectral multiview observations and applying PCA on each view data to extract low-dimensional view representation. The combination of view representations, named multiview representation, is the dimension reduction output of the MPCA. To aggregate the multiview information, a fully-convolutional SED with a U-shape in spectral dimension is introduced to extract a multiview feature map. SPTT transforms the multiview features into tokens using the spatial-pooling tokenization strategy and learns robust and discriminative spatial-spectral features for land cover identification. Classification is conducted with a linear classifier. Experiments on three HSI datasets with rigid settings demonstrate the superiority of the proposed multiview transformer over the state-of-the-art methods.
SEVGGNet-LSTM: a fused deep learning model for ECG classification
Oct 31, 2022This paper presents a fused deep learning algorithm for ECG classification. It takes advantages of the combined convolutional and recurrent neural network for ECG classification, and the weight allocation capability of attention mechanism. The input ECG signals are firstly segmented and normalized, and then fed into the combined VGG and LSTM network for feature extraction and classification. An attention mechanism (SE block) is embedded into the core network for increasing the weight of important features. Two databases from different sources and devices are employed for performance validation, and the results well demonstrate the effectiveness and robustness of the proposed algorithm.
Uformer-ICS: A Specialized U-Shaped Transformer for Image Compressive Sensing
Sep 05, 2022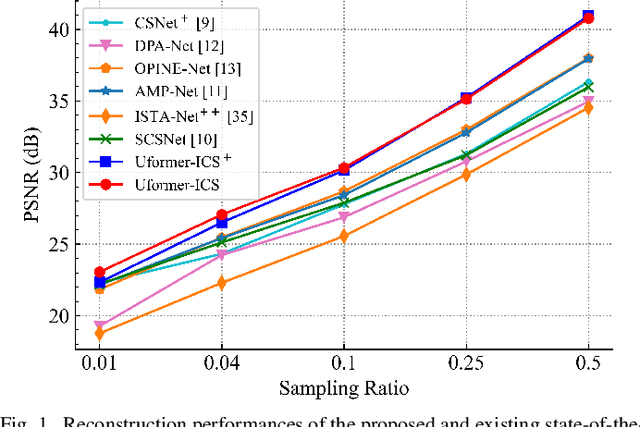
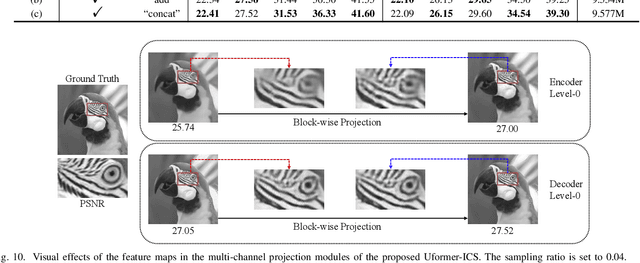
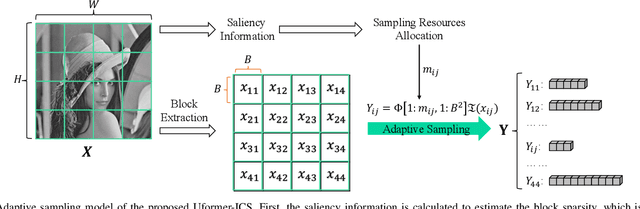

Recently, several studies have applied deep convolutional neural networks (CNNs) in image compressive sensing (CS) tasks to improve reconstruction quality. However, convolutional layers generally have a small receptive field; therefore, capturing long-range pixel correlations using CNNs is challenging, which limits their reconstruction performance in image CS tasks. Considering this limitation, we propose a U-shaped transformer for image CS tasks, called the Uformer-ICS. We develop a projection-based transformer block by integrating the prior projection knowledge of CS into the original transformer blocks, and then build a symmetrical reconstruction model using the projection-based transformer blocks and residual convolutional blocks. Compared with previous CNN-based CS methods that can only exploit local image features, the proposed reconstruction model can simultaneously utilize the local features and long-range dependencies of an image, and the prior projection knowledge of the CS theory. Additionally, we design an adaptive sampling model that can adaptively sample image blocks based on block sparsity, which can ensure that the compressed results retain the maximum possible information of the original image under a fixed sampling ratio. The proposed Uformer-ICS is an end-to-end framework that simultaneously learns the sampling and reconstruction processes. Experimental results demonstrate that it achieves significantly better reconstruction performance than existing state-of-the-art deep learning-based CS methods.
CSN: Component-Supervised Network for Few-Shot Classification
Mar 15, 2022
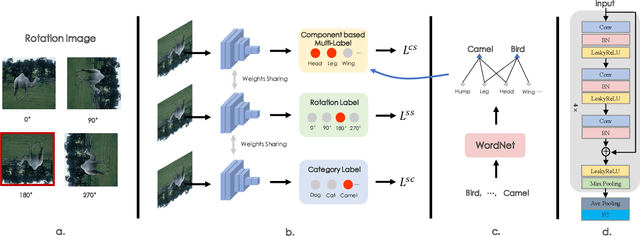

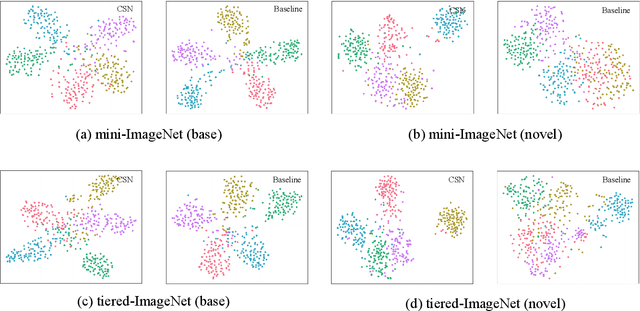
The few-shot classification (FSC) task has been a hot research topic in recent years. It aims to address the classification problem with insufficient labeled data on a cross-category basis. Typically, researchers pre-train a feature extractor with base data, then use it to extract the features of novel data and recognize them. Notably, the novel set only has a few annotated samples and has entirely different categories from the base set, which leads to that the pre-trained feature extractor can not adapt to the novel data flawlessly. We dub this problem as Feature-Extractor-Maladaptive (FEM) problem. Starting from the root cause of this problem, this paper presents a new scheme, Component-Supervised Network (CSN), to improve the performance of FSC. We believe that although the categories of base and novel sets are different, the composition of the sample's components is similar. For example, both cat and dog contain leg and head components. Actually, such entity components are intra-class stable. They have fine cross-category versatility and new category generalization. Therefore, we refer to WordNet, a dictionary commonly used in natural language processing, to collect component information of samples and construct a component-based auxiliary task to improve the adaptability of the feature extractor. We conduct experiments on two benchmark datasets (mini-ImageNet and tiered-ImageNet), the improvements of $0.9\%$-$5.8\%$ compared with state-of-the-arts have evaluated the efficiency of our CSN.