 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Visual Classification via Progressive Multi-Granularity Training of Jigsaw Patches
Mar 10, 2020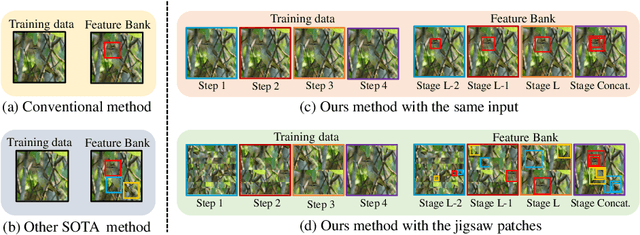
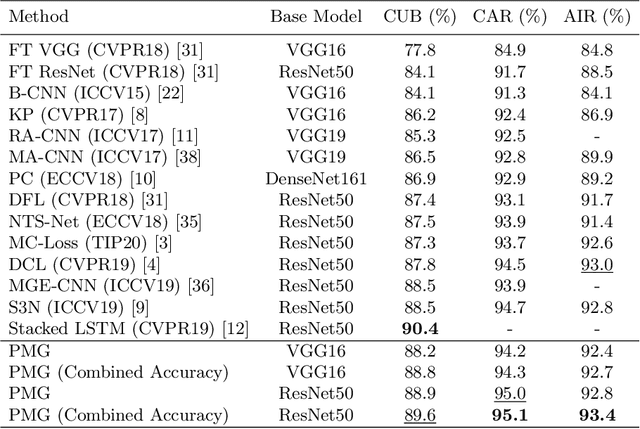
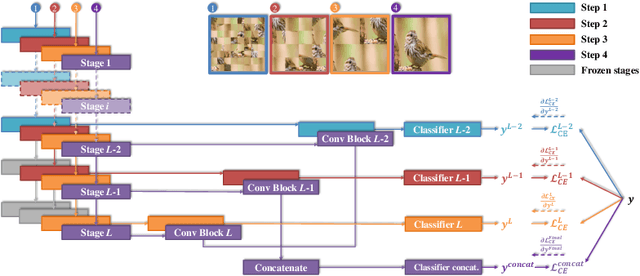
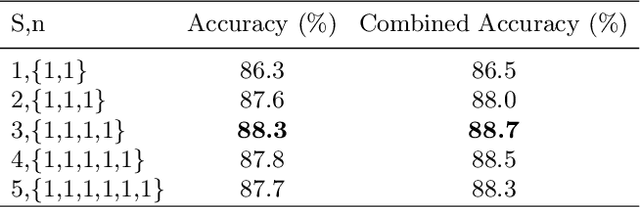
Fine-grained visual classification (FGVC) is much more challenging than traditional classification tasks due to the inherently subtle intra-class object variations. Recent works mainly tackle this problem by focusing on how to locate the most discriminative parts, more complementary parts, and parts of various granularities. However, less effort has been placed to which granularities are the most discriminative and how to fuse information cross multi-granularity. In this work, we propose a novel framework for fine-grained visual classification to tackle these problems. In particular, we propose: (i) a novel progressive training strategy that adds new layers in each training step to exploit information based on the smaller granularity information found at the last step and the previous stage. (ii) a simple jigsaw puzzle generator to form images contain information of different granularity levels. We obtain state-of-the-art performances on several standard FGVC benchmark datasets, where the proposed method consistently outperforms existing methods or delivers competitive results. The code will be available at https://github.com/RuoyiDu/PMG-Progressive-Multi-Granularity-Training.
Mind the Gap: Enlarging the Domain Gap in Open Set Domain Adaptation
Mar 10, 2020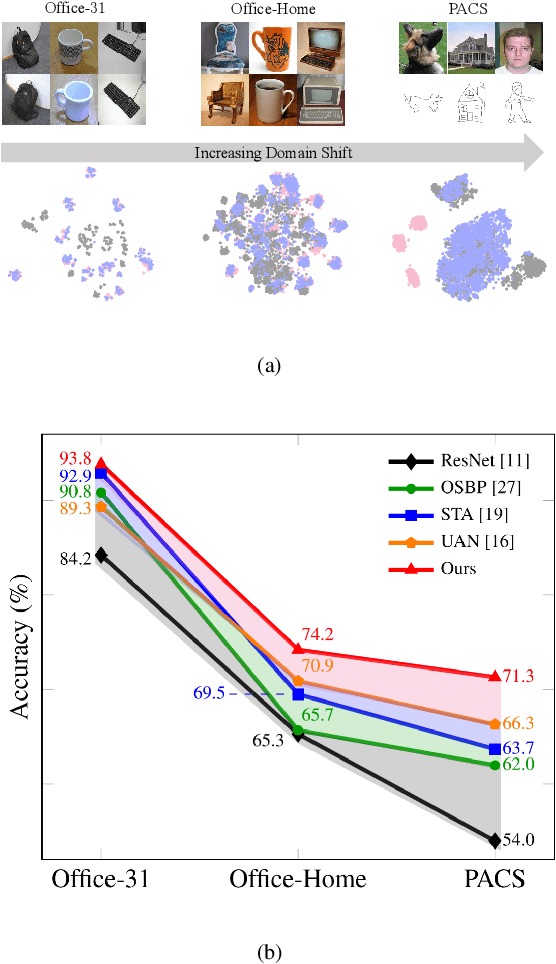
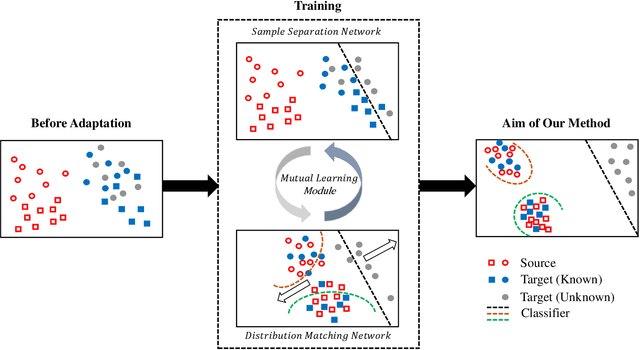
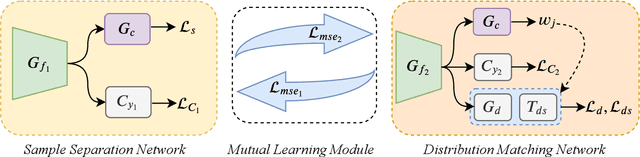
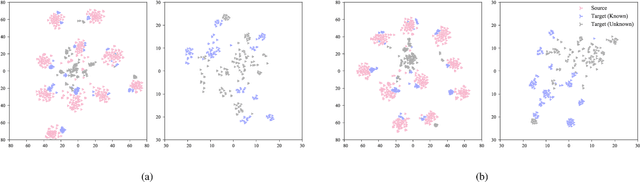
Unsupervised domain adaptation aims to leverage labeled data from a source domain to learn a classifier for an unlabeled target domain. Among its many variants, open set domain adaptation (OSDA) is perhaps the most challenging, as it further assumes the presence of unknown classes in the target domain. In this paper, we study OSDA with a particular focus on enriching its ability to traverse across larger domain gaps. Firstly, we show that existing state-of-the-art methods suffer a considerable performance drop in the presence of larger domain gaps, especially on a new dataset (PACS) that we re-purposed for OSDA. We then propose a novel framework to specifically address the larger domain gaps. The key insight lies with how we exploit the mutually beneficial information between two networks; (a) to separate samples of known and unknown classes, (b) to maximize the domain confusion between source and target domain without the influence of unknown samples. It follows that (a) and (b) will mutually supervise each other and alternate until convergence. Extensive experiments are conducted on Office-31, Office-Home, and PACS datasets, demonstrating the superiority of our method in comparison to other state-of-the-arts. Code available at https://github.com/dongliangchang/Mutual-to-Separate/
Sketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval
Mar 05, 2020
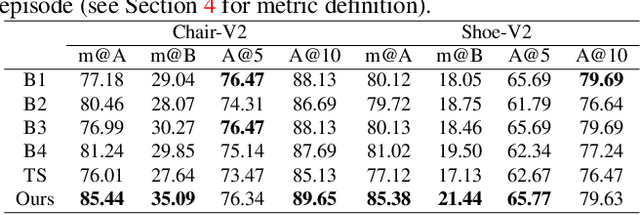
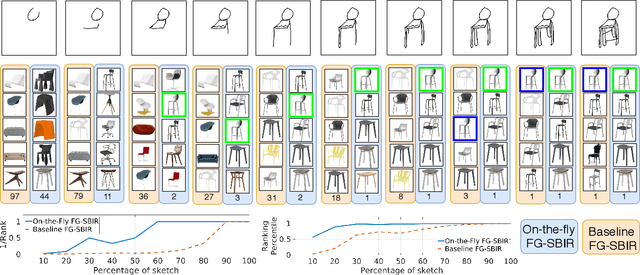
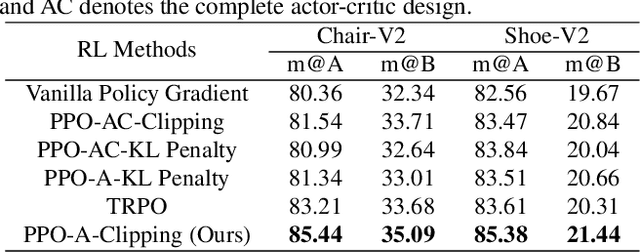
Fine-grained sketch-based image retrieval (FG-SBIR) addresses the problem of retrieving a particular photo instance given a user's query sketch. Its widespread applicability is however hindered by the fact that drawing a sketch takes time, and most people struggle to draw a complete and faithful sketch. In this paper, we reformulate the conventional FG-SBIR framework to tackle these challenges, with the ultimate goal of retrieving the target photo with the least number of strokes possible. We further propose an on-the-fly design that starts retrieving as soon as the user starts drawing. To accomplish this, we devise a reinforcement learning-based cross-modal retrieval framework that directly optimizes rank of the ground-truth photo over a complete sketch drawing episode. Additionally, we introduce a novel reward scheme that circumvents the problems related to irrelevant sketch strokes, and thus provides us with a more consistent rank list during the retrieval. We achieve superior early-retrieval efficiency over state-of-the-art methods and alternative baselines on two publicly available fine-grained sketch retrieval datasets.
Fine-Grained Instance-Level Sketch-Based Video Retrieval
Feb 21, 2020
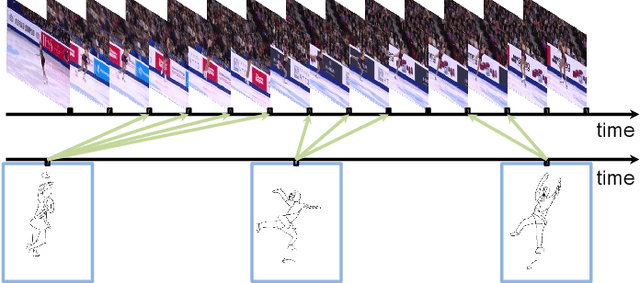

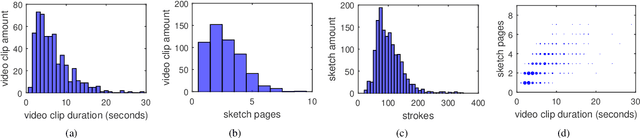
Existing sketch-analysis work studies sketches depicting static objects or scenes. In this work, we propose a novel cross-modal retrieval problem of fine-grained instance-level sketch-based video retrieval (FG-SBVR), where a sketch sequence is used as a query to retrieve a specific target video instance. Compared with sketch-based still image retrieval, and coarse-grained category-level video retrieval, this is more challenging as both visual appearance and motion need to be simultaneously matched at a fine-grained level. We contribute the first FG-SBVR dataset with rich annotations. We then introduce a novel multi-stream multi-modality deep network to perform FG-SBVR under both strong and weakly supervised settings. The key component of the network is a relation module, designed to prevent model over-fitting given scarce training data. We show that this model significantly outperforms a number of existing state-of-the-art models designed for video analysis.
The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification
Feb 11, 2020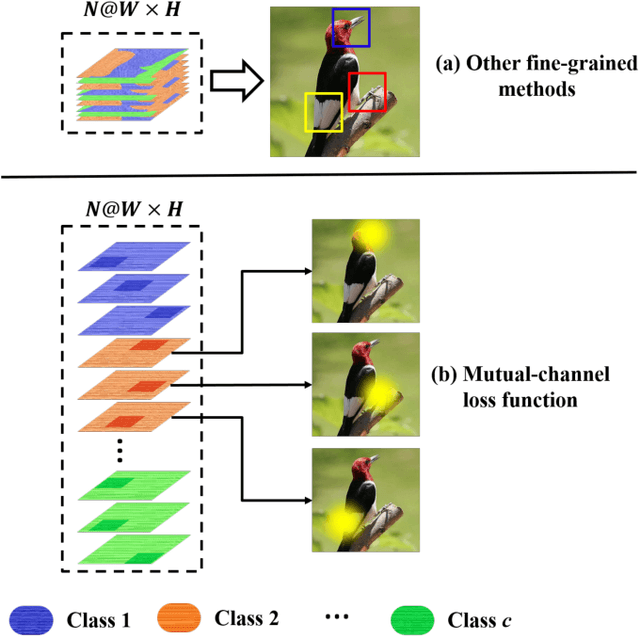
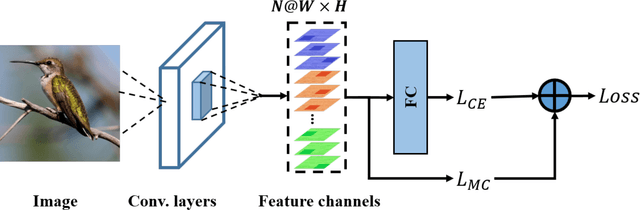
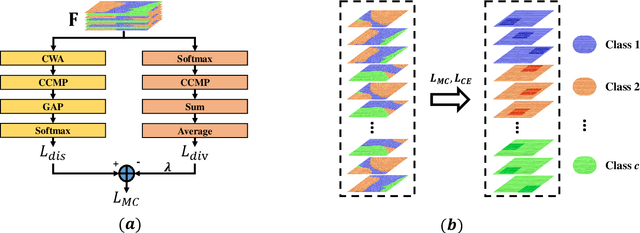
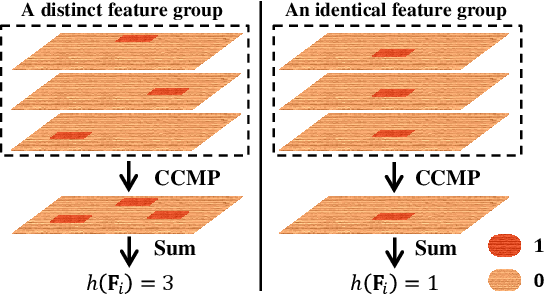
Key for solving fine-grained image categorization is finding discriminate and local regions that correspond to subtle visual traits. Great strides have been made, with complex networks designed specifically to learn part-level discriminate feature representations. In this paper, we show it is possible to cultivate subtle details without the need for overly complicated network designs or training mechanisms -- a single loss is all it takes. The main trick lies with how we delve into individual feature channels early on, as opposed to the convention of starting from a consolidated feature map. The proposed loss function, termed as mutual-channel loss (MC-Loss), consists of two channel-specific components: a discriminality component and a diversity component. The discriminality component forces all feature channels belonging to the same class to be discriminative, through a novel channel-wise attention mechanism. The diversity component additionally constraints channels so that they become mutually exclusive on spatial-wise. The end result is therefore a set of feature channels that each reflects different locally discriminative regions for a specific class. The MC-Loss can be trained end-to-end, without the need for any bounding-box/part annotations, and yields highly discriminative regions during inference. Experimental results show our MC-Loss when implemented on top of common base networks can achieve state-of-the-art performance on all four fine-grained categorization datasets (CUB-Birds, FGVC-Aircraft, Flowers-102, and Stanford-Cars). Ablative studies further demonstrate the superiority of MC-Loss when compared with other recently proposed general-purpose losses for visual classification, on two different base networks. Code available at https://github.com/dongliangchang/Mutual-Channel-Loss
Deep Self-Supervised Representation Learning for Free-Hand Sketch
Feb 03, 2020
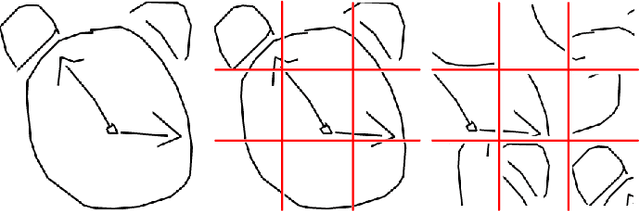
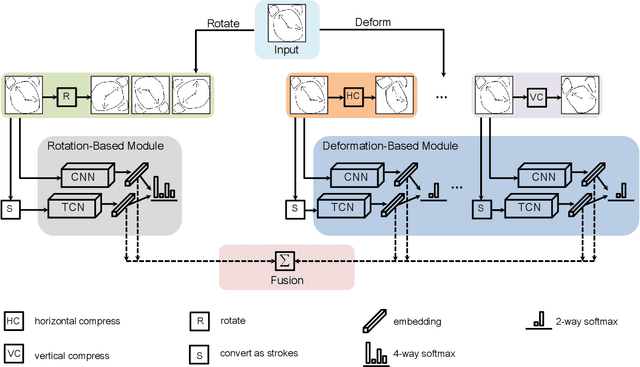
In this paper, we tackle for the first time, the problem of self-supervised representation learning for free-hand sketches. This importantly addresses a common problem faced by the sketch community -- that annotated supervisory data are difficult to obtain. This problem is very challenging in that sketches are highly abstract and subject to different drawing styles, making existing solutions tailored for photos unsuitable. Key for the success of our self-supervised learning paradigm lies with our sketch-specific designs: (i) we propose a set of pretext tasks specifically designed for sketches that mimic different drawing styles, and (ii) we further exploit the use of a textual convolution network (TCN) in a dual-branch architecture for sketch feature learning, as means to accommodate the sequential stroke nature of sketches. We demonstrate the superiority of our sketch-specific designs through two sketch-related applications (retrieval and recognition) on a million-scale sketch dataset, and show that the proposed approach outperforms the state-of-the-art unsupervised representation learning methods, and significantly narrows the performance gap between with supervised representation learning.
SketchDesc: Learning Local Sketch Descriptors for Multi-view Correspondence
Jan 17, 2020

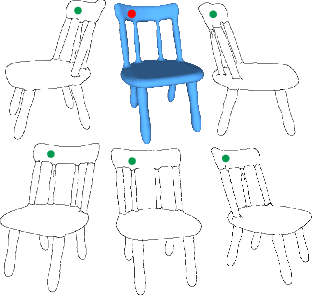
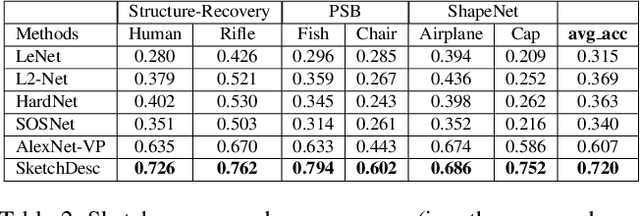
In this paper, we study the problem of multi-view sketch correspondence, where we take as input multiple freehand sketches with different views of the same object and predict semantic correspondence among the sketches. This problem is challenging, since visual features of corresponding points at different views can be very different. To this end, we take a deep learning approach and learn a novel local sketch descriptor from data. We contribute a training dataset by generating the pixel-level correspondence for the multi-view line drawings synthesized from 3D shapes. To handle the sparsity and ambiguity of sketches, we design a novel multi-branch neural network that integrates a patch-based representation and a multi-scale strategy to learn the \pixelLevel correspondence among multi-view sketches. We demonstrate the effectiveness of our proposed approach with extensive experiments on hand-drawn sketches, and multi-view line drawings rendered from multiple 3D shape datasets.
Semi-Heterogeneous Three-Way Joint Embedding Network for Sketch-Based Image Retrieval
Nov 10, 2019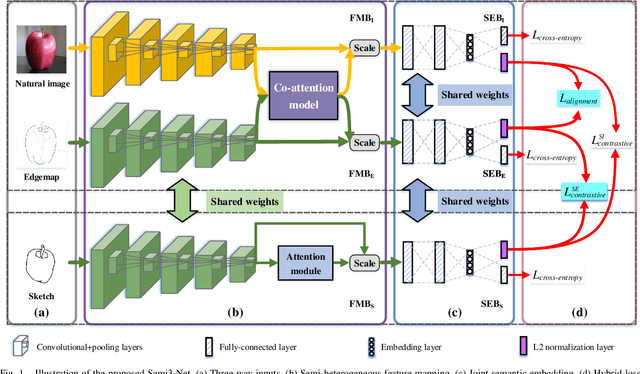
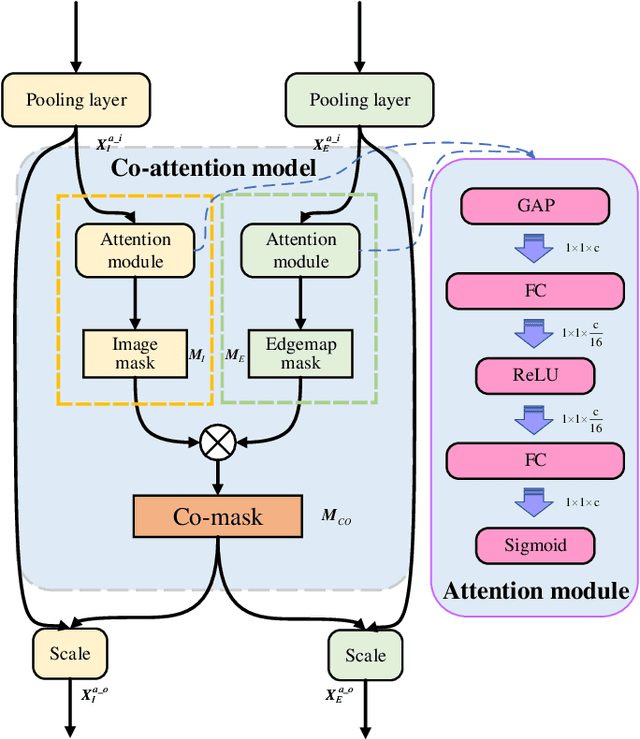

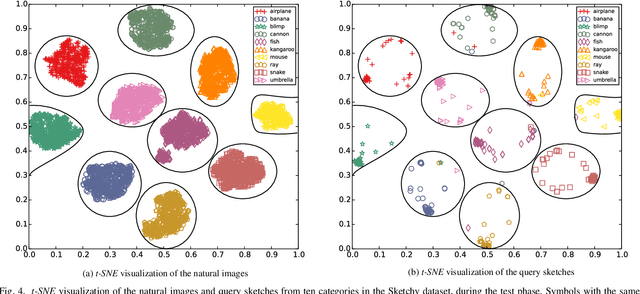
Sketch-based image retrieval (SBIR) is a challenging task due to the large cross-domain gap between sketches and natural images. How to align abstract sketches and natural images into a common high-level semantic space remains a key problem in SBIR. In this paper, we propose a novel semi-heterogeneous three-way joint embedding network (Semi3-Net), which integrates three branches (a sketch branch, a natural image branch, and an edgemap branch) to learn more discriminative cross-domain feature representations for the SBIR task. The key insight lies with how we cultivate the mutual and subtle relationships amongst the sketches, natural images, and edgemaps. A semi-heterogeneous feature mapping is designed to extract bottom features from each domain, where the sketch and edgemap branches are shared while the natural image branch is heterogeneous to the other branches. In addition, a joint semantic embedding is introduced to embed the features from different domains into a common high-level semantic space, where all of the three branches are shared. To further capture informative features common to both natural images and the corresponding edgemaps, a co-attention model is introduced to conduct common channel-wise feature recalibration between different domains. A hybrid-loss mechanism is designed to align the three branches, where an alignment loss and a sketch-edgemap contrastive loss are presented to encourage the network to learn invariant cross-domain representations. Experimental results on two widely used category-level datasets (Sketchy and TU-Berlin Extension) demonstrate that the proposed method outperforms state-of-the-art methods.
Goal-Driven Sequential Data Abstraction
Aug 08, 2019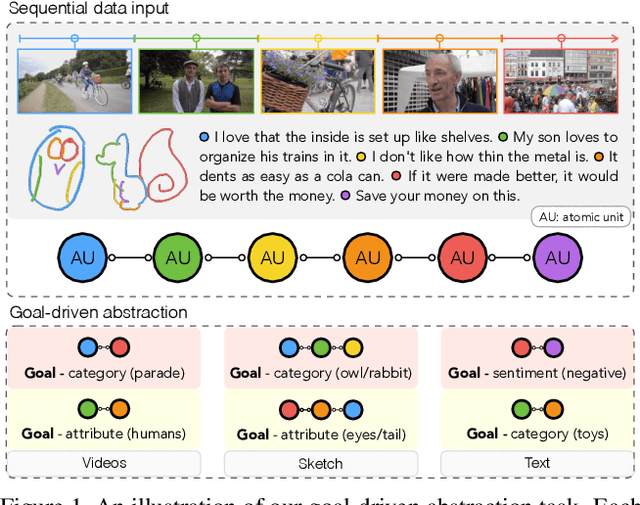
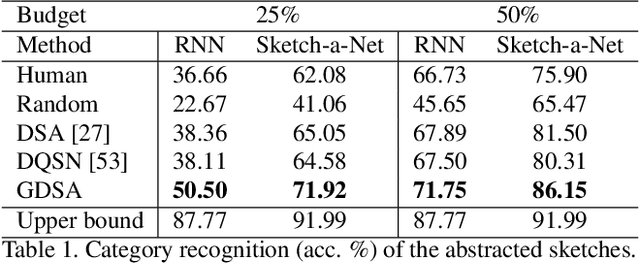
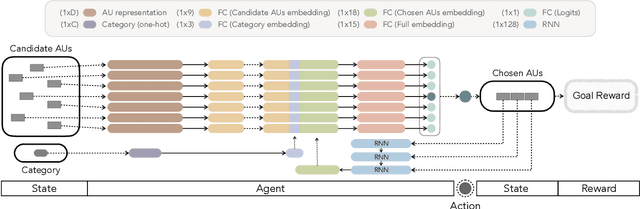
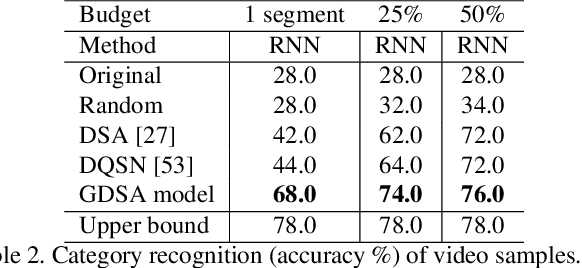
Automatic data abstraction is an important capability for both benchmarking machine intelligence and supporting summarization applications. In the former one asks whether a machine can `understand' enough about the meaning of input data to produce a meaningful but more compact abstraction. In the latter this capability is exploited for saving space or human time by summarizing the essence of input data. In this paper we study a general reinforcement learning based framework for learning to abstract sequential data in a goal-driven way. The ability to define different abstraction goals uniquely allows different aspects of the input data to be preserved according to the ultimate purpose of the abstraction. Our reinforcement learning objective does not require human-defined examples of ideal abstraction. Importantly our model processes the input sequence holistically without being constrained by the original input order. Our framework is also domain agnostic -- we demonstrate applications to sketch, video and text data and achieve promising results in all domains.
Doodle to Search: Practical Zero-Shot Sketch-based Image Retrieval
Apr 06, 2019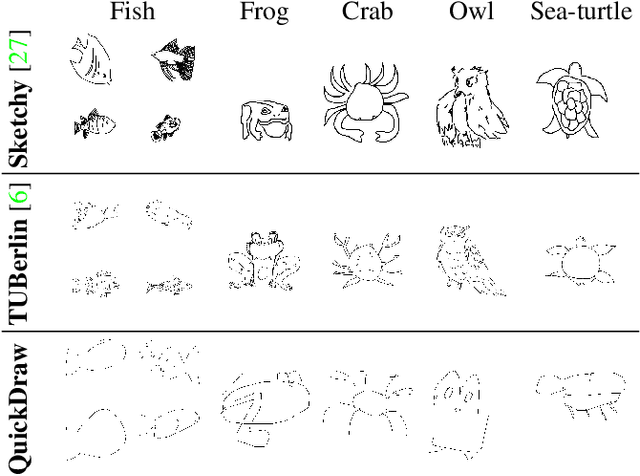
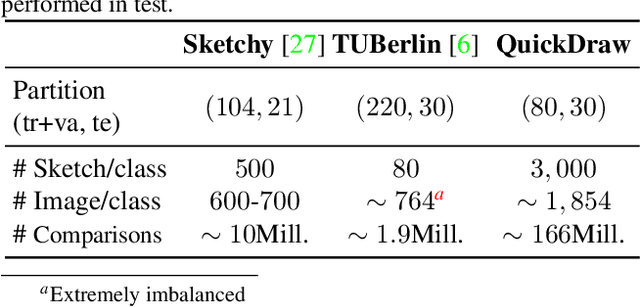

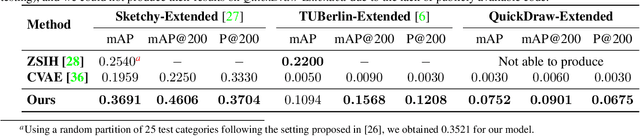
In this paper, we investigate the problem of zero-shot sketch-based image retrieval (ZS-SBIR), where human sketches are used as queries to conduct retrieval of photos from unseen categories. We importantly advance prior arts by proposing a novel ZS-SBIR scenario that represents a firm step forward in its practical application. The new setting uniquely recognizes two important yet often neglected challenges of practical ZS-SBIR, (i) the large domain gap between amateur sketch and photo, and (ii) the necessity for moving towards large-scale retrieval. We first contribute to the community a novel ZS-SBIR dataset, QuickDraw-Extended, that consists of 330,000 sketches and 204,000 photos spanning across 110 categories. Highly abstract amateur human sketches are purposefully sourced to maximize the domain gap, instead of ones included in existing datasets that can often be semi-photorealistic. We then formulate a ZS-SBIR framework to jointly model sketches and photos into a common embedding space. A novel strategy to mine the mutual information among domains is specifically engineered to alleviate the domain gap. External semantic knowledge is further embedded to aid semantic transfer. We show that, rather surprisingly, retrieval performance significantly outperforms that of state-of-the-art on existing datasets that can already be achieved using a reduced version of our model. We further demonstrate the superior performance of our full model by comparing with a number of alternatives on the newly proposed dataset. The new dataset, plus all training and testing code of our model, will be publicly released to facilitate future research