 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Structural Latent Points for Efficient Visual Representations in Robotic Manipulation
May 20, 2026Current 3D-aware pretraining methods for embodied perception and manipulation are largely built on differentiable rendering frameworks, producing either fully implicit neural fields or fully explicit geometric primitives. Implicit representations, while expressive, lack explicit structural cues, whereas explicit ones preserve geometry but suffer from resolution limits and weak generalization. To address these limitations, we propose a novel pretraining framework that learns a hybrid representation-structural latent points. Specifically, we insert a point-wise latent variational autoencoder into the latent space of a point-cloud autoencoder, jointly regularizing point-wise features and coordinates toward a Gaussian prior. The resulting compact latent preserves coarse structural tendencies, which do not encode precise geometry but capture richer rough shape and semantic information, effectively combining the expressiveness of implicit representations with the structural priors of explicit ones. In addition, informed by shared design choices in prior work, we develop a streamlined, efficient 3DGS-based rendering pipeline that is deliberately kept lightweight, improving efficiency while leaving greater representational capacity to the front-end latent module. Extensive evaluations on RLBench, ManiSkill2, and a real-robot platform demonstrate consistent gains in task success, sample efficiency, and robustness to viewpoint and scene variations over strong baselines. Ablation studies further confirm that each component of our framework is critical to overall performance.
Tensegrity Robot Endcap-Ground Contact Estimation with Symmetry-aware Heterogeneous Graph Neural Network
Mar 03, 2026Tensegrity robots possess lightweight and resilient structures but present significant challenges for state estimation due to compliant and distributed ground contacts. This paper introduces a symmetry-aware heterogeneous graph neural network (Sym-HGNN) that infers contact states directly from proprioceptive measurements, including IMU and cable-length histories, without dedicated contact sensors. The network incorporates the robot's dihedral symmetry $D_3$ into the message-passing process to enhance sample efficiency and generalization. The predicted contacts are integrated into a state-of-the-art contact-aided invariant extended Kalman filter (InEKF) for improved pose estimation. Simulation results demonstrate that the proposed method achieves up to 15% higher accuracy and 5% higher F1-score using only 20% of the training data compared to the CNN and MI-HGNN baselines, while maintaining low-drift and physically consistent state estimation results comparable to ground truth contacts. This work highlights the potential of fully proprioceptive sensing for accurate and robust state estimation in tensegrity robots. Code available at: https://github.com/Jonathan-Twz/Tensegrity-Sym-HGNN
MVISTA-4D: View-Consistent 4D World Model with Test-Time Action Inference for Robotic Manipulation
Feb 10, 2026World-model-based imagine-then-act becomes a promising paradigm for robotic manipulation, yet existing approaches typically support either purely image-based forecasting or reasoning over partial 3D geometry, limiting their ability to predict complete 4D scene dynamics. This work proposes a novel embodied 4D world model that enables geometrically consistent, arbitrary-view RGBD generation: given only a single-view RGBD observation as input, the model imagines the remaining viewpoints, which can then be back-projected and fused to assemble a more complete 3D structure across time. To efficiently learn the multi-view, cross-modality generation, we explicitly design cross-view and cross-modality feature fusion that jointly encourage consistency between RGB and depth and enforce geometric alignment across views. Beyond prediction, converting generated futures into actions is often handled by inverse dynamics, which is ill-posed because multiple actions can explain the same transition. We address this with a test-time action optimization strategy that backpropagates through the generative model to infer a trajectory-level latent best matching the predicted future, and a residual inverse dynamics model that turns this trajectory prior into accurate executable actions. Experiments on three datasets demonstrate strong performance on both 4D scene generation and downstream manipulation, and ablations provide practical insights into the key design choices.
REFINE-CONTROL: A Semi-supervised Distillation Method For Conditional Image Generation
Sep 26, 2025Conditional image generation models have achieved remarkable results by leveraging text-based control to generate customized images. However, the high resource demands of these models and the scarcity of well-annotated data have hindered their deployment on edge devices, leading to enormous costs and privacy concerns, especially when user data is sent to a third party. To overcome these challenges, we propose Refine-Control, a semi-supervised distillation framework. Specifically, we improve the performance of the student model by introducing a tri-level knowledge fusion loss to transfer different levels of knowledge. To enhance generalization and alleviate dataset scarcity, we introduce a semi-supervised distillation method utilizing both labeled and unlabeled data. Our experiments reveal that Refine-Control achieves significant reductions in computational cost and latency, while maintaining high-fidelity generation capabilities and controllability, as quantified by comparative metrics.
COPU: Conformal Prediction for Uncertainty Quantification in Natural Language Generation
Feb 18, 2025



Uncertainty Quantification (UQ) for Natural Language Generation (NLG) is crucial for assessing the performance of Large Language Models (LLMs), as it reveals confidence in predictions, identifies failure modes, and gauges output reliability. Conformal Prediction (CP), a model-agnostic method that generates prediction sets with a specified error rate, has been adopted for UQ in classification tasks, where the size of the prediction set indicates the model's uncertainty. However, when adapting CP to NLG, the sampling-based method for generating candidate outputs cannot guarantee the inclusion of the ground truth, limiting its applicability across a wide range of error rates. To address this, we propose \ourmethod, a method that explicitly adds the ground truth to the candidate outputs and uses logit scores to measure nonconformity. Our experiments with six LLMs on four NLG tasks show that \ourmethod outperforms baseline methods in calibrating error rates and empirical cover rates, offering accurate UQ across a wide range of user-specified error rates.
Tensegrity Robot Proprioceptive State Estimation with Geometric Constraints
Oct 31, 2024
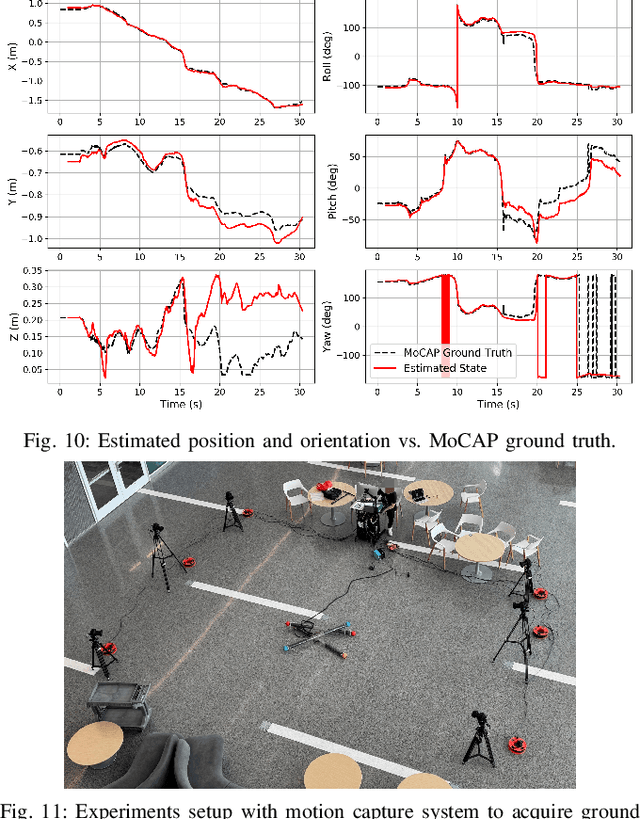


Tensegrity robots, characterized by a synergistic assembly of rigid rods and elastic cables, form robust structures that are resistant to impacts. However, this design introduces complexities in kinematics and dynamics, complicating control and state estimation. This work presents a novel proprioceptive state estimator for tensegrity robots. The estimator initially uses the geometric constraints of 3-bar prism tensegrity structures, combined with IMU and motor encoder measurements, to reconstruct the robot's shape and orientation. It then employs a contact-aided invariant extended Kalman filter with forward kinematics to estimate the global position and orientation of the tensegrity robot. The state estimator's accuracy is assessed against ground truth data in both simulated environments and real-world tensegrity robot applications. It achieves an average drift percentage of 4.2%, comparable to the state estimation performance of traditional rigid robots. This state estimator advances the state of the art in tensegrity robot state estimation and has the potential to run in real-time using onboard sensors, paving the way for full autonomy of tensegrity robots in unstructured environments.
Hepatocellular Carcinoma Segmentation fromDigital Subtraction Angiography Videos usingLearnable Temporal Difference
Jul 09, 2021

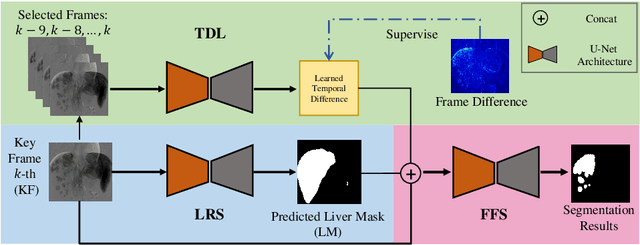

Automatic segmentation of hepatocellular carcinoma (HCC)in Digital Subtraction Angiography (DSA) videos can assist radiologistsin efficient diagnosis of HCC and accurate evaluation of tumors in clinical practice. Few studies have investigated HCC segmentation from DSAvideos. It shows great challenging due to motion artifacts in filming, ambiguous boundaries of tumor regions and high similarity in imaging toother anatomical tissues. In this paper, we raise the problem of HCCsegmentation in DSA videos, and build our own DSA dataset. We alsopropose a novel segmentation network called DSA-LTDNet, including asegmentation sub-network, a temporal difference learning (TDL) moduleand a liver region segmentation (LRS) sub-network for providing additional guidance. DSA-LTDNet is preferable for learning the latent motioninformation from DSA videos proactively and boosting segmentation performance. All of experiments are conducted on our self-collected dataset.Experimental results show that DSA-LTDNet increases the DICE scoreby nearly 4% compared to the U-Net baseline.