 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptive Semantic Segmentation Using Weak Labels
Aug 12, 2020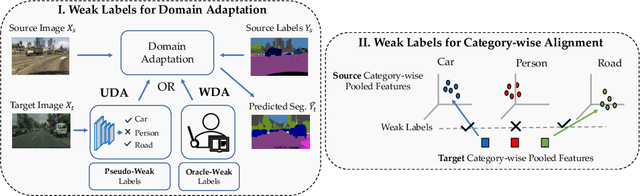
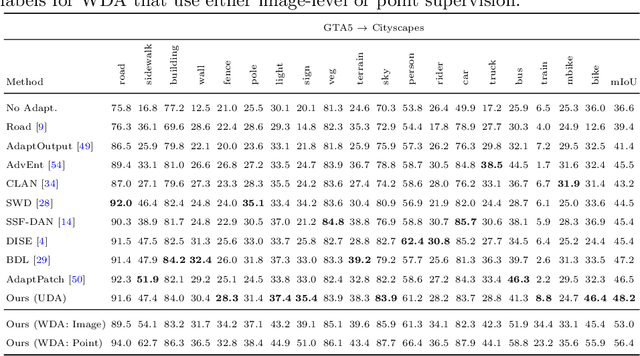
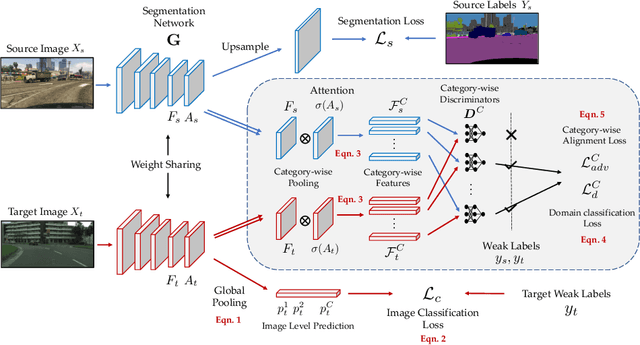
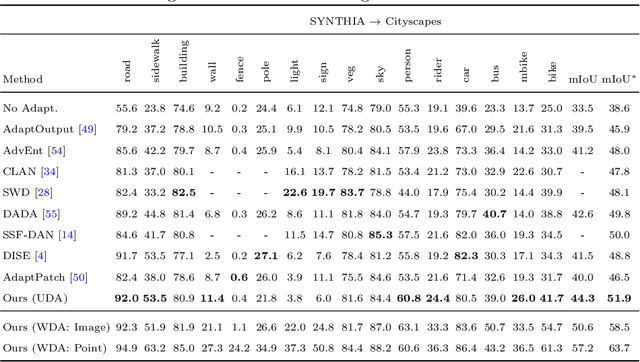
Learning semantic segmentation models requires a huge amount of pixel-wise labeling. However, labeled data may only be available abundantly in a domain different from the desired target domain, which only has minimal or no annotations. In this work, we propose a novel framework for domain adaptation in semantic segmentation with image-level weak labels in the target domain. The weak labels may be obtained based on a model prediction for unsupervised domain adaptation (UDA), or from a human annotator in a new weakly-supervised domain adaptation (WDA) paradigm for semantic segmentation. Using weak labels is both practical and useful, since (i) collecting image-level target annotations is comparably cheap in WDA and incurs no cost in UDA, and (ii) it opens the opportunity for category-wise domain alignment. Our framework uses weak labels to enable the interplay between feature alignment and pseudo-labeling, improving both in the process of domain adaptation. Specifically, we develop a weak-label classification module to enforce the network to attend to certain categories, and then use such training signals to guide the proposed category-wise alignment method. In experiments, we show considerable improvements with respect to the existing state-of-the-arts in UDA and present a new benchmark in the WDA setting. Project page is at http://www.nec-labs.com/~mas/WeakSegDA.
Mixup-CAM: Weakly-supervised Semantic Segmentation via Uncertainty Regularization
Aug 03, 2020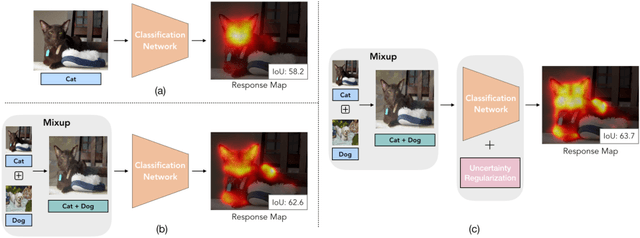
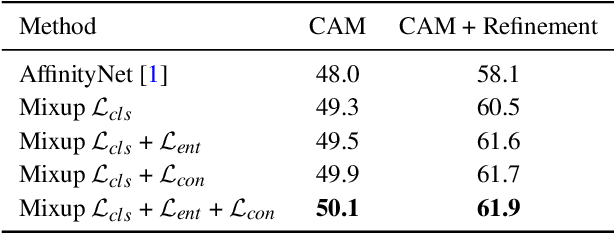
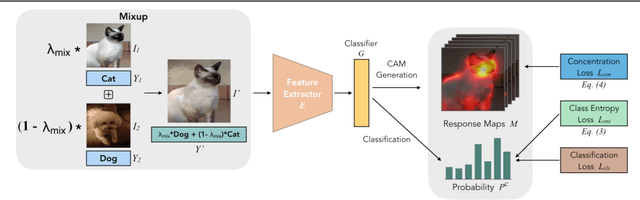
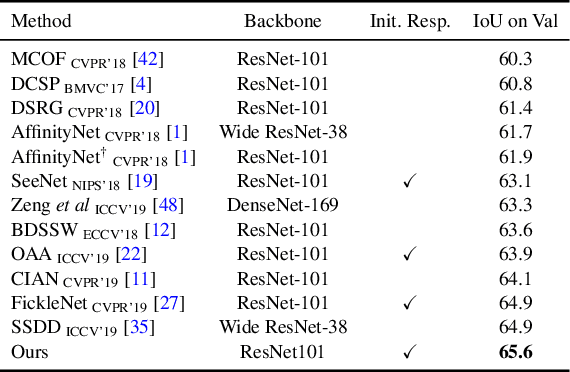
Obtaining object response maps is one important step to achieve weakly-supervised semantic segmentation using image-level labels. However, existing methods rely on the classification task, which could result in a response map only attending on discriminative object regions as the network does not need to see the entire object for optimizing the classification loss. To tackle this issue, we propose a principled and end-to-end train-able framework to allow the network to pay attention to other parts of the object, while producing a more complete and uniform response map. Specifically, we introduce the mixup data augmentation scheme into the classification network and design two uncertainty regularization terms to better interact with the mixup strategy. In experiments, we conduct extensive analysis to demonstrate the proposed method and show favorable performance against state-of-the-art approaches.
Weakly-Supervised Semantic Segmentation via Sub-category Exploration
Aug 03, 2020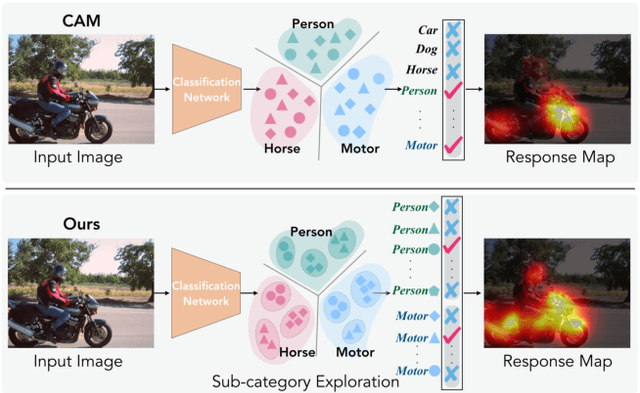
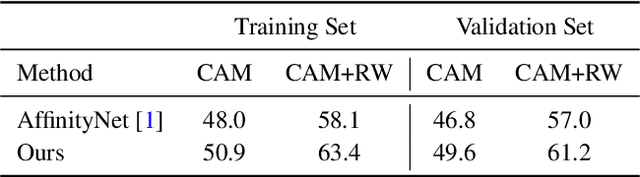
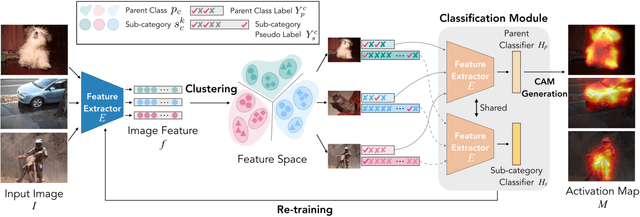
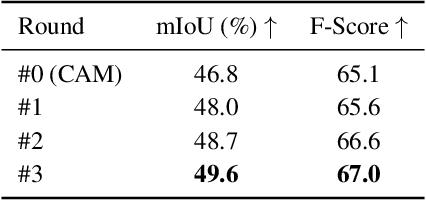
Existing weakly-supervised semantic segmentation methods using image-level annotations typically rely on initial responses to locate object regions. However, such response maps generated by the classification network usually focus on discriminative object parts, due to the fact that the network does not need the entire object for optimizing the objective function. To enforce the network to pay attention to other parts of an object, we propose a simple yet effective approach that introduces a self-supervised task by exploiting the sub-category information. Specifically, we perform clustering on image features to generate pseudo sub-categories labels within each annotated parent class, and construct a sub-category objective to assign the network to a more challenging task. By iteratively clustering image features, the training process does not limit itself to the most discriminative object parts, hence improving the quality of the response maps. We conduct extensive analysis to validate the proposed method and show that our approach performs favorably against the state-of-the-art approaches.
Regularizing Meta-Learning via Gradient Dropout
Apr 13, 2020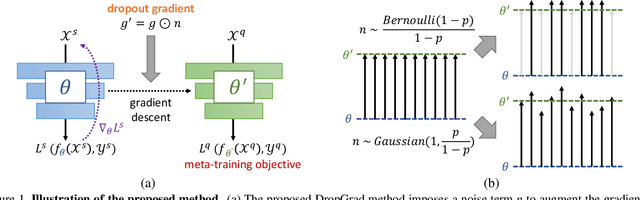
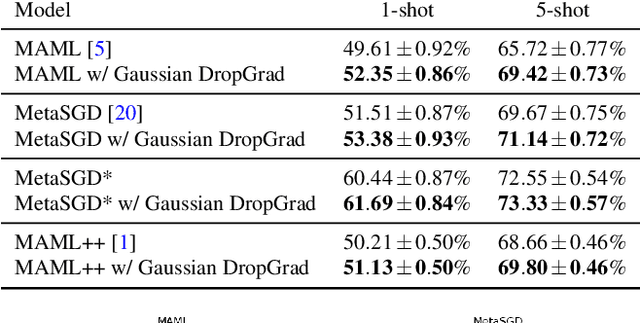
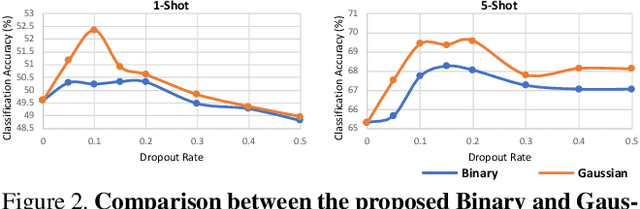
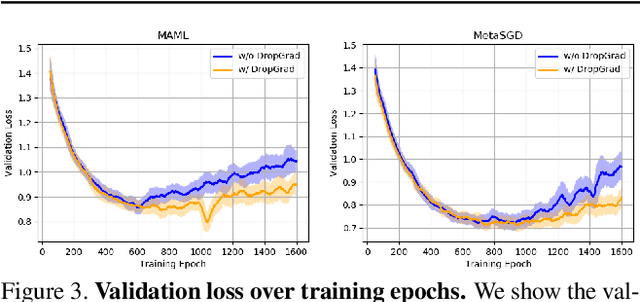
With the growing attention on learning-to-learn new tasks using only a few examples, meta-learning has been widely used in numerous problems such as few-shot classification, reinforcement learning, and domain generalization. However, meta-learning models are prone to overfitting when there are no sufficient training tasks for the meta-learners to generalize. Although existing approaches such as Dropout are widely used to address the overfitting problem, these methods are typically designed for regularizing models of a single task in supervised training. In this paper, we introduce a simple yet effective method to alleviate the risk of overfitting for gradient-based meta-learning. Specifically, during the gradient-based adaptation stage, we randomly drop the gradient in the inner-loop optimization of each parameter in deep neural networks, such that the augmented gradients improve generalization to new tasks. We present a general form of the proposed gradient dropout regularization and show that this term can be sampled from either the Bernoulli or Gaussian distribution. To validate the proposed method, we conduct extensive experiments and analysis on numerous computer vision tasks, demonstrating that the gradient dropout regularization mitigates the overfitting problem and improves the performance upon various gradient-based meta-learning frameworks.
LayoutMP3D: Layout Annotation of Matterport3D
Mar 30, 2020
Inferring the information of 3D layout from a single equirectangular panorama is crucial for numerous applications of virtual reality or robotics (e.g., scene understanding and navigation). To achieve this, several datasets are collected for the task of 360 layout estimation. To facilitate the learning algorithms for autonomous systems in indoor scenarios, we consider the Matterport3D dataset with their originally provided depth map ground truths and further release our annotations for layout ground truths from a subset of Matterport3D. As Matterport3D contains accurate depth ground truths from time-of-flight (ToF) sensors, our dataset provides both the layout and depth information, which enables the opportunity to explore the environment by integrating both cues.
Adversarial Learning of Privacy-Preserving and Task-Oriented Representations
Nov 22, 2019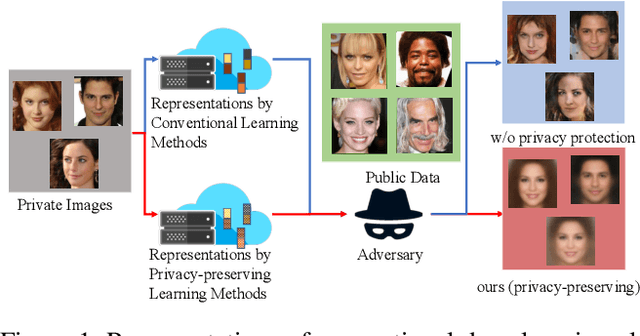
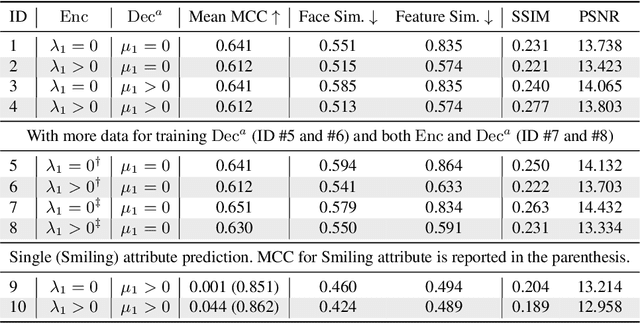
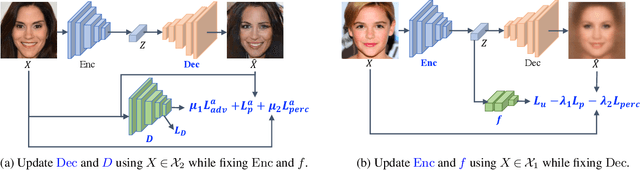
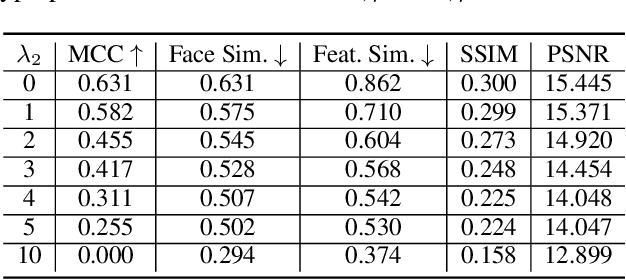
Data privacy has emerged as an important issue as data-driven deep learning has been an essential component of modern machine learning systems. For instance, there could be a potential privacy risk of machine learning systems via the model inversion attack, whose goal is to reconstruct the input data from the latent representation of deep networks. Our work aims at learning a privacy-preserving and task-oriented representation to defend against such model inversion attacks. Specifically, we propose an adversarial reconstruction learning framework that prevents the latent representations decoded into original input data. By simulating the expected behavior of adversary, our framework is realized by minimizing the negative pixel reconstruction loss or the negative feature reconstruction (i.e., perceptual distance) loss. We validate the proposed method on face attribute prediction, showing that our method allows protecting visual privacy with a small decrease in utility performance. In addition, we show the utility-privacy trade-off with different choices of hyperparameter for negative perceptual distance loss at training, allowing service providers to determine the right level of privacy-protection with a certain utility performance. Moreover, we provide an extensive study with different selections of features, tasks, and the data to further analyze their influence on privacy protection.
360SD-Net: 360° Stereo Depth Estimation with Learnable Cost Volume
Nov 11, 2019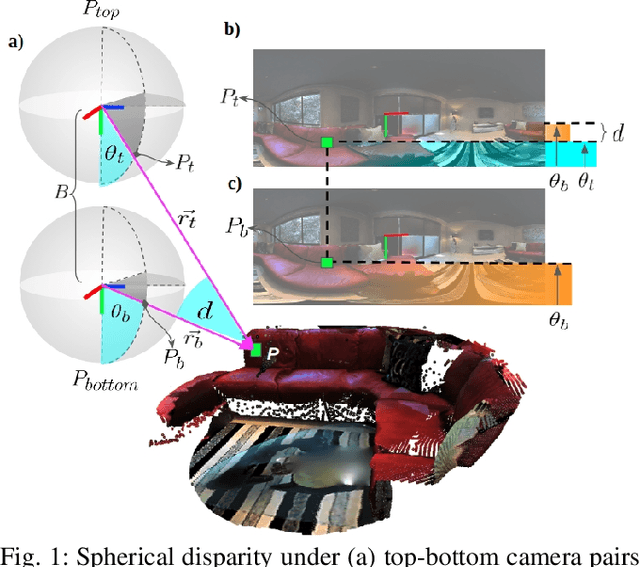
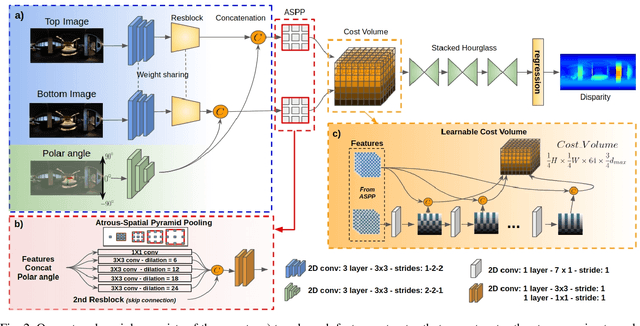
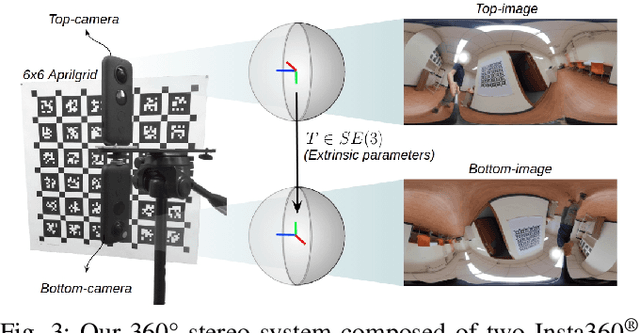
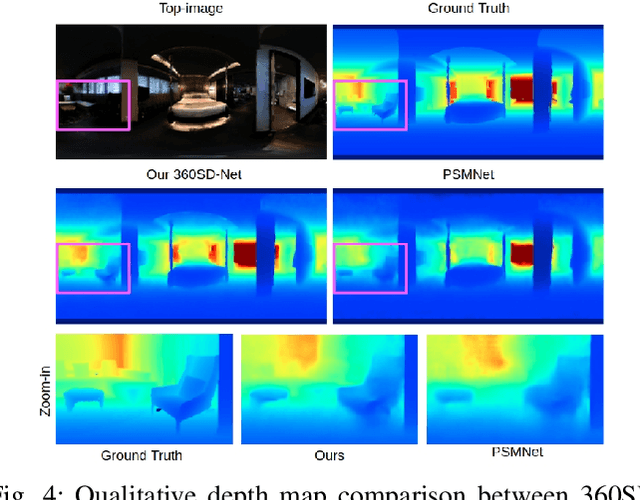
Recently, end-to-end trainable deep neural networks have significantly improved stereo depth estimation for perspective images. However, 360{\deg} images captured under equirectangular projection cannot benefit from directly adopting existing methods due to distortion introduced (i.e., lines in 3D are not projected onto lines in 2D). To tackle this issue, we present a novel architecture specifically designed for spherical disparity using the setting of top-bottom 360{\deg} camera pairs. Moreover, we propose to mitigate the distortion issue by (1) an additional input branch capturing the position and relation of each pixel in the spherical coordinate, and (2) a cost volume built upon a learnable shifting filter. Due to the lack of 360{\deg} stereo data, we collect two 360{\deg} stereo datasets from Matterport3D and Stanford3D for training and evaluation. Extensive experiments and ablation study are provided to validate our method against existing algorithms. Finally, we show promising results on real-world environments capturing images with two consumer-level cameras.
Progressive Domain Adaptation for Object Detection
Oct 24, 2019
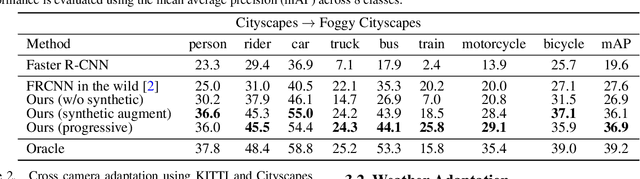
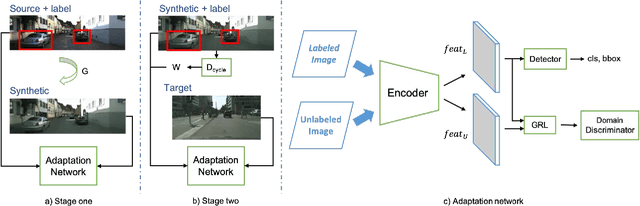
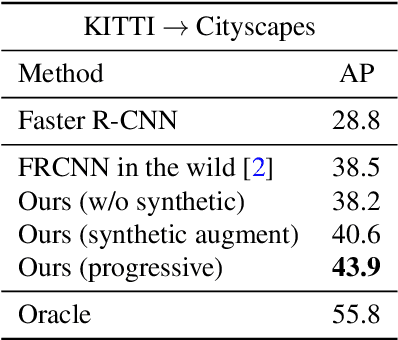
Recent deep learning methods for object detection rely on a large amount of bounding box annotations. Collecting these annotations is laborious and costly, yet supervised models do not generalize well when testing on images from a different distribution. Domain adaptation provides a solution by adapting existing labels to the target testing data. However, a large gap between domains could make adaptation a challenging task, which leads to unstable training processes and sub-optimal results. In this paper, we propose to bridge the domain gap with an intermediate domain and progressively solve easier adaptation subtasks. This intermediate domain is constructed by translating the source images to mimic the ones in the target domain. To tackle the domain-shift problem, we adopt adversarial learning to align distributions at the feature level. In addition, a weighted task loss is applied to deal with unbalanced image quality in the intermediate domain. Experimental results show that our method performs favorably against the state-of-the-art method in terms of the performance on the target domain.
Referring Expression Object Segmentation with Caption-Aware Consistency
Oct 10, 2019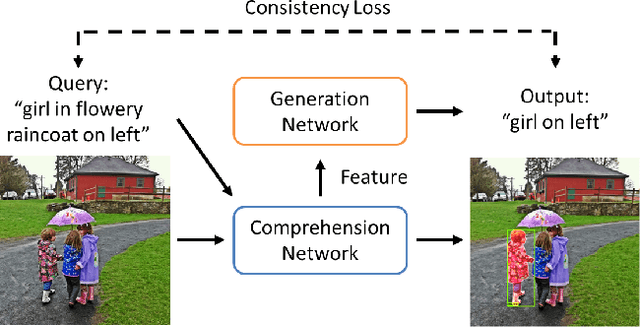
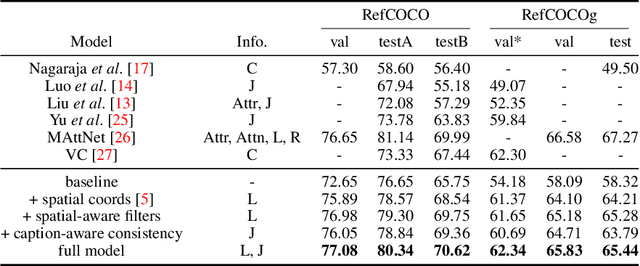
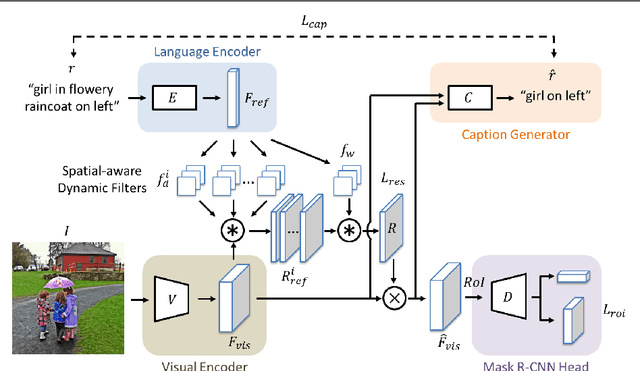
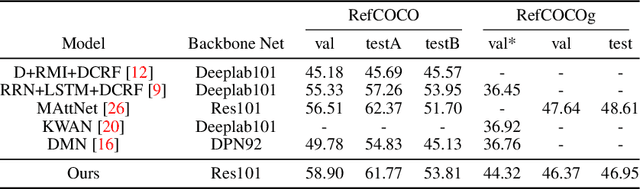
Referring expressions are natural language descriptions that identify a particular object within a scene and are widely used in our daily conversations. In this work, we focus on segmenting the object in an image specified by a referring expression. To this end, we propose an end-to-end trainable comprehension network that consists of the language and visual encoders to extract feature representations from both domains. We introduce the spatial-aware dynamic filters to transfer knowledge from text to image, and effectively capture the spatial information of the specified object. To better communicate between the language and visual modules, we employ a caption generation network that takes features shared across both domains as input, and improves both representations via a consistency that enforces the generated sentence to be similar to the given referring expression. We evaluate the proposed framework on two referring expression datasets and show that our method performs favorably against the state-of-the-art algorithms.
Adaptation Across Extreme Variations using Unlabeled Domain Bridges
Jun 05, 2019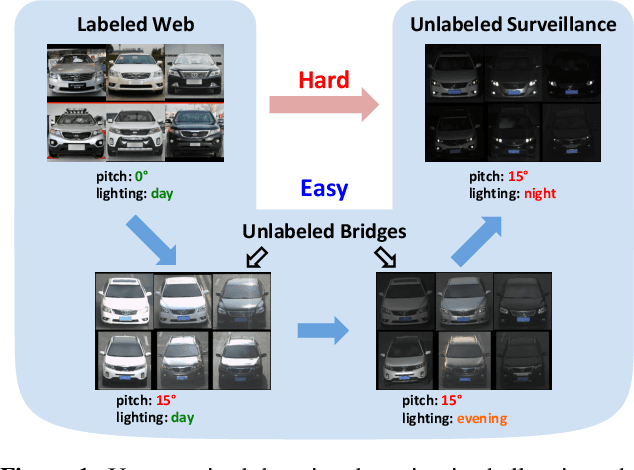


We tackle an unsupervised domain adaptation problem for which the domain discrepancy between labeled source and unlabeled target domains is large, due to many factors of inter and intra-domain variation. While deep domain adaptation methods have been realized by reducing the domain discrepancy, these are difficult to apply when domains are significantly unalike. In this work, we propose to decompose domain discrepancy into multiple but smaller, and thus easier to minimize, discrepancies by introducing unlabeled bridging domains that connect the source and target domains. We realize our proposal through an extension of the domain adversarial neural network with multiple discriminators, each of which accounts for reducing discrepancies between unlabeled (bridge, target) domains and a mix of all precedent domains including source. We validate the effectiveness of our method on several adaptation tasks including object recognition and semantic segmentation.