 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedGuards: Multi-Agent System for Reliable Medical Error Detection and Correction
Jun 24, 2026As Large Language Models (LLMs) are increasingly deployed in healthcare settings, accurate error detection and correction in generated or existing text becomes critical, as even minor mistakes can pose risks to patient safety. Existing methods for error detection and correction, including automated checks and heuristic-based approaches, do not generalize well across unseen datasets. In this paper, we propose MedGuards as a medical safety guardrail, which is a new framework that treats medical error detection and correction as a multi-agent in-context learning task. Specialized agents separately detect, localize, and correct errors, while a confidence-guided arbitration mechanism resolves disagreements using reasoning traces and confidence scores. This design enhances interpretability, robustness, and adaptability, without requiring additional training of the base LLMs. Additionally, we introduce the Keyword-Prioritized Correction Score (KPCS), a new evaluation metric that considers whether critical keywords within the reference text are generated correctly, providing a more comprehensive assessment than conventional metrics. Experiments across four multilingual medical datasets consisting of clinical notes demonstrate significant improvements by the proposed framework across several metrics and models. Our aim is to enable safer deployment of LLMs in real-world healthcare applications. For reproducibility, we make our code publicly available at https://github.com/congboma/MedErrBench.
MedErrBench: A Fine-Grained Multilingual Benchmark for Medical Error Detection and Correction with Clinical Expert Annotations
Feb 05, 2026Inaccuracies in existing or generated clinical text may lead to serious adverse consequences, especially if it is a misdiagnosis or incorrect treatment suggestion. With Large Language Models (LLMs) increasingly being used across diverse healthcare applications, comprehensive evaluation through dedicated benchmarks is crucial. However, such datasets remain scarce, especially across diverse languages and contexts. In this paper, we introduce MedErrBench, the first multilingual benchmark for error detection, localization, and correction, developed under the guidance of experienced clinicians. Based on an expanded taxonomy of ten common error types, MedErrBench covers English, Arabic and Chinese, with natural clinical cases annotated and reviewed by domain experts. We assessed the performance of a range of general-purpose, language-specific, and medical-domain language models across all three tasks. Our results reveal notable performance gaps, particularly in non-English settings, highlighting the need for clinically grounded, language-aware systems. By making MedErrBench and our evaluation protocols publicly-available, we aim to advance multilingual clinical NLP to promote safer and more equitable AI-based healthcare globally. The dataset is available in the supplementary material. An anonymized version of the dataset is available at: https://github.com/congboma/MedErrBench.
ShowUI-Aloha: Human-Taught GUI Agent
Jan 12, 2026Graphical User Interfaces (GUIs) are central to human-computer interaction, yet automating complex GUI tasks remains a major challenge for autonomous agents, largely due to a lack of scalable, high-quality training data. While recordings of human demonstrations offer a rich data source, they are typically long, unstructured, and lack annotations, making them difficult for agents to learn from.To address this, we introduce ShowUI-Aloha, a comprehensive pipeline that transforms unstructured, in-the-wild human screen recordings from desktop environments into structured, actionable tasks. Our framework includes four key components: A recorder that captures screen video along with precise user interactions like mouse clicks, keystrokes, and scrolls. A learner that semantically interprets these raw interactions and the surrounding visual context, translating them into descriptive natural language captions. A planner that reads the parsed demonstrations, maintains task states, and dynamically formulates the next high-level action plan based on contextual reasoning. An executor that faithfully carries out these action plans at the OS level, performing precise clicks, drags, text inputs, and window operations with safety checks and real-time feedback. Together, these components provide a scalable solution for collecting and parsing real-world human data, demonstrating a viable path toward building general-purpose GUI agents that can learn effectively from simply observing humans.
Will Multi-modal Data Improves Few-shot Learning?
Jul 25, 2021
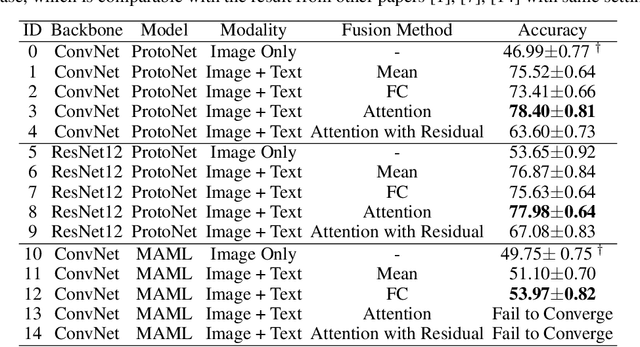
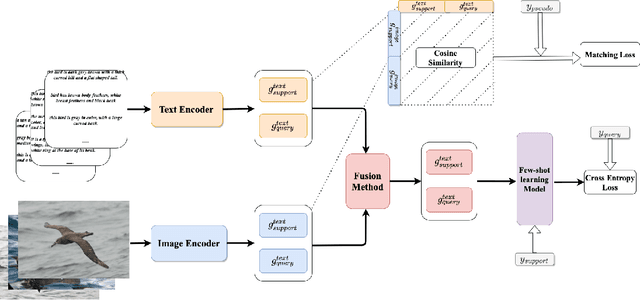

Most few-shot learning models utilize only one modality of data. We would like to investigate qualitatively and quantitatively how much will the model improve if we add an extra modality (i.e. text description of the image), and how it affects the learning procedure. To achieve this goal, we propose four types of fusion method to combine the image feature and text feature. To verify the effectiveness of improvement, we test the fusion methods with two classical few-shot learning models - ProtoNet and MAML, with image feature extractors such as ConvNet and ResNet12. The attention-based fusion method works best, which improves the classification accuracy by a large margin around 30% comparing to the baseline result.