 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Permission Manipulation: Can We Trust Large Multimodal Model Powered GUI Agents?
Jan 18, 2026Large multimodal model powered GUI agents are emerging as high-privilege operators on mobile platforms, entrusted with perceiving screen content and injecting inputs. However, their design operates under the implicit assumption of Visual Atomicity: that the UI state remains invariant between observation and action. We demonstrate that this assumption is fundamentally invalid in Android, creating a critical attack surface. We present Action Rebinding, a novel attack that allows a seemingly-benign app with zero dangerous permissions to rebind an agent's execution. By exploiting the inevitable observation-to-action gap inherent in the agent's reasoning pipeline, the attacker triggers foreground transitions to rebind the agent's planned action toward the target app. We weaponize the agent's task-recovery logic and Android's UI state preservation to orchestrate programmable, multi-step attack chains. Furthermore, we introduce an Intent Alignment Strategy (IAS) that manipulates the agent's reasoning process to rationalize UI states, enabling it to bypass verification gates (e.g., confirmation dialogs) that would otherwise be rejected. We evaluate Action Rebinding Attacks on six widely-used Android GUI agents across 15 tasks. Our results demonstrate a 100% success rate for atomic action rebinding and the ability to reliably orchestrate multi-step attack chains. With IAS, the success rate in bypassing verification gates increases (from 0% to up to 100%). Notably, the attacker application requires no sensitive permissions and contains no privileged API calls, achieving a 0% detection rate across malware scanners (e.g., VirusTotal). Our findings reveal a fundamental architectural flaw in current agent-OS integration and provide critical insights for the secure design of future agent systems. To access experimental logs and demonstration videos, please contact yi_qian@smail.nju.edu.cn.
Boost Image Captioning with Knowledge Reasoning
Nov 02, 2020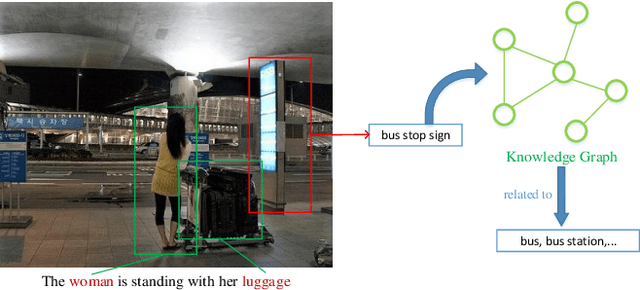
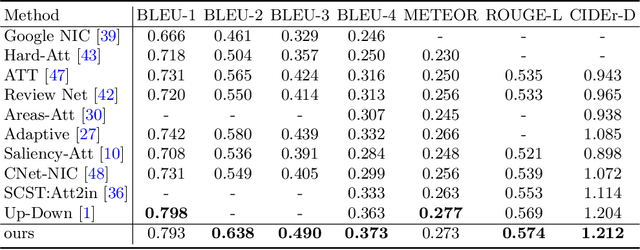
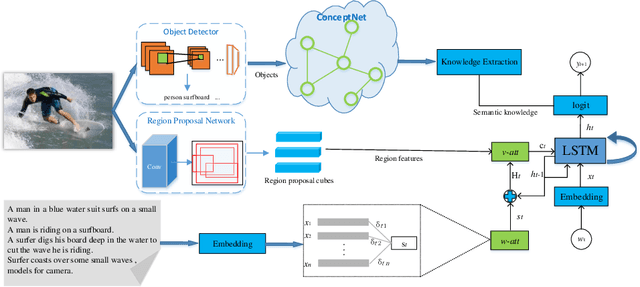

Automatically generating a human-like description for a given image is a potential research in artificial intelligence, which has attracted a great of attention recently. Most of the existing attention methods explore the mapping relationships between words in sentence and regions in image, such unpredictable matching manner sometimes causes inharmonious alignments that may reduce the quality of generated captions. In this paper, we make our efforts to reason about more accurate and meaningful captions. We first propose word attention to improve the correctness of visual attention when generating sequential descriptions word-by-word. The special word attention emphasizes on word importance when focusing on different regions of the input image, and makes full use of the internal annotation knowledge to assist the calculation of visual attention. Then, in order to reveal those incomprehensible intentions that cannot be expressed straightforwardly by machines, we introduce a new strategy to inject external knowledge extracted from knowledge graph into the encoder-decoder framework to facilitate meaningful captioning. Finally, we validate our model on two freely available captioning benchmarks: Microsoft COCO dataset and Flickr30k dataset. The results demonstrate that our approach achieves state-of-the-art performance and outperforms many of the existing approaches.