 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-AI Co-reasoning for Clinical Diagnosis with Evidence-Integrated Language Agent
Mar 11, 2026We present PULSE, a medical reasoning agent that combines a domain-tuned large language model with scientific literature retrieval to support diagnostic decision-making in complex real-world cases. To evaluate its capabilities, we curated a benchmark of 82 authentic endocrinology case reports encompassing a broad spectrum of disease types and incidence levels. In controlled experiments, we compared PULSE's performance against physicians with varying levels of expertise-from residents to senior specialists-and examined how AI assistance influenced human diagnostic reasoning. PULSE attained expert-competitive accuracy, outperforming residents and junior specialists while matching senior specialist performance at both Top@1 and Top@4 thresholds. Unlike physicians, whose accuracy declined with disease rarity, PULSE maintained stable performance across incidence tiers. The agent also exhibited adaptive reasoning, increasing output length with case difficulty in a manner analogous to the longer deliberation observed among expert clinicians. When used collaboratively, PULSE enabled physicians to correct initial errors and broaden diagnostic hypotheses, but also introduced risks of automation bias. The study explores both serial and concurrent collaboration workflows, revealing that PULSE offers robust support across common and rare presentations. These findings underscore both the promise and the limitations of language model-based agents in clinical diagnosis, and offer a framework for evaluating their role in real-world decision-making.
Vision-Language Pre-Training for Multimodal Aspect-Based Sentiment Analysis
Apr 21, 2022
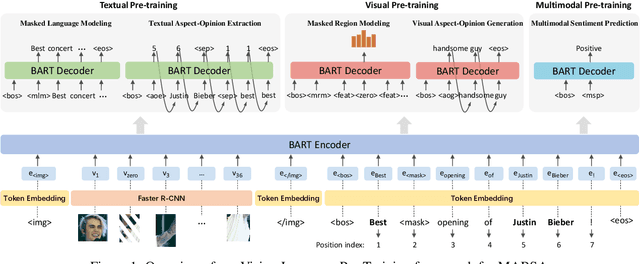
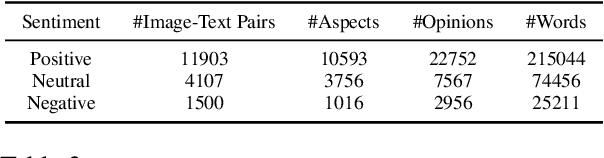
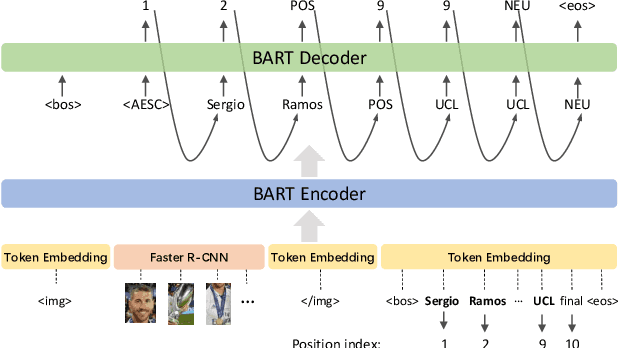
As an important task in sentiment analysis, Multimodal Aspect-Based Sentiment Analysis (MABSA) has attracted increasing attention in recent years. However, previous approaches either (i) use separately pre-trained visual and textual models, which ignore the crossmodal alignment or (ii) use vision-language models pre-trained with general pre-training tasks, which are inadequate to identify finegrained aspects, opinions, and their alignments across modalities. To tackle these limitations, we propose a task-specific Vision-Language Pre-training framework for MABSA (VLPMABSA), which is a unified multimodal encoder-decoder architecture for all the pretraining and downstream tasks. We further design three types of task-specific pre-training tasks from the language, vision, and multimodal modalities, respectively. Experimental results show that our approach generally outperforms the state-of-the-art approaches on three MABSA subtasks. Further analysis demonstrates the effectiveness of each pretraining task. The source code is publicly released at https://github.com/NUSTM/VLP-MABSA.