 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training via Denoising for Molecular Property Prediction
May 31, 2022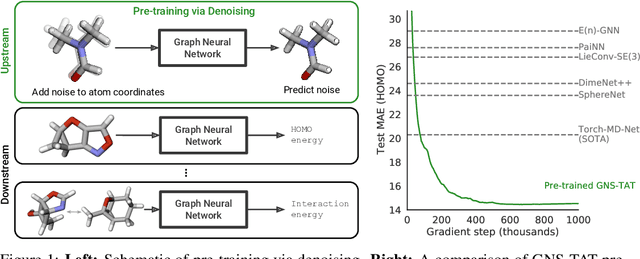
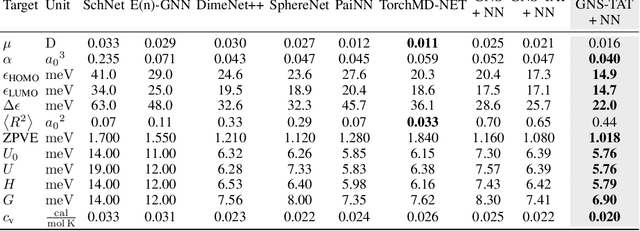
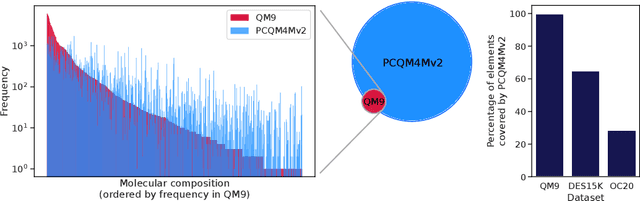
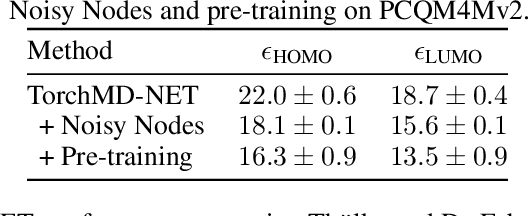
Many important problems involving molecular property prediction from 3D structures have limited data, posing a generalization challenge for neural networks. In this paper, we describe a pre-training technique that utilizes large datasets of 3D molecular structures at equilibrium to learn meaningful representations for downstream tasks. Inspired by recent advances in noise regularization, our pre-training objective is based on denoising. Relying on the well-known link between denoising autoencoders and score-matching, we also show that the objective corresponds to learning a molecular force field -- arising from approximating the physical state distribution with a mixture of Gaussians -- directly from equilibrium structures. Our experiments demonstrate that using this pre-training objective significantly improves performance on multiple benchmarks, achieving a new state-of-the-art on the majority of targets in the widely used QM9 dataset. Our analysis then provides practical insights into the effects of different factors -- dataset sizes, model size and architecture, and the choice of upstream and downstream datasets -- on pre-training.
Learning Instance-Specific Data Augmentations
May 31, 2022
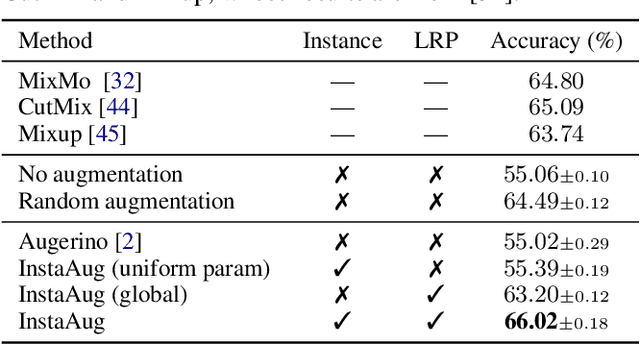
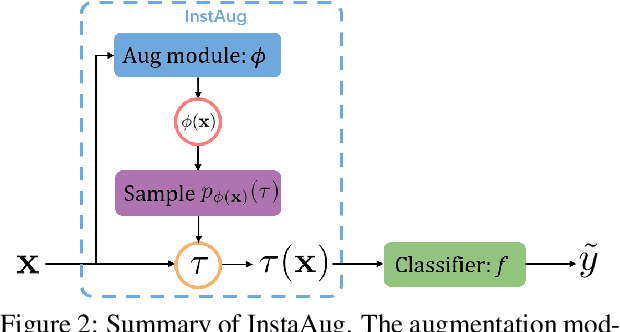
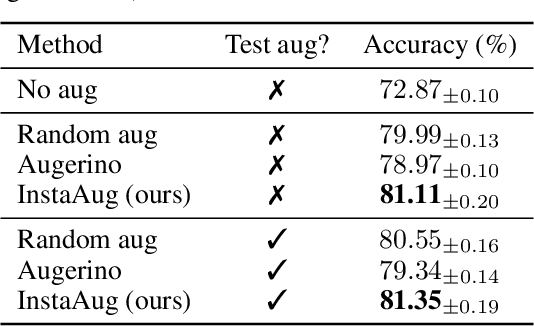
Existing data augmentation methods typically assume independence between transformations and inputs: they use the same transformation distribution for all input instances. We explain why this can be problematic and propose InstaAug, a method for automatically learning input-specific augmentations from data. This is achieved by introducing an augmentation module that maps an input to a distribution over transformations. This is simultaneously trained alongside the base model in a fully end-to-end manner using only the training data. We empirically demonstrate that InstaAug learns meaningful augmentations for a wide range of transformation classes, which in turn provides better performance on supervised and self-supervised tasks compared with augmentations that assume input--transformation independence.
Meta-Learning Sparse Compression Networks
May 18, 2022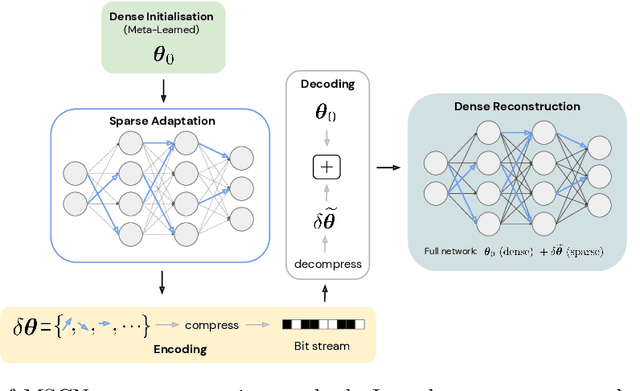
Recent work in Deep Learning has re-imagined the representation of data as functions mapping from a coordinate space to an underlying continuous signal. When such functions are approximated by neural networks this introduces a compelling alternative to the more common multi-dimensional array representation. Recent work on such Implicit Neural Representations (INRs) has shown that - following careful architecture search - INRs can outperform established compression methods such as JPEG (e.g. Dupont et al., 2021). In this paper, we propose crucial steps towards making such ideas scalable: Firstly, we employ stateof-the-art network sparsification techniques to drastically improve compression. Secondly, introduce the first method allowing for sparsification to be employed in the inner-loop of commonly used Meta-Learning algorithms, drastically improving both compression and the computational cost of learning INRs. The generality of this formalism allows us to present results on diverse data modalities such as images, manifolds, signed distance functions, 3D shapes and scenes, several of which establish new state-of-the-art results.
UncertaINR: Uncertainty Quantification of End-to-End Implicit Neural Representations for Computed Tomography
Feb 22, 2022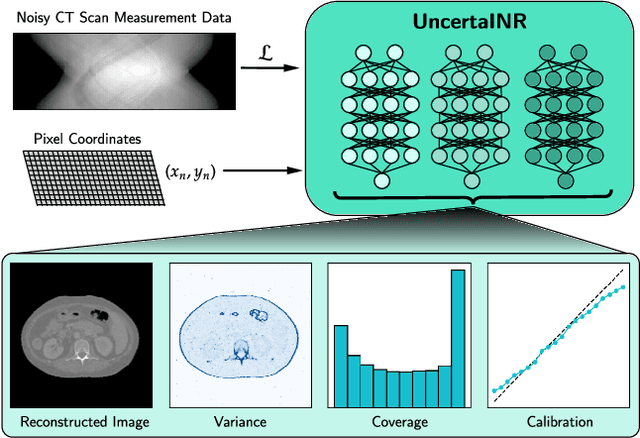
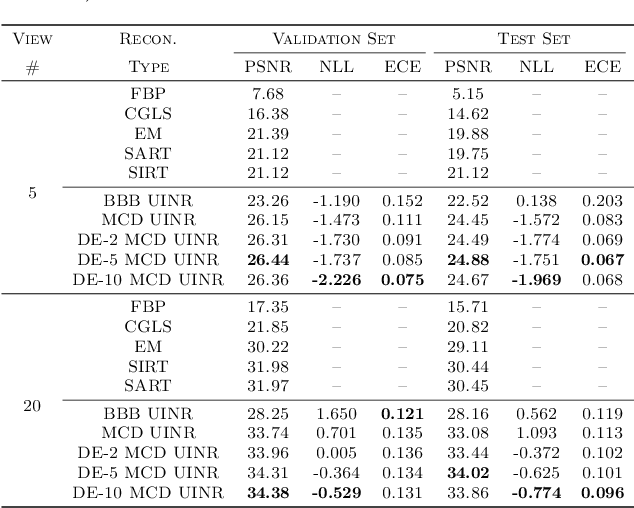
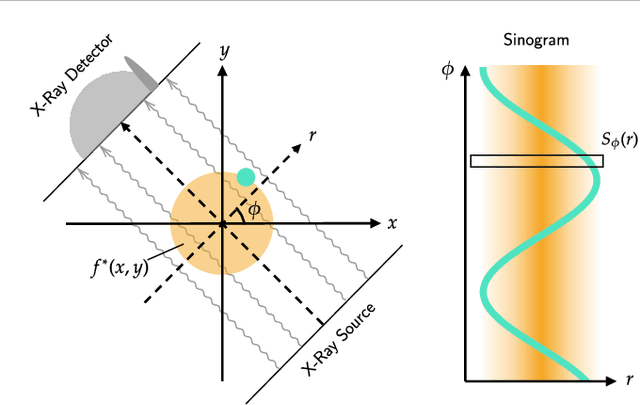
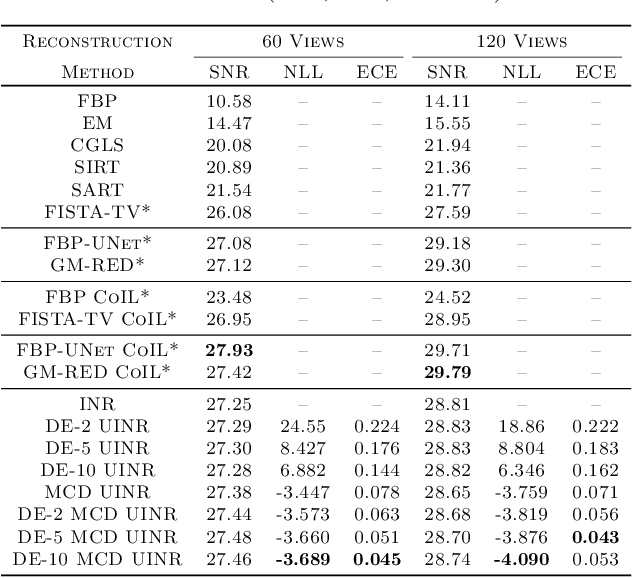
Implicit neural representations (INRs) have achieved impressive results for scene reconstruction and computer graphics, where their performance has primarily been assessed on reconstruction accuracy. However, in medical imaging, where the reconstruction problem is underdetermined and model predictions inform high-stakes diagnoses, uncertainty quantification of INR inference is critical. To that end, we study UncertaINR: a Bayesian reformulation of INR-based image reconstruction, for computed tomography (CT). We test several Bayesian deep learning implementations of UncertaINR and find that they achieve well-calibrated uncertainty, while retaining accuracy competitive with other classical, INR-based, and CNN-based reconstruction techniques. In contrast to the best-performing prior approaches, UncertaINR does not require a large training dataset, but only a handful of validation images.
Riemannian Score-Based Generative Modeling
Feb 06, 2022
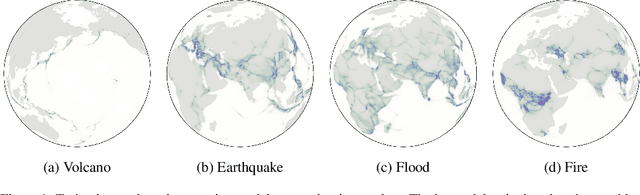

Score-based generative models (SGMs) are a novel class of generative models demonstrating remarkable empirical performance. One uses a diffusion to add progressively Gaussian noise to the data, while the generative model is a "denoising" process obtained by approximating the time-reversal of this "noising" diffusion. However, current SGMs make the underlying assumption that the data is supported on a Euclidean manifold with flat geometry. This prevents the use of these models for applications in robotics, geoscience or protein modeling which rely on distributions defined on Riemannian manifolds. To overcome this issue, we introduce Riemannian Score-based Generative Models (RSGMs) which extend current SGMs to the setting of compact Riemannian manifolds. We illustrate our approach with earth and climate science data and show how RSGMs can be accelerated by solving a Schr\"odinger bridge problem on manifolds.
COIN++: Data Agnostic Neural Compression
Jan 30, 2022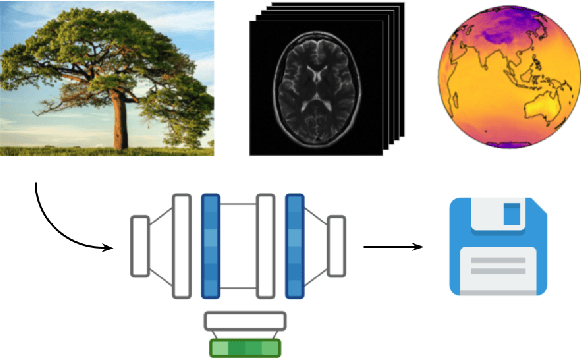
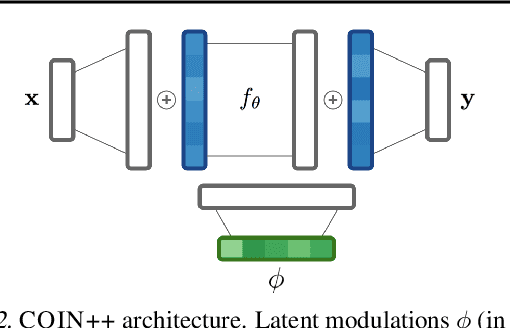
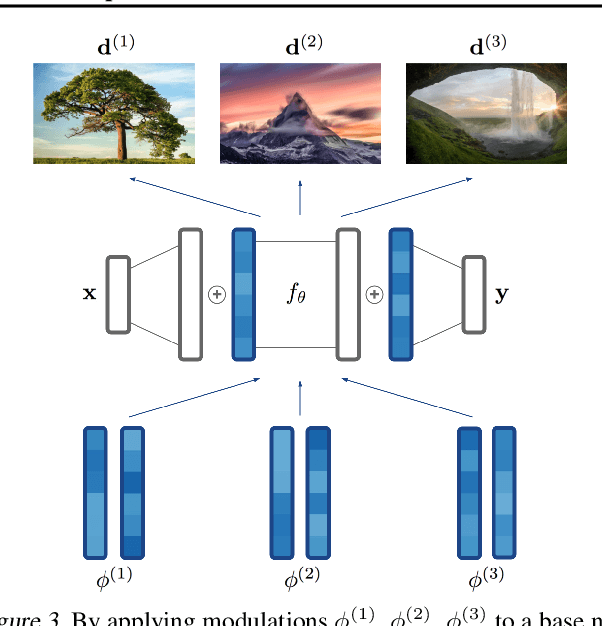
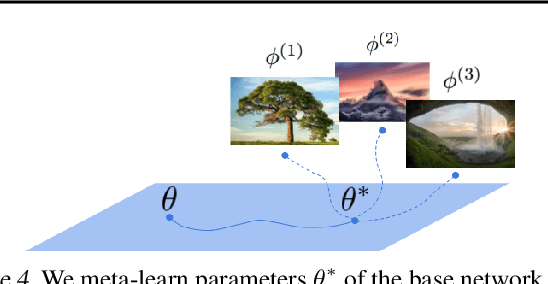
Neural compression algorithms are typically based on autoencoders that require specialized encoder and decoder architectures for different data modalities. In this paper, we propose COIN++, a neural compression framework that seamlessly handles a wide range of data modalities. Our approach is based on converting data to implicit neural representations, i.e. neural functions that map coordinates (such as pixel locations) to features (such as RGB values). Then, instead of storing the weights of the implicit neural representation directly, we store modulations applied to a meta-learned base network as a compressed code for the data. We further quantize and entropy code these modulations, leading to large compression gains while reducing encoding time by two orders of magnitude compared to baselines. We empirically demonstrate the effectiveness of our method by compressing various data modalities, from images to medical and climate data.
Vector-valued Gaussian Processes on Riemannian Manifolds via Gauge Independent Projected Kernels
Nov 25, 2021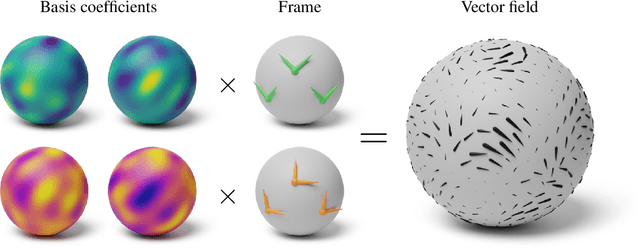


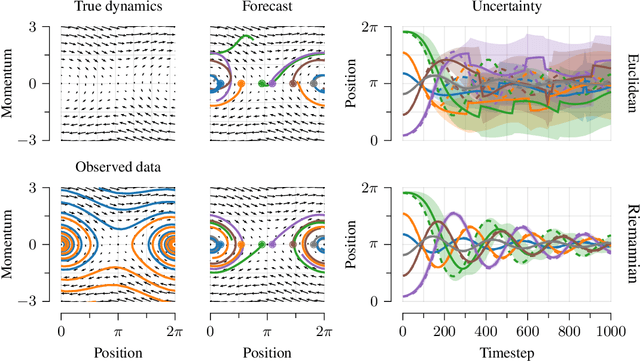
Gaussian processes are machine learning models capable of learning unknown functions in a way that represents uncertainty, thereby facilitating construction of optimal decision-making systems. Motivated by a desire to deploy Gaussian processes in novel areas of science, a rapidly-growing line of research has focused on constructively extending these models to handle non-Euclidean domains, including Riemannian manifolds, such as spheres and tori. We propose techniques that generalize this class to model vector fields on Riemannian manifolds, which are important in a number of application areas in the physical sciences. To do so, we present a general recipe for constructing gauge independent kernels, which induce Gaussian vector fields, i.e. vector-valued Gaussian processes coherent with geometry, from scalar-valued Riemannian kernels. We extend standard Gaussian process training methods, such as variational inference, to this setting. This enables vector-valued Gaussian processes on Riemannian manifolds to be trained using standard methods and makes them accessible to machine learning practitioners.
Powerpropagation: A sparsity inducing weight reparameterisation
Oct 06, 2021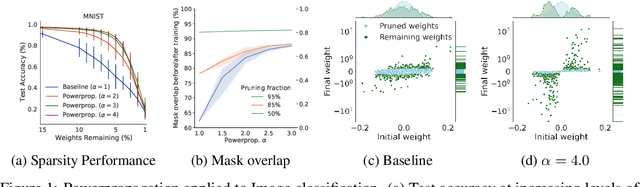
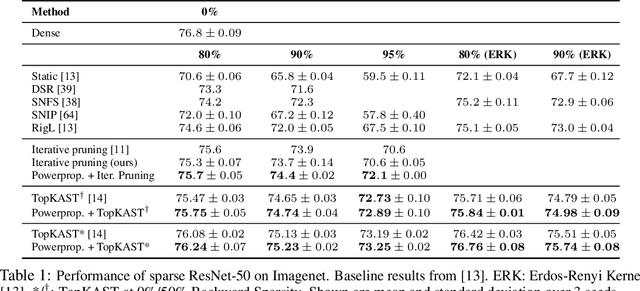
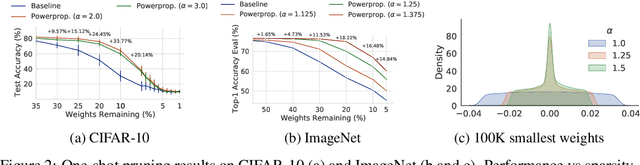
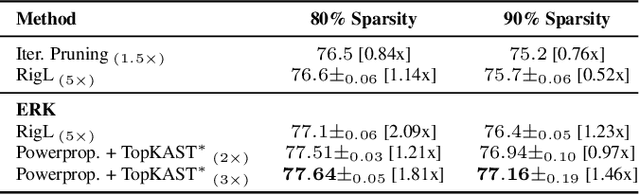
The training of sparse neural networks is becoming an increasingly important tool for reducing the computational footprint of models at training and evaluation, as well enabling the effective scaling up of models. Whereas much work over the years has been dedicated to specialised pruning techniques, little attention has been paid to the inherent effect of gradient based training on model sparsity. In this work, we introduce Powerpropagation, a new weight-parameterisation for neural networks that leads to inherently sparse models. Exploiting the behaviour of gradient descent, our method gives rise to weight updates exhibiting a "rich get richer" dynamic, leaving low-magnitude parameters largely unaffected by learning. Models trained in this manner exhibit similar performance, but have a distribution with markedly higher density at zero, allowing more parameters to be pruned safely. Powerpropagation is general, intuitive, cheap and straight-forward to implement and can readily be combined with various other techniques. To highlight its versatility, we explore it in two very different settings: Firstly, following a recent line of work, we investigate its effect on sparse training for resource-constrained settings. Here, we combine Powerpropagation with a traditional weight-pruning technique as well as recent state-of-the-art sparse-to-sparse algorithms, showing superior performance on the ImageNet benchmark. Secondly, we advocate the use of sparsity in overcoming catastrophic forgetting, where compressed representations allow accommodating a large number of tasks at fixed model capacity. In all cases our reparameterisation considerably increases the efficacy of the off-the-shelf methods.
InteL-VAEs: Adding Inductive Biases to Variational Auto-Encoders via Intermediary Latents
Jun 25, 2021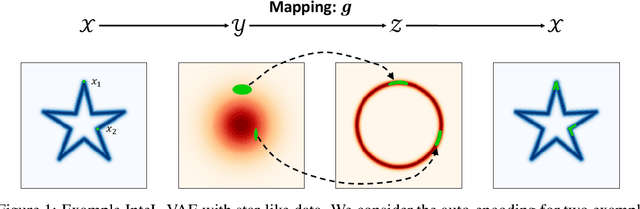


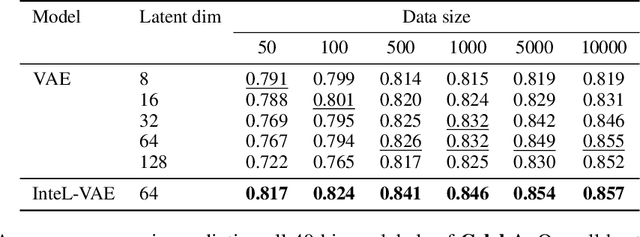
We introduce a simple and effective method for learning VAEs with controllable inductive biases by using an intermediary set of latent variables. This allows us to overcome the limitations of the standard Gaussian prior assumption. In particular, it allows us to impose desired properties like sparsity or clustering on learned representations, and incorporate prior information into the learned model. Our approach, which we refer to as the Intermediary Latent Space VAE (InteL-VAE), is based around controlling the stochasticity of the encoding process with the intermediary latent variables, before deterministically mapping them forward to our target latent representation, from which reconstruction is performed. This allows us to maintain all the advantages of the traditional VAE framework, while incorporating desired prior information, inductive biases, and even topological information through the latent mapping. We show that this, in turn, allows InteL-VAEs to learn both better generative models and representations.
On Contrastive Representations of Stochastic Processes
Jun 18, 2021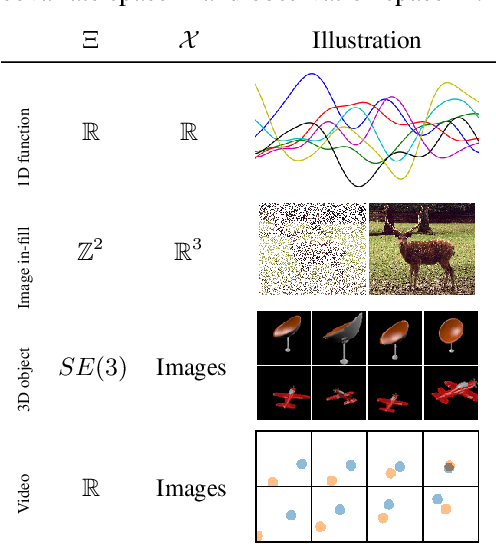


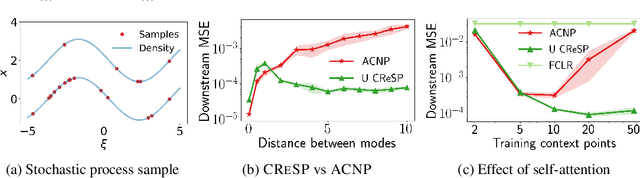
Learning representations of stochastic processes is an emerging problem in machine learning with applications from meta-learning to physical object models to time series. Typical methods rely on exact reconstruction of observations, but this approach breaks down as observations become high-dimensional or noise distributions become complex. To address this, we propose a unifying framework for learning contrastive representations of stochastic processes (CRESP) that does away with exact reconstruction. We dissect potential use cases for stochastic process representations, and propose methods that accommodate each. Empirically, we show that our methods are effective for learning representations of periodic functions, 3D objects and dynamical processes. Our methods tolerate noisy high-dimensional observations better than traditional approaches, and the learned representations transfer to a range of downstream tasks.