 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarment Avatars: Realistic Cloth Driving using Pattern Registration
Jun 07, 2022

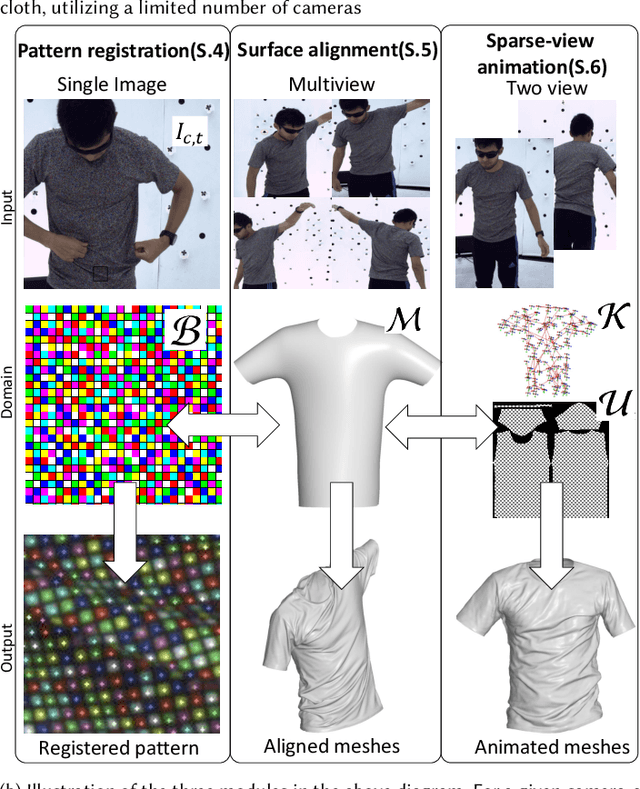

Virtual telepresence is the future of online communication. Clothing is an essential part of a person's identity and self-expression. Yet, ground truth data of registered clothes is currently unavailable in the required resolution and accuracy for training telepresence models for realistic cloth animation. Here, we propose an end-to-end pipeline for building drivable representations for clothing. The core of our approach is a multi-view patterned cloth tracking algorithm capable of capturing deformations with high accuracy. We further rely on the high-quality data produced by our tracking method to build a Garment Avatar: an expressive and fully-drivable geometry model for a piece of clothing. The resulting model can be animated using a sparse set of views and produces highly realistic reconstructions which are faithful to the driving signals. We demonstrate the efficacy of our pipeline on a realistic virtual telepresence application, where a garment is being reconstructed from two views, and a user can pick and swap garment design as they wish. In addition, we show a challenging scenario when driven exclusively with body pose, our drivable garment avatar is capable of producing realistic cloth geometry of significantly higher quality than the state-of-the-art.
Driving-Signal Aware Full-Body Avatars
May 21, 2021
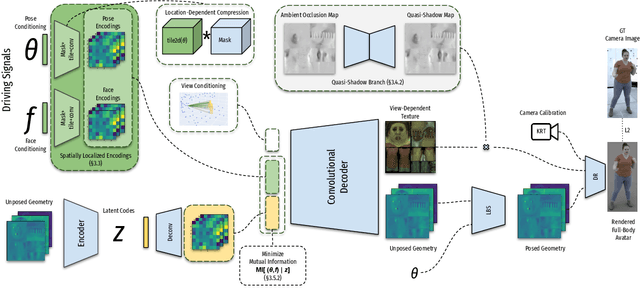
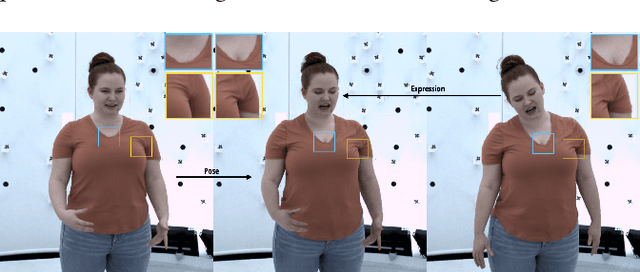
We present a learning-based method for building driving-signal aware full-body avatars. Our model is a conditional variational autoencoder that can be animated with incomplete driving signals, such as human pose and facial keypoints, and produces a high-quality representation of human geometry and view-dependent appearance. The core intuition behind our method is that better drivability and generalization can be achieved by disentangling the driving signals and remaining generative factors, which are not available during animation. To this end, we explicitly account for information deficiency in the driving signal by introducing a latent space that exclusively captures the remaining information, thus enabling the imputation of the missing factors required during full-body animation, while remaining faithful to the driving signal. We also propose a learnable localized compression for the driving signal which promotes better generalization, and helps minimize the influence of global chance-correlations often found in real datasets. For a given driving signal, the resulting variational model produces a compact space of uncertainty for missing factors that allows for an imputation strategy best suited to a particular application. We demonstrate the efficacy of our approach on the challenging problem of full-body animation for virtual telepresence with driving signals acquired from minimal sensors placed in the environment and mounted on a VR-headset.
MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentanglement
Apr 16, 2021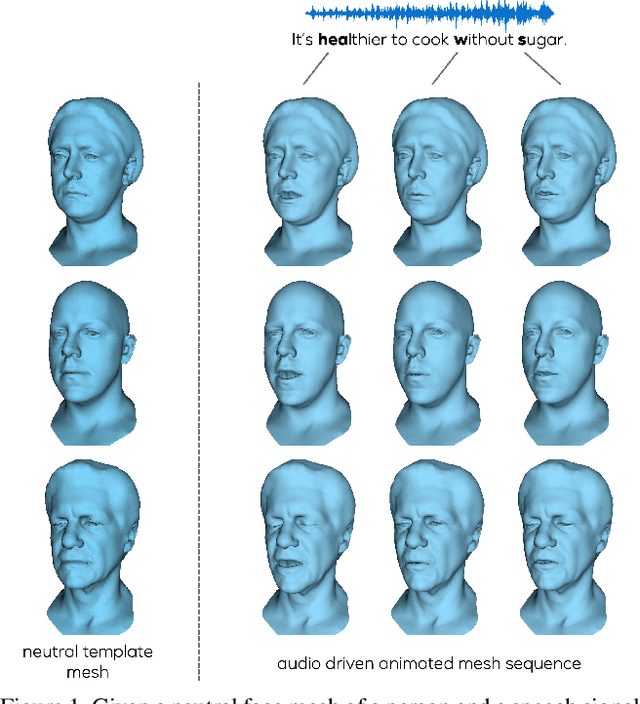

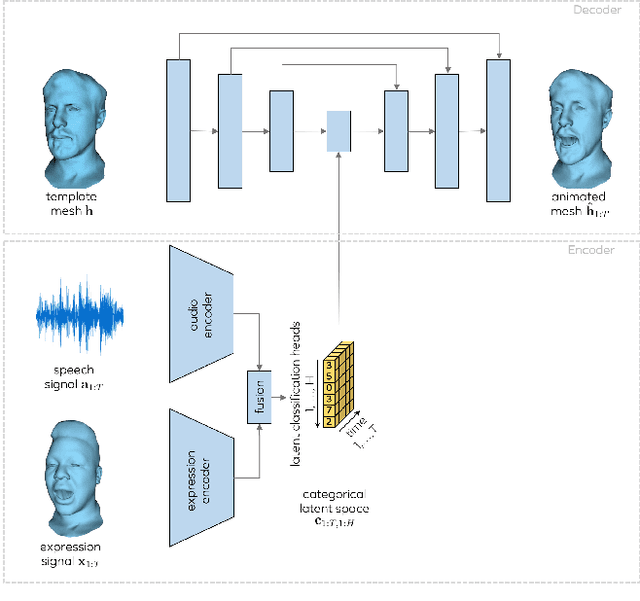

This paper presents a generic method for generating full facial 3D animation from speech. Existing approaches to audio-driven facial animation exhibit uncanny or static upper face animation, fail to produce accurate and plausible co-articulation or rely on person-specific models that limit their scalability. To improve upon existing models, we propose a generic audio-driven facial animation approach that achieves highly realistic motion synthesis results for the entire face. At the core of our approach is a categorical latent space for facial animation that disentangles audio-correlated and audio-uncorrelated information based on a novel cross-modality loss. Our approach ensures highly accurate lip motion, while also synthesizing plausible animation of the parts of the face that are uncorrelated to the audio signal, such as eye blinks and eye brow motion. We demonstrate that our approach outperforms several baselines and obtains state-of-the-art quality both qualitatively and quantitatively. A perceptual user study demonstrates that our approach is deemed more realistic than the current state-of-the-art in over 75% of cases. We recommend watching the supplemental video before reading the paper: https://research.fb.com/wp-content/uploads/2021/04/mesh_talk.mp4
Pixel Codec Avatars
Apr 09, 2021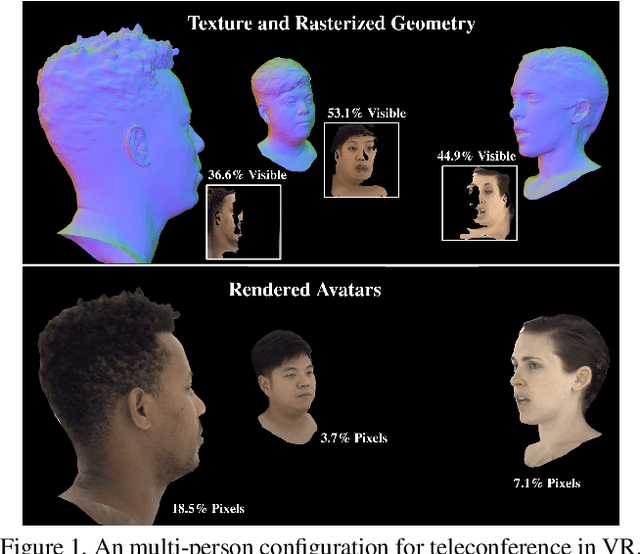
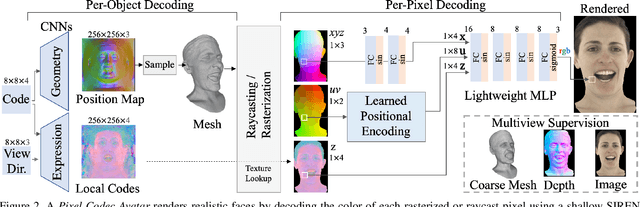
Telecommunication with photorealistic avatars in virtual or augmented reality is a promising path for achieving authentic face-to-face communication in 3D over remote physical distances. In this work, we present the Pixel Codec Avatars (PiCA): a deep generative model of 3D human faces that achieves state of the art reconstruction performance while being computationally efficient and adaptive to the rendering conditions during execution. Our model combines two core ideas: (1) a fully convolutional architecture for decoding spatially varying features, and (2) a rendering-adaptive per-pixel decoder. Both techniques are integrated via a dense surface representation that is learned in a weakly-supervised manner from low-topology mesh tracking over training images. We demonstrate that PiCA improves reconstruction over existing techniques across testing expressions and views on persons of different gender and skin tone. Importantly, we show that the PiCA model is much smaller than the state-of-art baseline model, and makes multi-person telecommunicaiton possible: on a single Oculus Quest 2 mobile VR headset, 5 avatars are rendered in realtime in the same scene.
High-fidelity Face Tracking for AR/VR via Deep Lighting Adaptation
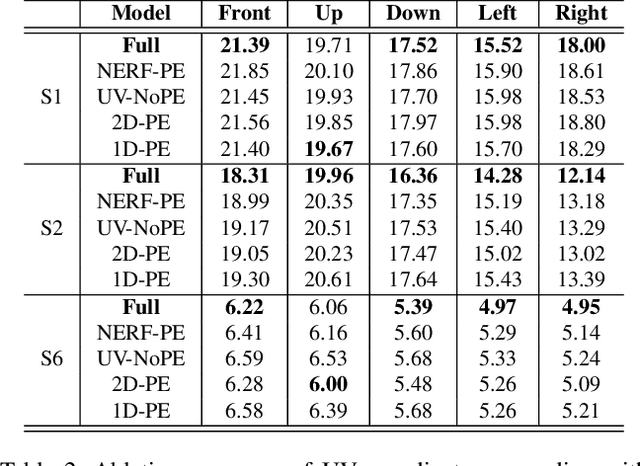
Mar 29, 2021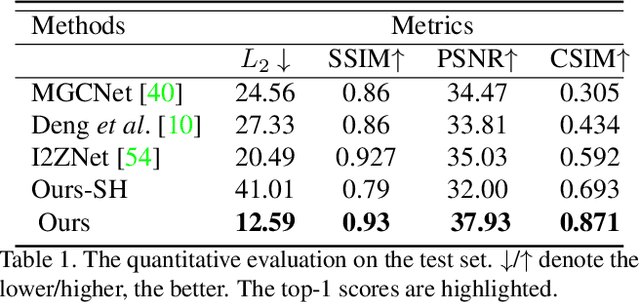
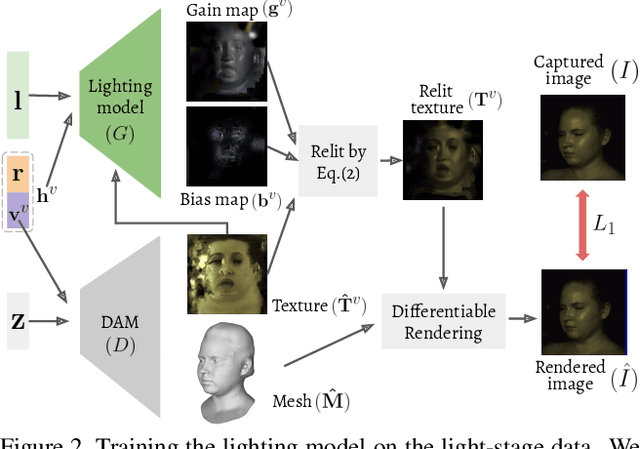

3D video avatars can empower virtual communications by providing compression, privacy, entertainment, and a sense of presence in AR/VR. Best 3D photo-realistic AR/VR avatars driven by video, that can minimize uncanny effects, rely on person-specific models. However, existing person-specific photo-realistic 3D models are not robust to lighting, hence their results typically miss subtle facial behaviors and cause artifacts in the avatar. This is a major drawback for the scalability of these models in communication systems (e.g., Messenger, Skype, FaceTime) and AR/VR. This paper addresses previous limitations by learning a deep learning lighting model, that in combination with a high-quality 3D face tracking algorithm, provides a method for subtle and robust facial motion transfer from a regular video to a 3D photo-realistic avatar. Extensive experimental validation and comparisons to other state-of-the-art methods demonstrate the effectiveness of the proposed framework in real-world scenarios with variability in pose, expression, and illumination. Please visit https://www.youtube.com/watch?v=dtz1LgZR8cc for more results. Our project page can be found at https://www.cs.rochester.edu/u/lchen63.
Mixture of Volumetric Primitives for Efficient Neural Rendering
Mar 02, 2021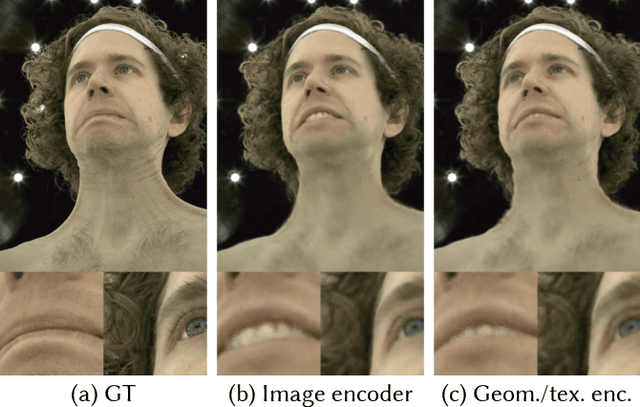
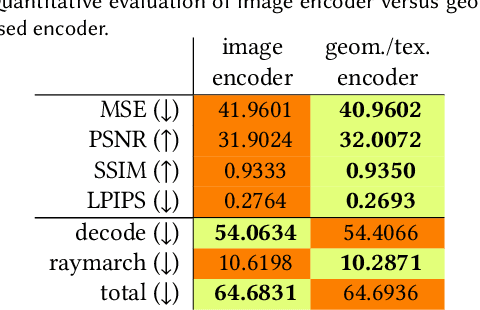
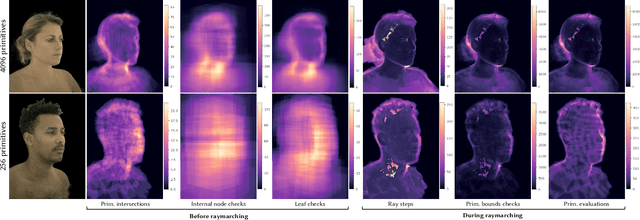
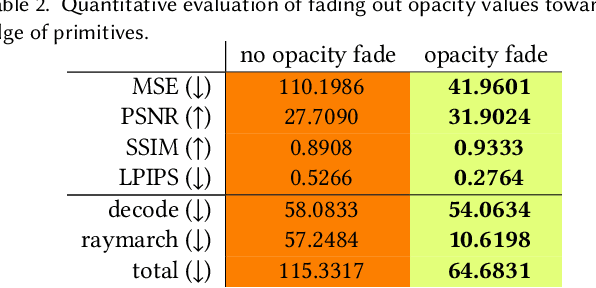
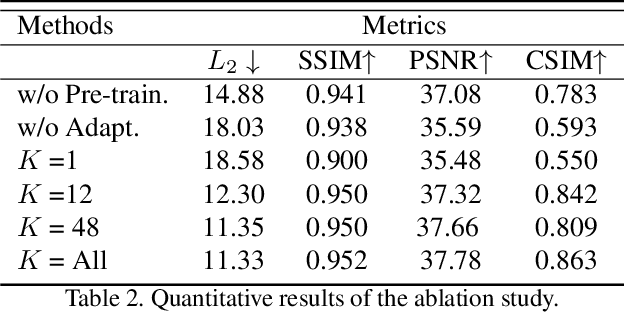
Real-time rendering and animation of humans is a core function in games, movies, and telepresence applications. Existing methods have a number of drawbacks we aim to address with our work. Triangle meshes have difficulty modeling thin structures like hair, volumetric representations like Neural Volumes are too low-resolution given a reasonable memory budget, and high-resolution implicit representations like Neural Radiance Fields are too slow for use in real-time applications. We present Mixture of Volumetric Primitives (MVP), a representation for rendering dynamic 3D content that combines the completeness of volumetric representations with the efficiency of primitive-based rendering, e.g., point-based or mesh-based methods. Our approach achieves this by leveraging spatially shared computation with a deconvolutional architecture and by minimizing computation in empty regions of space with volumetric primitives that can move to cover only occupied regions. Our parameterization supports the integration of correspondence and tracking constraints, while being robust to areas where classical tracking fails, such as around thin or translucent structures and areas with large topological variability. MVP is a hybrid that generalizes both volumetric and primitive-based representations. Through a series of extensive experiments we demonstrate that it inherits the strengths of each, while avoiding many of their limitations. We also compare our approach to several state-of-the-art methods and demonstrate that MVP produces superior results in terms of quality and runtime performance.
Supervision by Registration and Triangulation for Landmark Detection
Jan 25, 2021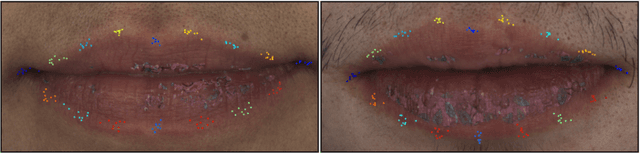


We present Supervision by Registration and Triangulation (SRT), an unsupervised approach that utilizes unlabeled multi-view video to improve the accuracy and precision of landmark detectors. Being able to utilize unlabeled data enables our detectors to learn from massive amounts of unlabeled data freely available and not be limited by the quality and quantity of manual human annotations. To utilize unlabeled data, there are two key observations: (1) the detections of the same landmark in adjacent frames should be coherent with registration, i.e., optical flow. (2) the detections of the same landmark in multiple synchronized and geometrically calibrated views should correspond to a single 3D point, i.e., multi-view consistency. Registration and multi-view consistency are sources of supervision that do not require manual labeling, thus it can be leveraged to augment existing training data during detector training. End-to-end training is made possible by differentiable registration and 3D triangulation modules. Experiments with 11 datasets and a newly proposed metric to measure precision demonstrate accuracy and precision improvements in landmark detection on both images and video. Code is available at https://github.com/D-X-Y/landmark-detection.
Expressive Telepresence via Modular Codec Avatars
Aug 26, 2020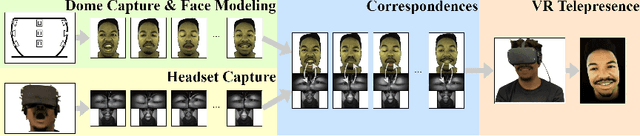
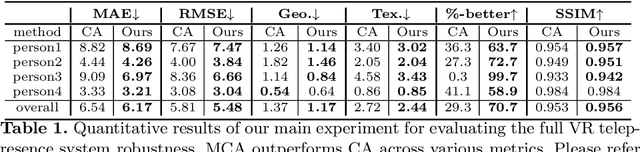
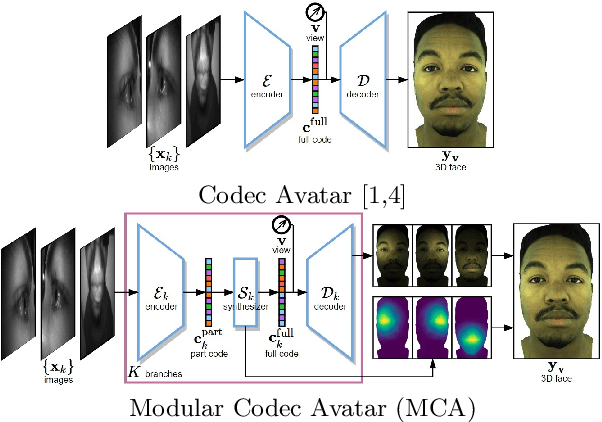
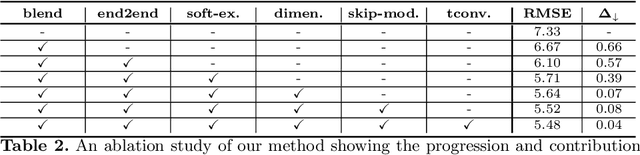
VR telepresence consists of interacting with another human in a virtual space represented by an avatar. Today most avatars are cartoon-like, but soon the technology will allow video-realistic ones. This paper aims in this direction and presents Modular Codec Avatars (MCA), a method to generate hyper-realistic faces driven by the cameras in the VR headset. MCA extends traditional Codec Avatars (CA) by replacing the holistic models with a learned modular representation. It is important to note that traditional person-specific CAs are learned from few training samples, and typically lack robustness as well as limited expressiveness when transferring facial expressions. MCAs solve these issues by learning a modulated adaptive blending of different facial components as well as an exemplar-based latent alignment. We demonstrate that MCA achieves improved expressiveness and robustness w.r.t to CA in a variety of real-world datasets and practical scenarios. Finally, we showcase new applications in VR telepresence enabled by the proposed model.
Audio- and Gaze-driven Facial Animation of Codec Avatars
Aug 11, 2020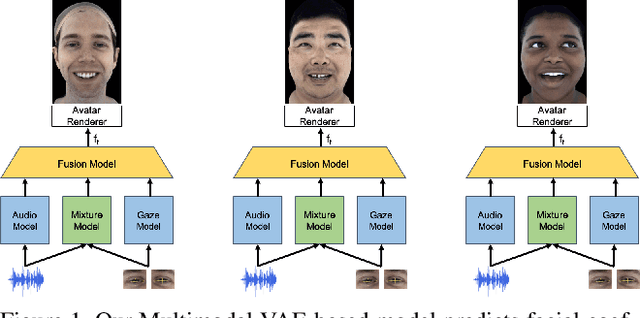
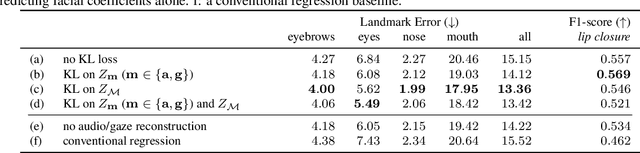
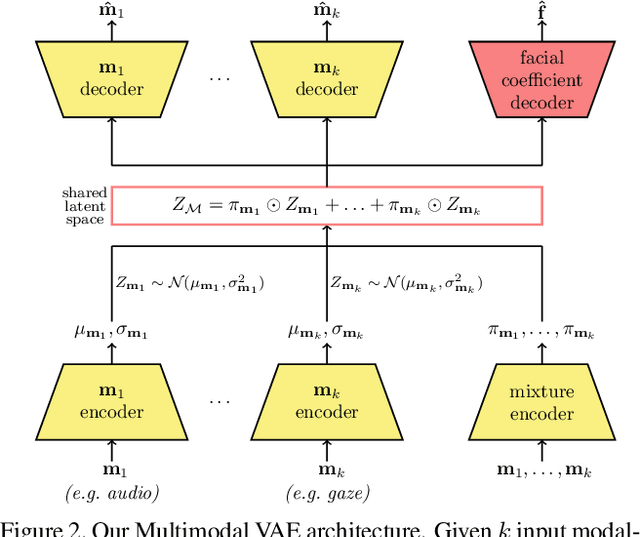
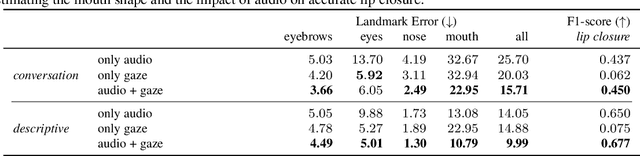
Codec Avatars are a recent class of learned, photorealistic face models that accurately represent the geometry and texture of a person in 3D (i.e., for virtual reality), and are almost indistinguishable from video. In this paper we describe the first approach to animate these parametric models in real-time which could be deployed on commodity virtual reality hardware using audio and/or eye tracking. Our goal is to display expressive conversations between individuals that exhibit important social signals such as laughter and excitement solely from latent cues in our lossy input signals. To this end we collected over 5 hours of high frame rate 3D face scans across three participants including traditional neutral speech as well as expressive and conversational speech. We investigate a multimodal fusion approach that dynamically identifies which sensor encoding should animate which parts of the face at any time. See the supplemental video which demonstrates our ability to generate full face motion far beyond the typically neutral lip articulations seen in competing work: https://research.fb.com/videos/audio-and-gaze-driven-facial-animation-of-codec-avatars/
Spatiotemporal Bundle Adjustment for Dynamic 3D Human Reconstruction in the Wild
Jul 24, 2020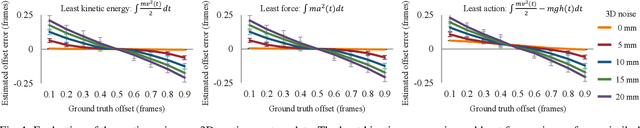

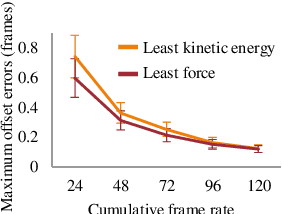
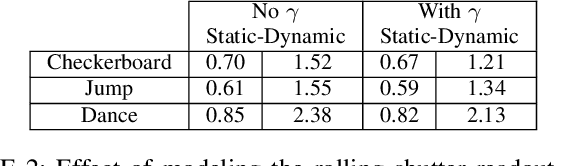
Bundle adjustment jointly optimizes camera intrinsics and extrinsics and 3D point triangulation to reconstruct a static scene. The triangulation constraint, however, is invalid for moving points captured in multiple unsynchronized videos and bundle adjustment is not designed to estimate the temporal alignment between cameras. We present a spatiotemporal bundle adjustment framework that jointly optimizes four coupled sub-problems: estimating camera intrinsics and extrinsics, triangulating static 3D points, as well as sub-frame temporal alignment between cameras and computing 3D trajectories of dynamic points. Key to our joint optimization is the careful integration of physics-based motion priors within the reconstruction pipeline, validated on a large motion capture corpus of human subjects. We devise an incremental reconstruction and alignment algorithm to strictly enforce the motion prior during the spatiotemporal bundle adjustment. This algorithm is further made more efficient by a divide and conquer scheme while still maintaining high accuracy. We apply this algorithm to reconstruct 3D motion trajectories of human bodies in dynamic events captured by multiple uncalibrated and unsynchronized video cameras in the wild. To make the reconstruction visually more interpretable, we fit a statistical 3D human body model to the asynchronous video streams.Compared to the baseline, the fitting significantly benefits from the proposed spatiotemporal bundle adjustment procedure. Because the videos are aligned with sub-frame precision, we reconstruct 3D motion at much higher temporal resolution than the input videos.