 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Stochastic Processes via Functional Markov Transition Operators
May 24, 2023



We introduce Markov Neural Processes (MNPs), a new class of Stochastic Processes (SPs) which are constructed by stacking sequences of neural parameterised Markov transition operators in function space. We prove that these Markov transition operators can preserve the exchangeability and consistency of SPs. Therefore, the proposed iterative construction adds substantial flexibility and expressivity to the original framework of Neural Processes (NPs) without compromising consistency or adding restrictions. Our experiments demonstrate clear advantages of MNPs over baseline models on a variety of tasks.
Incorporating Unlabelled Data into Bayesian Neural Networks
Apr 04, 2023We develop a contrastive framework for learning better prior distributions for Bayesian Neural Networks (BNNs) using unlabelled data. With this framework, we propose a practical BNN algorithm that offers the label-efficiency of self-supervised learning and the principled uncertainty estimates of Bayesian methods. Finally, we demonstrate the advantages of our approach for data-efficient learning in semi-supervised and low-budget active learning problems.
Deep Transformers without Shortcuts: Modifying Self-attention for Faithful Signal Propagation
Feb 20, 2023



Skip connections and normalisation layers form two standard architectural components that are ubiquitous for the training of Deep Neural Networks (DNNs), but whose precise roles are poorly understood. Recent approaches such as Deep Kernel Shaping have made progress towards reducing our reliance on them, using insights from wide NN kernel theory to improve signal propagation in vanilla DNNs (which we define as networks without skips or normalisation). However, these approaches are incompatible with the self-attention layers present in transformers, whose kernels are intrinsically more complicated to analyse and control. And so the question remains: is it possible to train deep vanilla transformers? We answer this question in the affirmative by designing several approaches that use combinations of parameter initialisations, bias matrices and location-dependent rescaling to achieve faithful signal propagation in vanilla transformers. Our methods address various intricacies specific to signal propagation in transformers, including the interaction with positional encoding and causal masking. In experiments on WikiText-103 and C4, our approaches enable deep transformers without normalisation to train at speeds matching their standard counterparts, and deep vanilla transformers to reach the same performance as standard ones after about 5 times more iterations.
Modality-Agnostic Variational Compression of Implicit Neural Representations
Jan 23, 2023



We introduce a modality-agnostic neural data compression algorithm based on a functional view of data and parameterised as an Implicit Neural Representation (INR). Bridging the gap between latent coding and sparsity, we obtain compact latent representations which are non-linearly mapped to a soft gating mechanism capable of specialising a shared INR base network to each data item through subnetwork selection. After obtaining a dataset of such compact latent representations, we directly optimise the rate/distortion trade-off in this modality-agnostic space using non-linear transform coding. We term this method Variational Compression of Implicit Neural Representation (VC-INR) and show both improved performance given the same representational capacity pre quantisation while also outperforming previous quantisation schemes used for other INR-based techniques. Our experiments demonstrate strong results over a large set of diverse data modalities using the same algorithm without any modality-specific inductive biases. We show results on images, climate data, 3D shapes and scenes as well as audio and video, introducing VC-INR as the first INR-based method to outperform codecs as well-known and diverse as JPEG 2000, MP3 and AVC/HEVC on their respective modalities.
On Pathologies in KL-Regularized Reinforcement Learning from Expert Demonstrations
Dec 28, 2022KL-regularized reinforcement learning from expert demonstrations has proved successful in improving the sample efficiency of deep reinforcement learning algorithms, allowing them to be applied to challenging physical real-world tasks. However, we show that KL-regularized reinforcement learning with behavioral reference policies derived from expert demonstrations can suffer from pathological training dynamics that can lead to slow, unstable, and suboptimal online learning. We show empirically that the pathology occurs for commonly chosen behavioral policy classes and demonstrate its impact on sample efficiency and online policy performance. Finally, we show that the pathology can be remedied by non-parametric behavioral reference policies and that this allows KL-regularized reinforcement learning to significantly outperform state-of-the-art approaches on a variety of challenging locomotion and dexterous hand manipulation tasks.
NEVIS'22: A Stream of 100 Tasks Sampled from 30 Years of Computer Vision Research
Nov 15, 2022We introduce the Never Ending VIsual-classification Stream (NEVIS'22), a benchmark consisting of a stream of over 100 visual classification tasks, sorted chronologically and extracted from papers sampled uniformly from computer vision proceedings spanning the last three decades. The resulting stream reflects what the research community thought was meaningful at any point in time. Despite being limited to classification, the resulting stream has a rich diversity of tasks from OCR, to texture analysis, crowd counting, scene recognition, and so forth. The diversity is also reflected in the wide range of dataset sizes, spanning over four orders of magnitude. Overall, NEVIS'22 poses an unprecedented challenge for current sequential learning approaches due to the scale and diversity of tasks, yet with a low entry barrier as it is limited to a single modality and each task is a classical supervised learning problem. Moreover, we provide a reference implementation including strong baselines and a simple evaluation protocol to compare methods in terms of their trade-off between accuracy and compute. We hope that NEVIS'22 can be useful to researchers working on continual learning, meta-learning, AutoML and more generally sequential learning, and help these communities join forces towards more robust and efficient models that efficiently adapt to a never ending stream of data. Implementations have been made available at https://github.com/deepmind/dm_nevis.
Riemannian Diffusion Schrödinger Bridge
Jul 07, 2022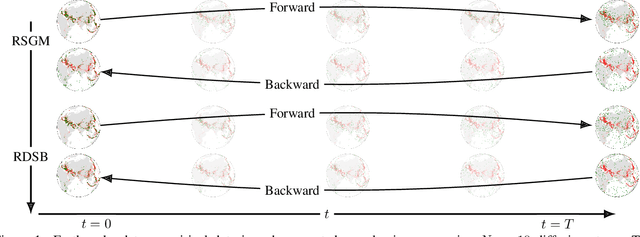
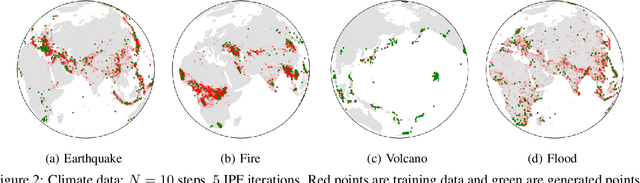

Score-based generative models exhibit state of the art performance on density estimation and generative modeling tasks. These models typically assume that the data geometry is flat, yet recent extensions have been developed to synthesize data living on Riemannian manifolds. Existing methods to accelerate sampling of diffusion models are typically not applicable in the Riemannian setting and Riemannian score-based methods have not yet been adapted to the important task of interpolation of datasets. To overcome these issues, we introduce \emph{Riemannian Diffusion Schr\"odinger Bridge}. Our proposed method generalizes Diffusion Schr\"odinger Bridge introduced in \cite{debortoli2021neurips} to the non-Euclidean setting and extends Riemannian score-based models beyond the first time reversal. We validate our proposed method on synthetic data and real Earth and climate data.
When Does Re-initialization Work?
Jun 20, 2022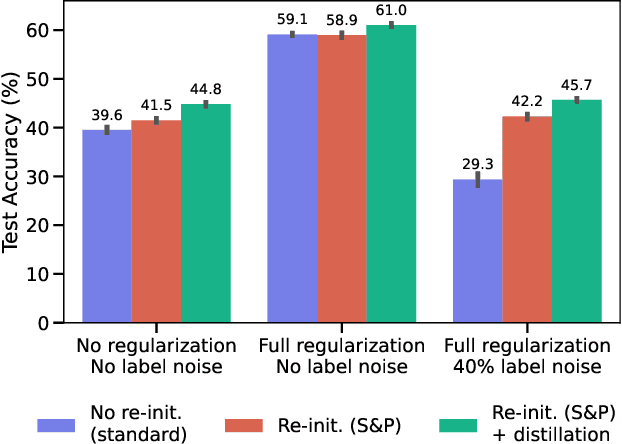
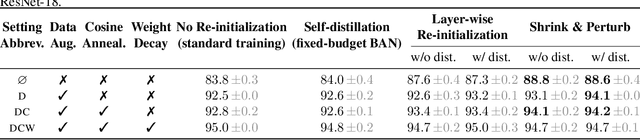
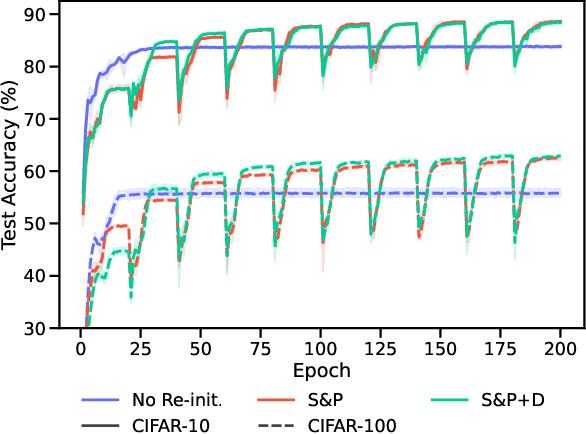

Re-initializing a neural network during training has been observed to improve generalization in recent works. Yet it is neither widely adopted in deep learning practice nor is it often used in state-of-the-art training protocols. This raises the question of when re-initialization works, and whether it should be used together with regularization techniques such as data augmentation, weight decay and learning rate schedules. In this work, we conduct an extensive empirical comparison of standard training with a selection of re-initialization methods to answer this question, training over 15,000 models on a variety of image classification benchmarks. We first establish that such methods are consistently beneficial for generalization in the absence of any other regularization. However, when deployed alongside other carefully tuned regularization techniques, re-initialization methods offer little to no added benefit for generalization, although optimal generalization performance becomes less sensitive to the choice of learning rate and weight decay hyperparameters. To investigate the impact of re-initialization methods on noisy data, we also consider learning under label noise. Surprisingly, in this case, re-initialization significantly improves upon standard training, even in the presence of other carefully tuned regularization techniques.
Challenges and Opportunities in Offline Reinforcement Learning from Visual Observations
Jun 09, 2022
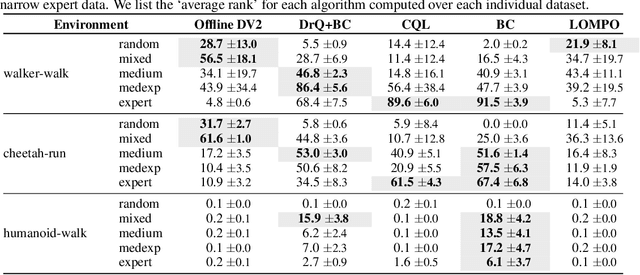
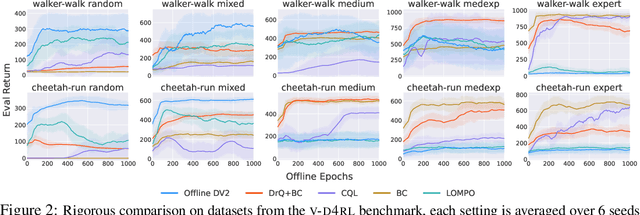

Offline reinforcement learning has shown great promise in leveraging large pre-collected datasets for policy learning, allowing agents to forgo often-expensive online data collection. However, to date, offline reinforcement learning from has been relatively under-explored, and there is a lack of understanding of where the remaining challenges lie. In this paper, we seek to establish simple baselines for continuous control in the visual domain. We show that simple modifications to two state-of-the-art vision-based online reinforcement learning algorithms, DreamerV2 and DrQ-v2, suffice to outperform prior work and establish a competitive baseline. We rigorously evaluate these algorithms on both existing offline datasets and a new testbed for offline reinforcement learning from visual observations that better represents the data distributions present in real-world offline reinforcement learning problems, and open-source our code and data to facilitate progress in this important domain. Finally, we present and analyze several key desiderata unique to offline RL from visual observations, including visual distractions and visually identifiable changes in dynamics.
Conformal Off-Policy Prediction in Contextual Bandits
Jun 09, 2022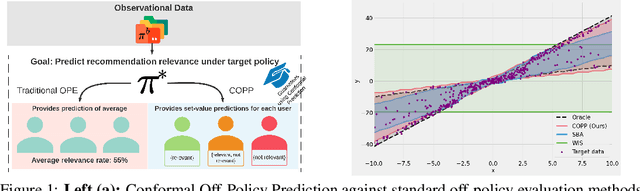

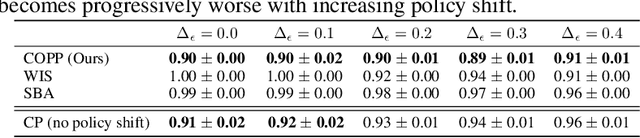
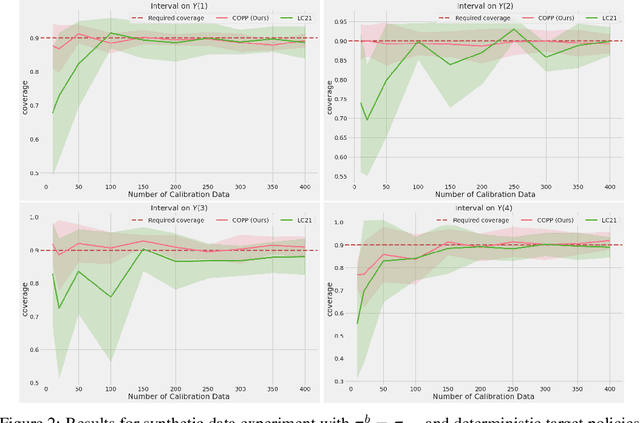
Most off-policy evaluation methods for contextual bandits have focused on the expected outcome of a policy, which is estimated via methods that at best provide only asymptotic guarantees. However, in many applications, the expectation may not be the best measure of performance as it does not capture the variability of the outcome. In addition, particularly in safety-critical settings, stronger guarantees than asymptotic correctness may be required. To address these limitations, we consider a novel application of conformal prediction to contextual bandits. Given data collected under a behavioral policy, we propose \emph{conformal off-policy prediction} (COPP), which can output reliable predictive intervals for the outcome under a new target policy. We provide theoretical finite-sample guarantees without making any additional assumptions beyond the standard contextual bandit setup, and empirically demonstrate the utility of COPP compared with existing methods on synthetic and real-world data.