 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealisID: Scale-Robust and Fine-Controllable Identity Customization via Local and Global Complementation
Dec 22, 2024



Recently, the success of text-to-image synthesis has greatly advanced the development of identity customization techniques, whose main goal is to produce realistic identity-specific photographs based on text prompts and reference face images. However, it is difficult for existing identity customization methods to simultaneously meet the various requirements of different real-world applications, including the identity fidelity of small face, the control of face location, pose and expression, as well as the customization of multiple persons. To this end, we propose a scale-robust and fine-controllable method, namely RealisID, which learns different control capabilities through the cooperation between a pair of local and global branches. Specifically, by using cropping and up-sampling operations to filter out face-irrelevant information, the local branch concentrates the fine control of facial details and the scale-robust identity fidelity within the face region. Meanwhile, the global branch manages the overall harmony of the entire image. It also controls the face location by taking the location guidance as input. As a result, RealisID can benefit from the complementarity of these two branches. Finally, by implementing our branches with two different variants of ControlNet, our method can be easily extended to handle multi-person customization, even only trained on single-person datasets. Extensive experiments and ablation studies indicate the effectiveness of RealisID and verify its ability in fulfilling all the requirements mentioned above.
SHMT: Self-supervised Hierarchical Makeup Transfer via Latent Diffusion Models
Dec 15, 2024



This paper studies the challenging task of makeup transfer, which aims to apply diverse makeup styles precisely and naturally to a given facial image. Due to the absence of paired data, current methods typically synthesize sub-optimal pseudo ground truths to guide the model training, resulting in low makeup fidelity. Additionally, different makeup styles generally have varying effects on the person face, but existing methods struggle to deal with this diversity. To address these issues, we propose a novel Self-supervised Hierarchical Makeup Transfer (SHMT) method via latent diffusion models. Following a "decoupling-and-reconstruction" paradigm, SHMT works in a self-supervised manner, freeing itself from the misguidance of imprecise pseudo-paired data. Furthermore, to accommodate a variety of makeup styles, hierarchical texture details are decomposed via a Laplacian pyramid and selectively introduced to the content representation. Finally, we design a novel Iterative Dual Alignment (IDA) module that dynamically adjusts the injection condition of the diffusion model, allowing the alignment errors caused by the domain gap between content and makeup representations to be corrected. Extensive quantitative and qualitative analyses demonstrate the effectiveness of our method. Our code is available at \url{https://github.com/Snowfallingplum/SHMT}.
Visual Grounding with Multi-modal Conditional Adaptation
Sep 08, 2024



Visual grounding is the task of locating objects specified by natural language expressions. Existing methods extend generic object detection frameworks to tackle this task. They typically extract visual and textual features separately using independent visual and textual encoders, then fuse these features in a multi-modal decoder for final prediction. However, visual grounding presents unique challenges. It often involves locating objects with different text descriptions within the same image. Existing methods struggle with this task because the independent visual encoder produces identical visual features for the same image, limiting detection performance. Some recently approaches propose various language-guided visual encoders to address this issue, but they mostly rely solely on textual information and require sophisticated designs. In this paper, we introduce Multi-modal Conditional Adaptation (MMCA), which enables the visual encoder to adaptively update weights, directing its focus towards text-relevant regions. Specifically, we first integrate information from different modalities to obtain multi-modal embeddings. Then we utilize a set of weighting coefficients, which generated from the multimodal embeddings, to reorganize the weight update matrices and apply them to the visual encoder of the visual grounding model. Extensive experiments on four widely used datasets demonstrate that MMCA achieves significant improvements and state-of-the-art results. Ablation experiments further demonstrate the lightweight and efficiency of our method. Our source code is available at: https://github.com/Mr-Bigworth/MMCA.
Content-Style Decoupling for Unsupervised Makeup Transfer without Generating Pseudo Ground Truth
May 27, 2024The absence of real targets to guide the model training is one of the main problems with the makeup transfer task. Most existing methods tackle this problem by synthesizing pseudo ground truths (PGTs). However, the generated PGTs are often sub-optimal and their imprecision will eventually lead to performance degradation. To alleviate this issue, in this paper, we propose a novel Content-Style Decoupled Makeup Transfer (CSD-MT) method, which works in a purely unsupervised manner and thus eliminates the negative effects of generating PGTs. Specifically, based on the frequency characteristics analysis, we assume that the low-frequency (LF) component of a face image is more associated with its makeup style information, while the high-frequency (HF) component is more related to its content details. This assumption allows CSD-MT to decouple the content and makeup style information in each face image through the frequency decomposition. After that, CSD-MT realizes makeup transfer by maximizing the consistency of these two types of information between the transferred result and input images, respectively. Two newly designed loss functions are also introduced to further improve the transfer performance. Extensive quantitative and qualitative analyses show the effectiveness of our CSD-MT method. Our code is available at https://github.com/Snowfallingplum/CSD-MT.
ICST-DNET: An Interpretable Causal Spatio-Temporal Diffusion Network for Traffic Speed Prediction
Apr 22, 2024



Traffic speed prediction is significant for intelligent navigation and congestion alleviation. However, making accurate predictions is challenging due to three factors: 1) traffic diffusion, i.e., the spatial and temporal causality existing between the traffic conditions of multiple neighboring roads, 2) the poor interpretability of traffic data with complicated spatio-temporal correlations, and 3) the latent pattern of traffic speed fluctuations over time, such as morning and evening rush. Jointly considering these factors, in this paper, we present a novel architecture for traffic speed prediction, called Interpretable Causal Spatio-Temporal Diffusion Network (ICST-DNET). Specifically, ICST-DENT consists of three parts, namely the Spatio-Temporal Causality Learning (STCL), Causal Graph Generation (CGG), and Speed Fluctuation Pattern Recognition (SFPR) modules. First, to model the traffic diffusion within road networks, an STCL module is proposed to capture both the temporal causality on each individual road and the spatial causality in each road pair. The CGG module is then developed based on STCL to enhance the interpretability of the traffic diffusion procedure from the temporal and spatial perspectives. Specifically, a time causality matrix is generated to explain the temporal causality between each road's historical and future traffic conditions. For spatial causality, we utilize causal graphs to visualize the diffusion process in road pairs. Finally, to adapt to traffic speed fluctuations in different scenarios, we design a personalized SFPR module to select the historical timesteps with strong influences for learning the pattern of traffic speed fluctuations. Extensive experimental results prove that ICST-DNET can outperform all existing baselines, as evidenced by the higher prediction accuracy, ability to explain causality, and adaptability to different scenarios.
CRA-PCN: Point Cloud Completion with Intra- and Inter-level Cross-Resolution Transformers
Jan 03, 2024



Point cloud completion is an indispensable task for recovering complete point clouds due to incompleteness caused by occlusion, limited sensor resolution, etc. The family of coarse-to-fine generation architectures has recently exhibited great success in point cloud completion and gradually became mainstream. In this work, we unveil one of the key ingredients behind these methods: meticulously devised feature extraction operations with explicit cross-resolution aggregation. We present Cross-Resolution Transformer that efficiently performs cross-resolution aggregation with local attention mechanisms. With the help of our recursive designs, the proposed operation can capture more scales of features than common aggregation operations, which is beneficial for capturing fine geometric characteristics. While prior methodologies have ventured into various manifestations of inter-level cross-resolution aggregation, the effectiveness of intra-level one and their combination has not been analyzed. With unified designs, Cross-Resolution Transformer can perform intra- or inter-level cross-resolution aggregation by switching inputs. We integrate two forms of Cross-Resolution Transformers into one up-sampling block for point generation, and following the coarse-to-fine manner, we construct CRA-PCN to incrementally predict complete shapes with stacked up-sampling blocks. Extensive experiments demonstrate that our method outperforms state-of-the-art methods by a large margin on several widely used benchmarks. Codes are available at https://github.com/EasyRy/CRA-PCN.
ESPT: A Self-Supervised Episodic Spatial Pretext Task for Improving Few-Shot Learning
Apr 26, 2023



Self-supervised learning (SSL) techniques have recently been integrated into the few-shot learning (FSL) framework and have shown promising results in improving the few-shot image classification performance. However, existing SSL approaches used in FSL typically seek the supervision signals from the global embedding of every single image. Therefore, during the episodic training of FSL, these methods cannot capture and fully utilize the local visual information in image samples and the data structure information of the whole episode, which are beneficial to FSL. To this end, we propose to augment the few-shot learning objective with a novel self-supervised Episodic Spatial Pretext Task (ESPT). Specifically, for each few-shot episode, we generate its corresponding transformed episode by applying a random geometric transformation to all the images in it. Based on these, our ESPT objective is defined as maximizing the local spatial relationship consistency between the original episode and the transformed one. With this definition, the ESPT-augmented FSL objective promotes learning more transferable feature representations that capture the local spatial features of different images and their inter-relational structural information in each input episode, thus enabling the model to generalize better to new categories with only a few samples. Extensive experiments indicate that our ESPT method achieves new state-of-the-art performance for few-shot image classification on three mainstay benchmark datasets. The source code will be available at: https://github.com/Whut-YiRong/ESPT.
ODSearch: A Fast and Resource Efficient On-device Information Retrieval for Mobile and Wearable Devices
Jan 31, 2022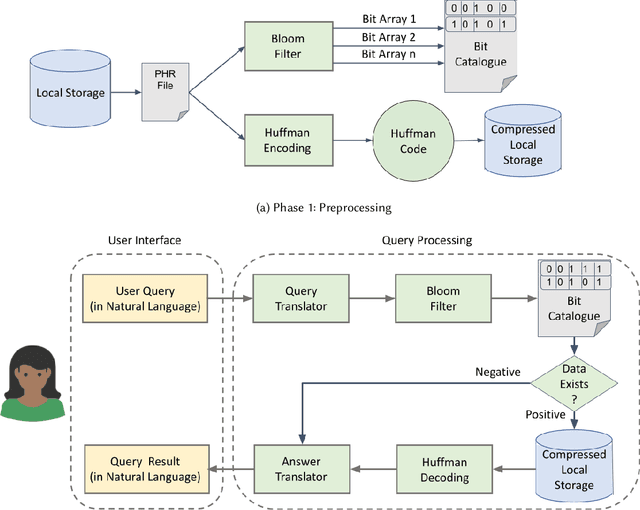
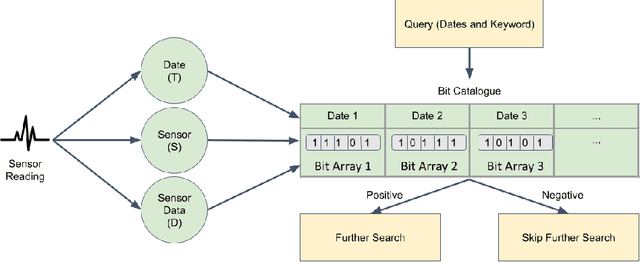

Mobile and wearable technologies have promised significant changes to the healthcare industry. Although cutting-edge communication and cloud-based technologies have allowed for these upgrades, their implementation and popularization in low-income countries have been challenging. We propose ODSearch, an On-device Search framework equipped with a natural language interface for mobile and wearable devices. To implement search, ODSearch employs compression and Bloom filter, it provides near real-time search query responses without network dependency. Our experiments were conducted on a mobile phone and smartwatch. We compared ODSearch with current state-of-the-art search mechanisms, and it outperformed them on average by 55 times in execution time, 26 times in energy usage, and 2.3% in memory utilization.
Auto-MAP: A DQN Framework for Exploring Distributed Execution Plans for DNN Workloads
Jul 08, 2020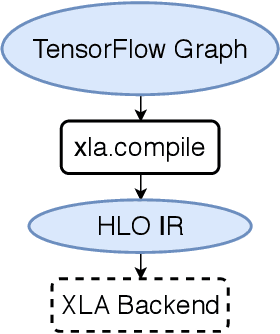
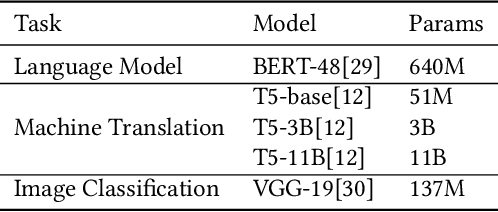
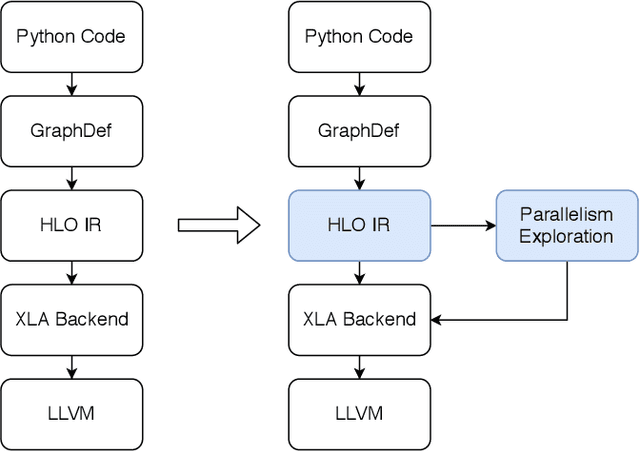

The last decade has witnessed growth in the computational requirements for training deep neural networks. Current approaches (e.g., data/model parallelism, pipeline parallelism) parallelize training tasks onto multiple devices. However, these approaches always rely on specific deep learning frameworks and requires elaborate manual design, which make it difficult to maintain and share between different type of models. In this paper, we propose Auto-MAP, a framework for exploring distributed execution plans for DNN workloads, which can automatically discovering fast parallelization strategies through reinforcement learning on IR level of deep learning models. Efficient exploration remains a major challenge for reinforcement learning. We leverage DQN with task-specific pruning strategies to help efficiently explore the search space including optimized strategies. Our evaluation shows that Auto-MAP can find the optimal solution in two hours, while achieving better throughput on several NLP and convolution models.