 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Memory as a Differentiable Search Index
Feb 16, 2022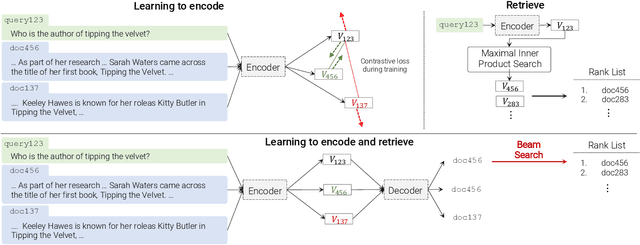
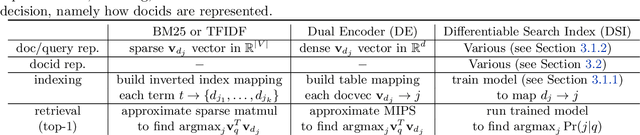
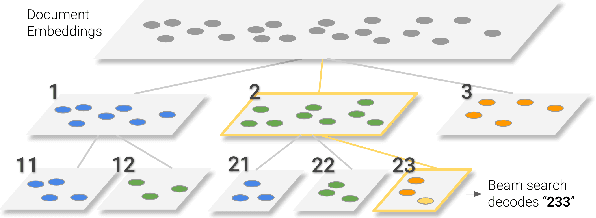
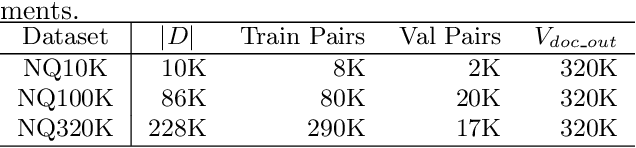
In this paper, we demonstrate that information retrieval can be accomplished with a single Transformer, in which all information about the corpus is encoded in the parameters of the model. To this end, we introduce the Differentiable Search Index (DSI), a new paradigm that learns a text-to-text model that maps string queries directly to relevant docids; in other words, a DSI model answers queries directly using only its parameters, dramatically simplifying the whole retrieval process. We study variations in how documents and their identifiers are represented, variations in training procedures, and the interplay between models and corpus sizes. Experiments demonstrate that given appropriate design choices, DSI significantly outperforms strong baselines such as dual encoder models. Moreover, DSI demonstrates strong generalization capabilities, outperforming a BM25 baseline in a zero-shot setup.
PolyViT: Co-training Vision Transformers on Images, Videos and Audio
Nov 25, 2021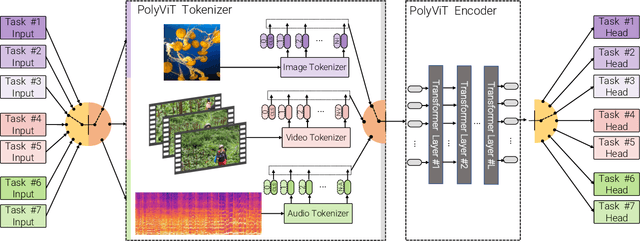
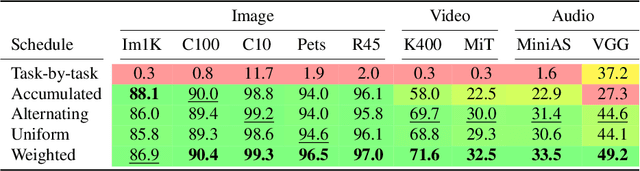
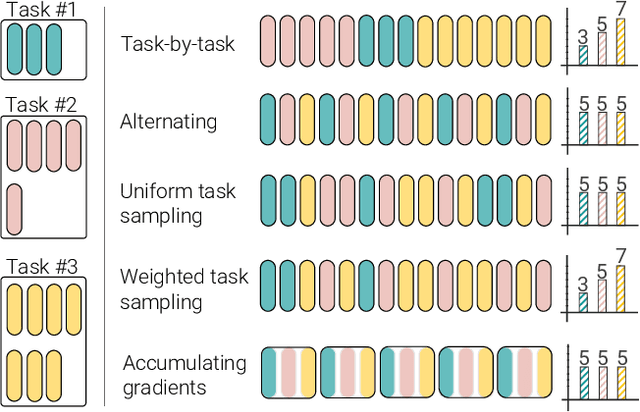
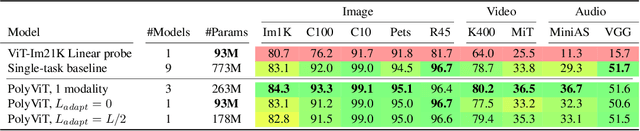
Can we train a single transformer model capable of processing multiple modalities and datasets, whilst sharing almost all of its learnable parameters? We present PolyViT, a model trained on image, audio and video which answers this question. By co-training different tasks on a single modality, we are able to improve the accuracy of each individual task and achieve state-of-the-art results on 5 standard video- and audio-classification datasets. Co-training PolyViT on multiple modalities and tasks leads to a model that is even more parameter-efficient, and learns representations that generalize across multiple domains. Moreover, we show that co-training is simple and practical to implement, as we do not need to tune hyperparameters for each combination of datasets, but can simply adapt those from standard, single-task training.
ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning
Nov 22, 2021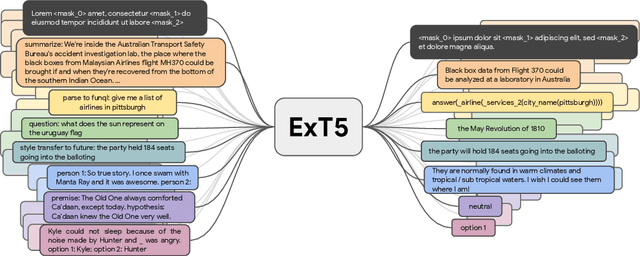
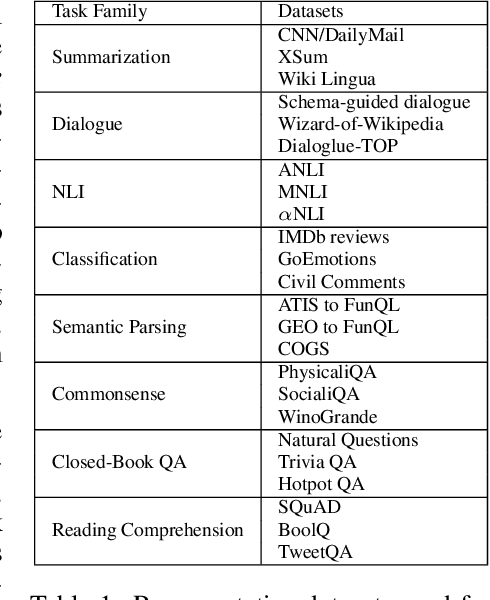
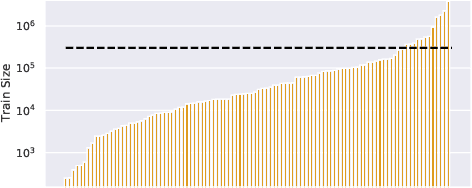
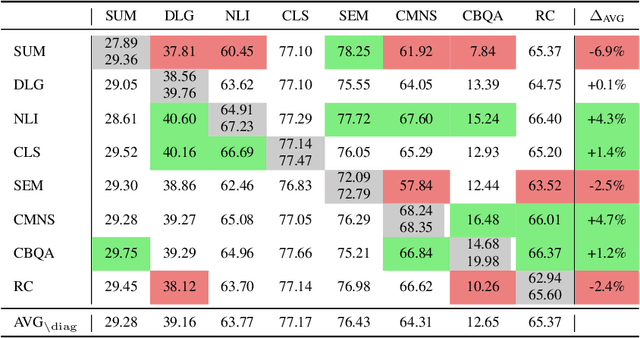
Despite the recent success of multi-task learning and transfer learning for natural language processing (NLP), few works have systematically studied the effect of scaling up the number of tasks during pre-training. Towards this goal, this paper introduces ExMix (Extreme Mixture): a massive collection of 107 supervised NLP tasks across diverse domains and task-families. Using ExMix, we study the effect of multi-task pre-training at the largest scale to date, and analyze co-training transfer amongst common families of tasks. Through this analysis, we show that manually curating an ideal set of tasks for multi-task pre-training is not straightforward, and that multi-task scaling can vastly improve models on its own. Finally, we propose ExT5: a model pre-trained using a multi-task objective of self-supervised span denoising and supervised ExMix. Via extensive experiments, we show that ExT5 outperforms strong T5 baselines on SuperGLUE, GEM, Rainbow, Closed-Book QA tasks, and several tasks outside of ExMix. ExT5 also significantly improves sample efficiency while pre-training.
The Efficiency Misnomer
Oct 25, 2021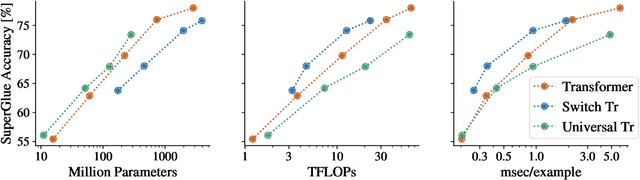
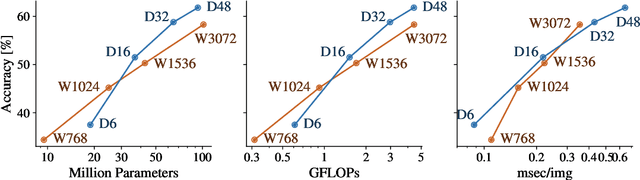
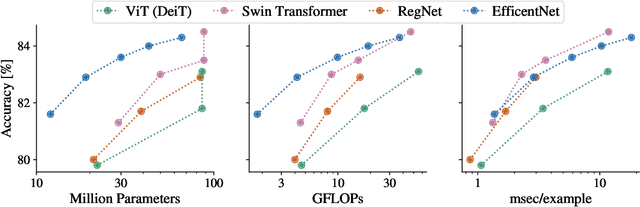
Model efficiency is a critical aspect of developing and deploying machine learning models. Inference time and latency directly affect the user experience, and some applications have hard requirements. In addition to inference costs, model training also have direct financial and environmental impacts. Although there are numerous well-established metrics (cost indicators) for measuring model efficiency, researchers and practitioners often assume that these metrics are correlated with each other and report only few of them. In this paper, we thoroughly discuss common cost indicators, their advantages and disadvantages, and how they can contradict each other. We demonstrate how incomplete reporting of cost indicators can lead to partial conclusions and a blurred or incomplete picture of the practical considerations of different models. We further present suggestions to improve reporting of efficiency metrics.
SCENIC: A JAX Library for Computer Vision Research and Beyond
Oct 18, 2021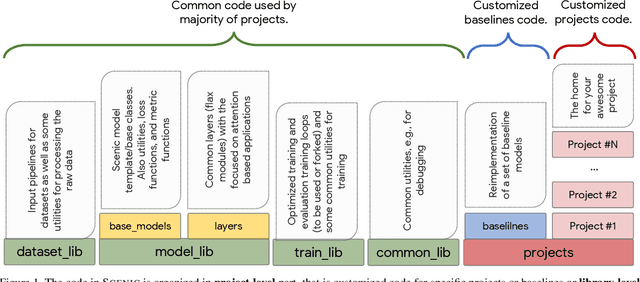
Scenic is an open-source JAX library with a focus on Transformer-based models for computer vision research and beyond. The goal of this toolkit is to facilitate rapid experimentation, prototyping, and research of new vision architectures and models. Scenic supports a diverse range of vision tasks (e.g., classification, segmentation, detection)and facilitates working on multi-modal problems, along with GPU/TPU support for multi-host, multi-device large-scale training. Scenic also offers optimized implementations of state-of-the-art research models spanning a wide range of modalities. Scenic has been successfully used for numerous projects and published papers and continues serving as the library of choice for quick prototyping and publication of new research ideas.
Sharpness-Aware Minimization Improves Language Model Generalization
Oct 16, 2021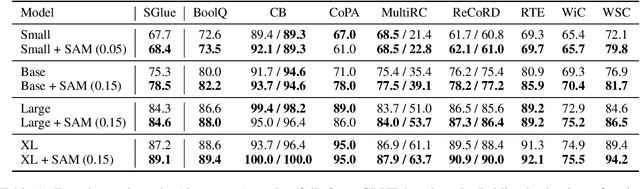
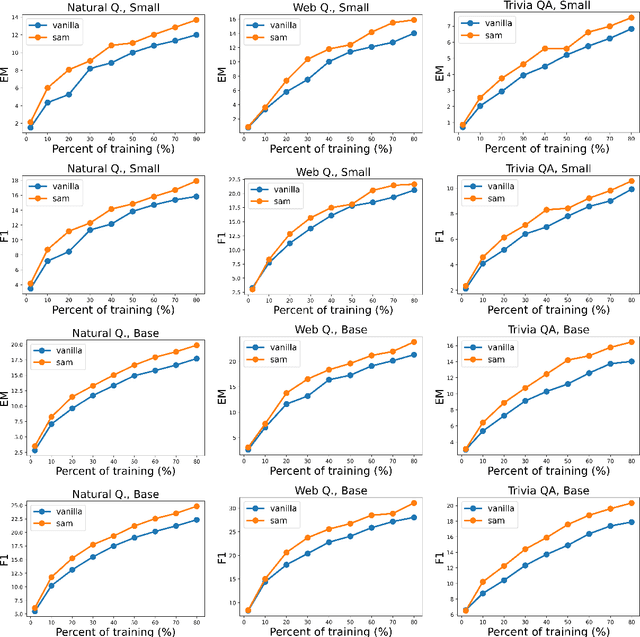
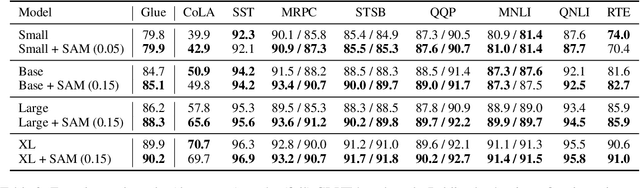
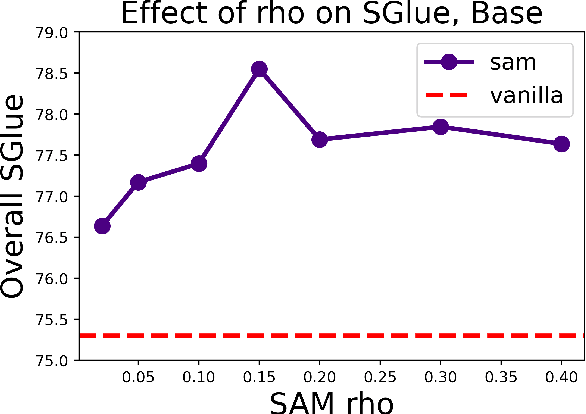
The allure of superhuman-level capabilities has led to considerable interest in language models like GPT-3 and T5, wherein the research has, by and large, revolved around new model architectures, training tasks, and loss objectives, along with substantial engineering efforts to scale up model capacity and dataset size. Comparatively little work has been done to improve the generalization of these models through better optimization. In this work, we show that Sharpness-Aware Minimization (SAM), a recently proposed optimization procedure that encourages convergence to flatter minima, can substantially improve the generalization of language models without much computational overhead. We show that SAM is able to boost performance on SuperGLUE, GLUE, Web Questions, Natural Questions, Trivia QA, and TyDiQA, with particularly large gains when training data for these tasks is limited.
Improving Compositional Generalization with Self-Training for Data-to-Text Generation
Oct 16, 2021
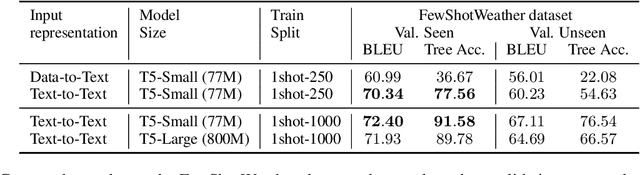


Data-to-text generation focuses on generating fluent natural language responses from structured semantic representations. Such representations are compositional, allowing for the combination of atomic meaning schemata in various ways to express the rich semantics in natural language. Recently, pretrained language models (LMs) have achieved impressive results on data-to-text tasks, though it remains unclear the extent to which these LMs generalize to new semantic representations. In this work, we systematically study the compositional generalization of current state-of-the-art generation models in data-to-text tasks. By simulating structural shifts in the compositional Weather dataset, we show that T5 models fail to generalize to unseen structures. Next, we show that template-based input representations greatly improve the model performance and model scale does not trivially solve the lack of generalization. To further improve the model's performance, we propose an approach based on self-training using finetuned BLEURT for pseudo-response selection. Extensive experiments on the few-shot Weather and multi-domain SGD datasets demonstrate strong gains of our method.
Born Again Neural Rankers
Sep 30, 2021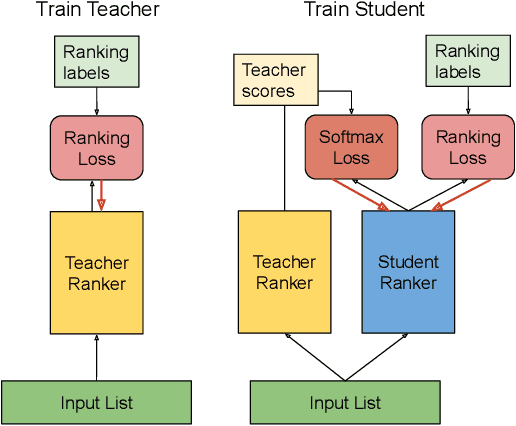
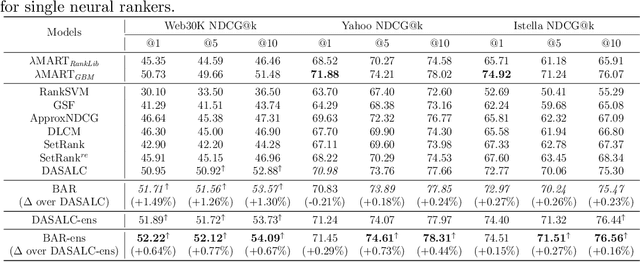
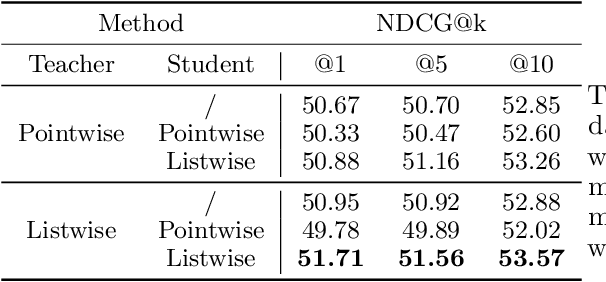
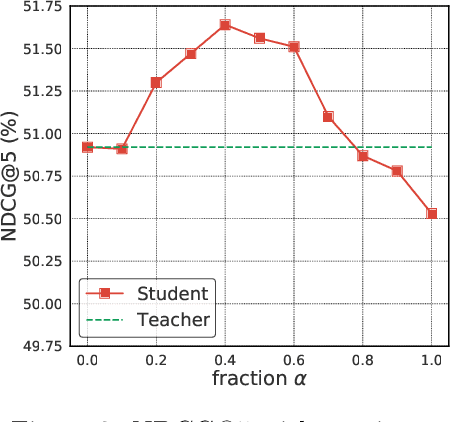
We introduce Born Again neural Rankers (BAR) in the Learning to Rank (LTR) setting, where student rankers, trained in the Knowledge Distillation (KD) framework, are parameterized identically to their teachers. Unlike the existing ranking distillation work which pursues a good trade-off between performance and efficiency, BAR adapts the idea of Born Again Networks (BAN) to ranking problems and significantly improves ranking performance of students over the teacher rankers without increasing model capacity. The key differences between BAR and common distillation techniques for classification are: (1) an appropriate teacher score transformation function, and (2) a novel listwise distillation framework. Both techniques are specifically designed for ranking problems and are rarely studied in the knowledge distillation literature. Using the state-of-the-art neural ranking structure, BAR is able to push the limits of neural rankers above a recent rigorous benchmark study and significantly outperforms traditionally strong gradient boosted decision tree based models on 7 out of 9 key metrics, the first time in the literature. In addition to the strong empirical results, we give theoretical explanations on why listwise distillation is effective for neural rankers.
Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers
Sep 22, 2021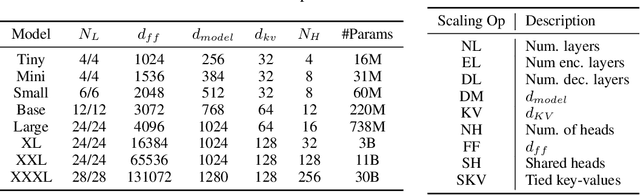
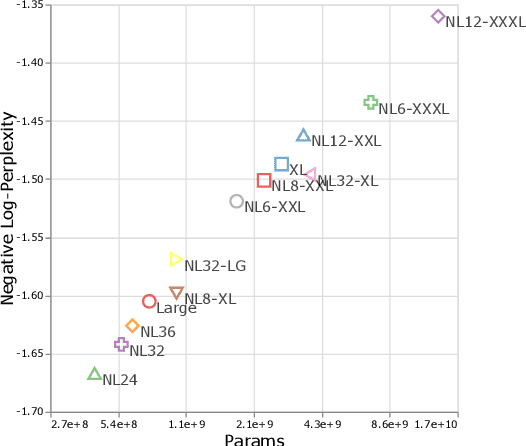
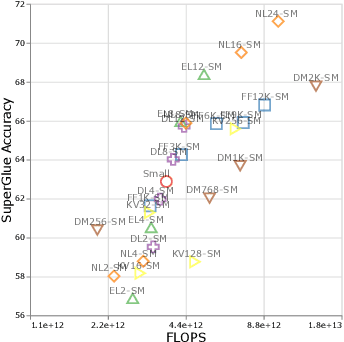
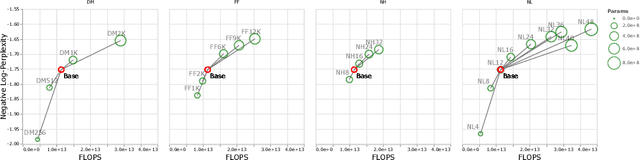
There remain many open questions pertaining to the scaling behaviour of Transformer architectures. These scaling decisions and findings can be critical, as training runs often come with an associated computational cost which have both financial and/or environmental impact. The goal of this paper is to present scaling insights from pretraining and finetuning Transformers. While Kaplan et al. presents a comprehensive study of the scaling behaviour of Transformer language models, the scope is only on the upstream (pretraining) loss. Therefore, it is still unclear if these set of findings transfer to downstream task within the context of the pretrain-finetune paradigm. The key findings of this paper are as follows: (1) we show that aside from only the model size, model shape matters for downstream fine-tuning, (2) scaling protocols operate differently at different compute regions, (3) widely adopted T5-base and T5-large sizes are Pareto-inefficient. To this end, we present improved scaling protocols whereby our redesigned models achieve similar downstream fine-tuning quality while having 50\% fewer parameters and training 40\% faster compared to the widely adopted T5-base model. We publicly release over 100 pretrained checkpoints of different T5 configurations to facilitate future research and analysis.
The Benchmark Lottery
Jul 14, 2021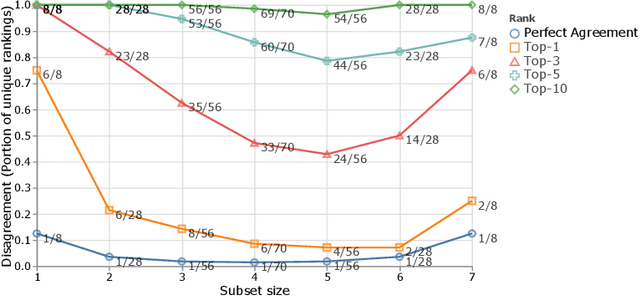

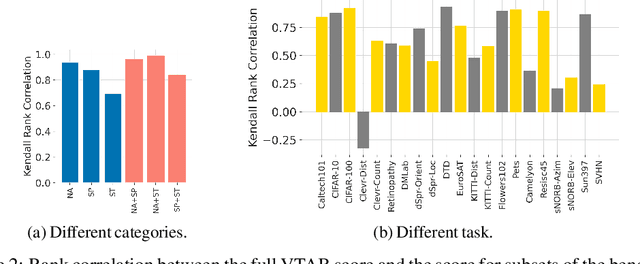
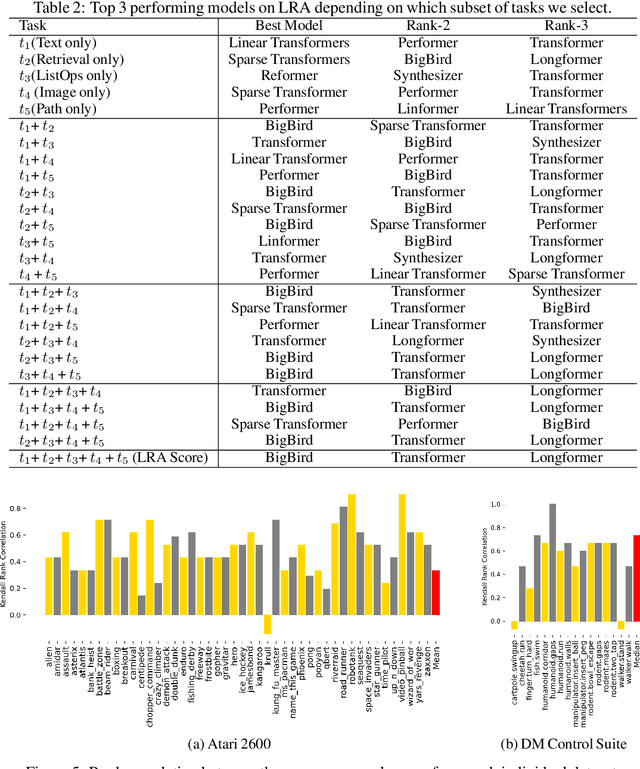
The world of empirical machine learning (ML) strongly relies on benchmarks in order to determine the relative effectiveness of different algorithms and methods. This paper proposes the notion of "a benchmark lottery" that describes the overall fragility of the ML benchmarking process. The benchmark lottery postulates that many factors, other than fundamental algorithmic superiority, may lead to a method being perceived as superior. On multiple benchmark setups that are prevalent in the ML community, we show that the relative performance of algorithms may be altered significantly simply by choosing different benchmark tasks, highlighting the fragility of the current paradigms and potential fallacious interpretation derived from benchmarking ML methods. Given that every benchmark makes a statement about what it perceives to be important, we argue that this might lead to biased progress in the community. We discuss the implications of the observed phenomena and provide recommendations on mitigating them using multiple machine learning domains and communities as use cases, including natural language processing, computer vision, information retrieval, recommender systems, and reinforcement learning.