 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROMPTEVALS: A Dataset of Assertions and Guardrails for Custom Production Large Language Model Pipelines
Apr 20, 2025Large language models (LLMs) are increasingly deployed in specialized production data processing pipelines across diverse domains -- such as finance, marketing, and e-commerce. However, when running them in production across many inputs, they often fail to follow instructions or meet developer expectations. To improve reliability in these applications, creating assertions or guardrails for LLM outputs to run alongside the pipelines is essential. Yet, determining the right set of assertions that capture developer requirements for a task is challenging. In this paper, we introduce PROMPTEVALS, a dataset of 2087 LLM pipeline prompts with 12623 corresponding assertion criteria, sourced from developers using our open-source LLM pipeline tools. This dataset is 5x larger than previous collections. Using a hold-out test split of PROMPTEVALS as a benchmark, we evaluated closed- and open-source models in generating relevant assertions. Notably, our fine-tuned Mistral and Llama 3 models outperform GPT-4o by 20.93% on average, offering both reduced latency and improved performance. We believe our dataset can spur further research in LLM reliability, alignment, and prompt engineering.
Adversarial Attacks on Binary Image Recognition Systems
Oct 22, 2020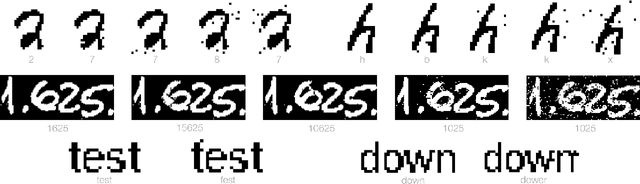
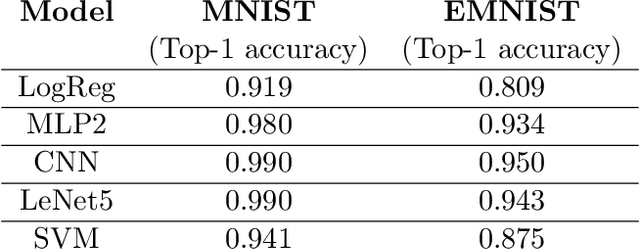
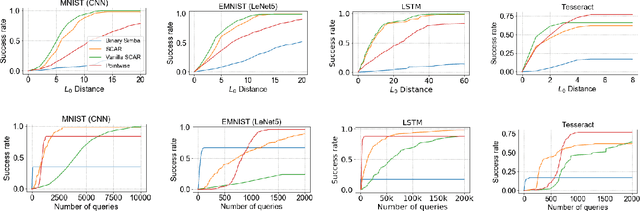

We initiate the study of adversarial attacks on models for binary (i.e. black and white) image classification. Although there has been a great deal of work on attacking models for colored and grayscale images, little is known about attacks on models for binary images. Models trained to classify binary images are used in text recognition applications such as check processing, license plate recognition, invoice processing, and many others. In contrast to colored and grayscale images, the search space of attacks on binary images is extremely restricted and noise cannot be hidden with minor perturbations in each pixel. Thus, the optimization landscape of attacks on binary images introduces new fundamental challenges. In this paper we introduce a new attack algorithm called SCAR, designed to fool classifiers of binary images. We show that SCAR significantly outperforms existing $L_0$ attacks applied to the binary setting and use it to demonstrate the vulnerability of real-world text recognition systems. SCAR's strong performance in practice contrasts with the existence of classifiers that are provably robust to large perturbations. In many cases, altering a single pixel is sufficient to trick Tesseract, a popular open-source text recognition system, to misclassify a word as a different word in the English dictionary. We also license software from providers of check processing systems to most of the major US banks and demonstrate the vulnerability of check recognitions for mobile deposits. These systems are substantially harder to fool since they classify both the handwritten amounts in digits and letters, independently. Nevertheless, we generalize SCAR to design attacks that fool state-of-the-art check processing systems using unnoticeable perturbations that lead to misclassification of deposit amounts. Consequently, this is a powerful method to perform financial fraud.