 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapsule Networks -- A Probabilistic Perspective
Apr 07, 2020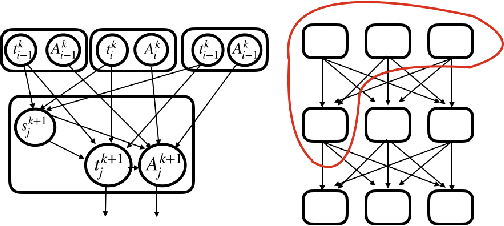
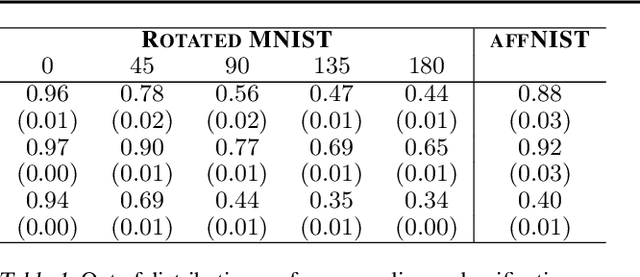
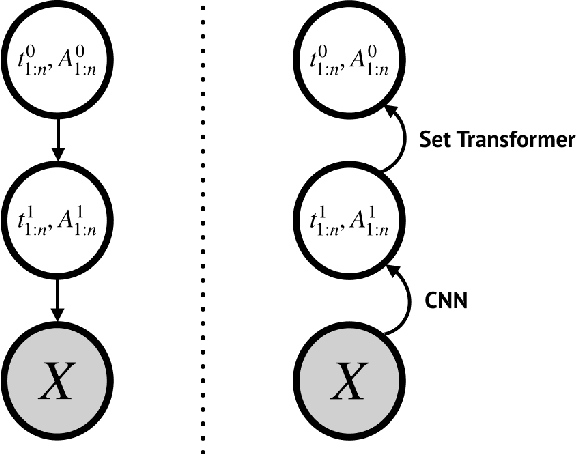
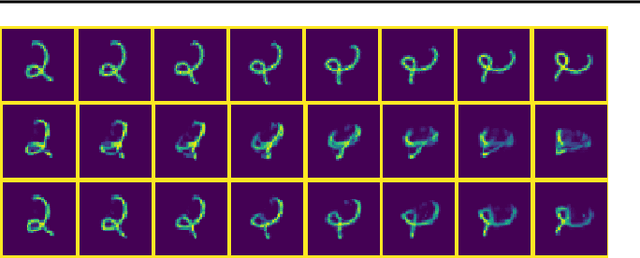
'Capsule' models try to explicitly represent the poses of objects, enforcing a linear relationship between an object's pose and that of its constituent parts. This modelling assumption should lead to robustness to viewpoint changes since the sub-object/super-object relationships are invariant to the poses of the object. We describe a probabilistic generative model which encodes such capsule assumptions, clearly separating the generative parts of the model from the inference mechanisms. With a variational bound we explore the properties of the generative model independently of the approximate inference scheme, and gain insights into failures of the capsule assumptions and inference amortisation. We experimentally demonstrate the applicability of our unified objective, and demonstrate the use of test time optimisation to solve problems inherent to amortised inference in our model.
Baryons from Mesons: A Machine Learning Perspective
Mar 23, 2020
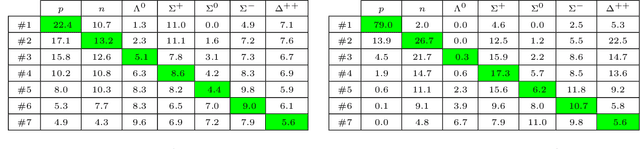
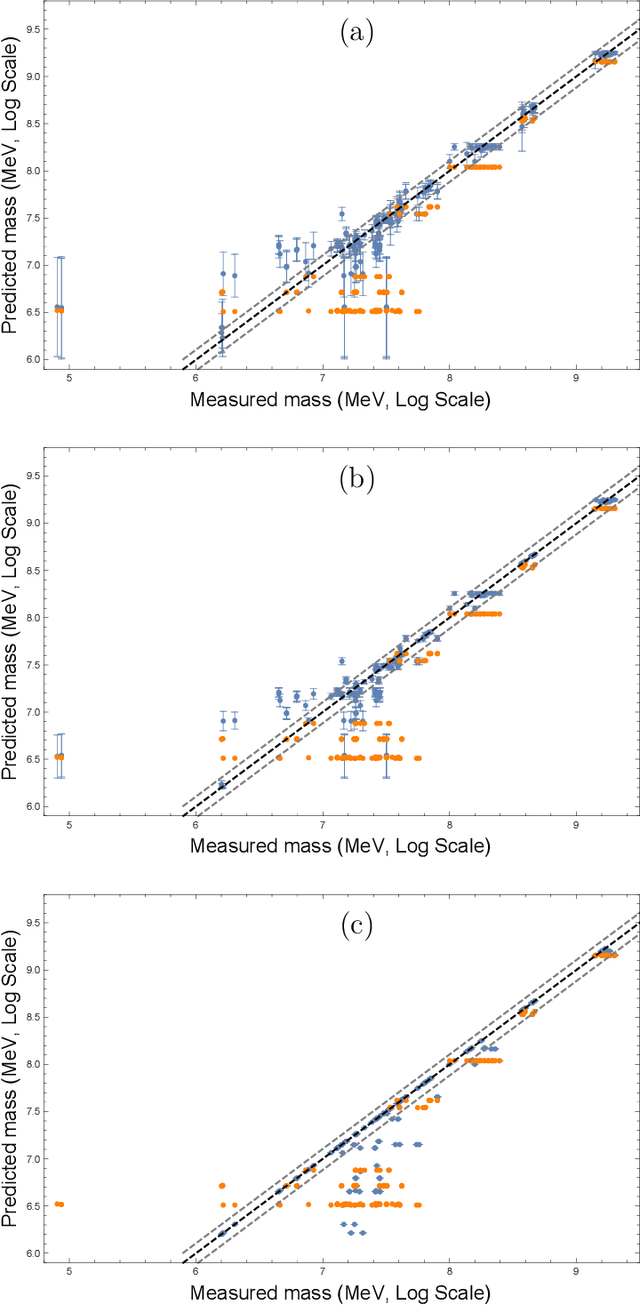

Quantum chromodynamics (QCD) is the theory of the strong interaction. The fundamental particles of QCD, quarks and gluons, carry colour charge and form colourless bound states at low energies. The hadronic bound states of primary interest to us are the mesons and the baryons. From knowledge of the meson spectrum, we use neural networks and Gaussian processes to predict the masses of baryons with 90.3% and 96.6% accuracy, respectively. These results compare favourably to the constituent quark model. We as well predict the masses of pentaquarks and other exotic hadrons.
Invariant Causal Prediction for Block MDPs
Mar 12, 2020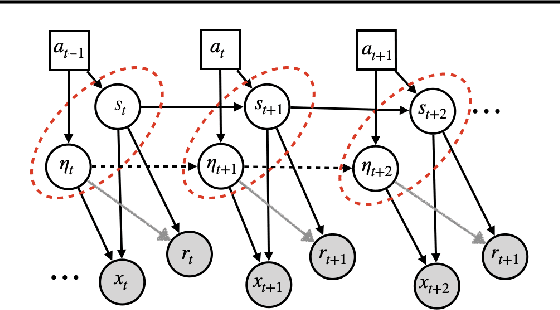
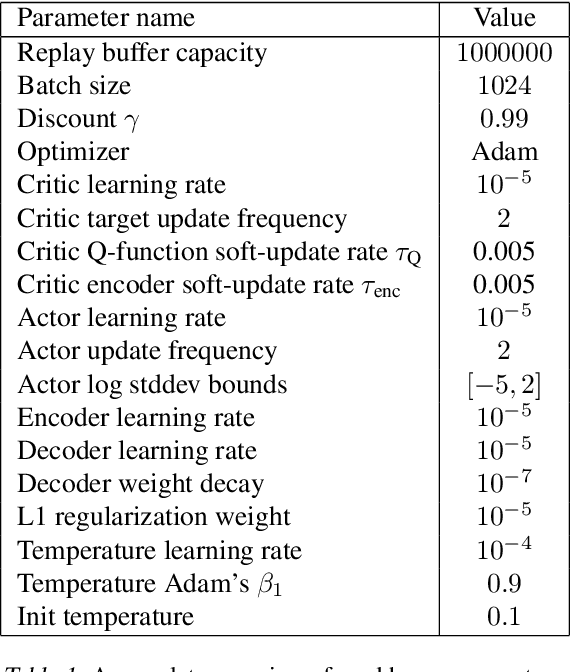
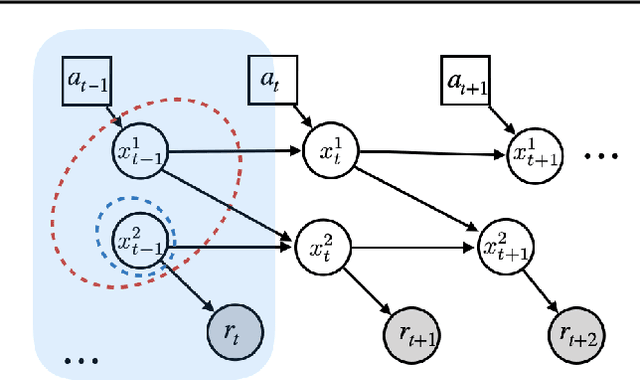
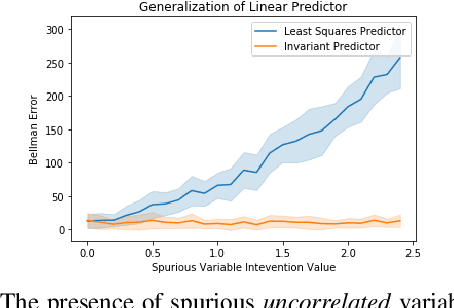
Generalization across environments is critical to the successful application of reinforcement learning algorithms to real-world challenges. In this paper, we consider the problem of learning abstractions that generalize in block MDPs, families of environments with a shared latent state space and dynamics structure over that latent space, but varying observations. We leverage tools from causal inference to propose a method of invariant prediction to learn model-irrelevance state abstractions (MISA) that generalize to novel observations in the multi-environment setting. We prove that for certain classes of environments, this approach outputs with high probability a state abstraction corresponding to the causal feature set with respect to the return. We further provide more general bounds on model error and generalization error in the multi-environment setting, in the process showing a connection between causal variable selection and the state abstraction framework for MDPs. We give empirical evidence that our methods work in both linear and nonlinear settings, attaining improved generalization over single- and multi-task baselines.
Simple and Scalable Epistemic Uncertainty Estimation Using a Single Deep Deterministic Neural Network
Mar 04, 2020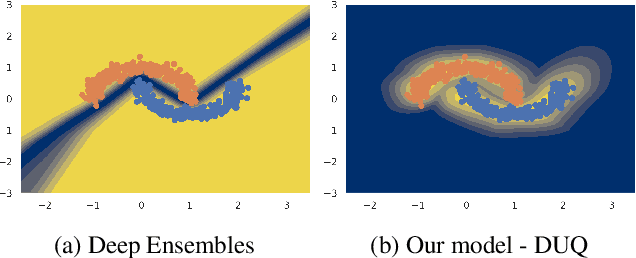

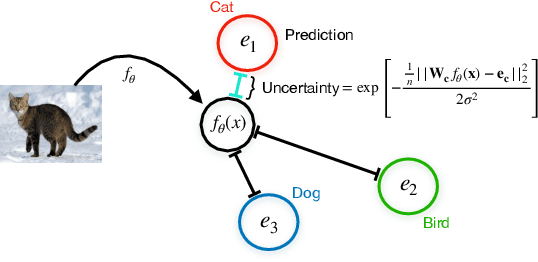

We propose a method for training a deterministic deep model that can find and reject out of distribution data points at test time with a single forward pass. Our approach, deterministic uncertainty quantification (DUQ), builds upon ideas of RBF networks. We scale training in these with a novel loss function and centroid updating scheme. By enforcing detectability of changes in the input using a gradient penalty, we are able to reliably detect out of distribution data. Our uncertainty quantification scales well to large datasets, and using a single model, we improve upon or match Deep Ensembles on notable difficult dataset pairs such as FashionMNIST vs. MNIST, and CIFAR-10 vs. SVHN, while maintaining competitive accuracy.
Try Depth Instead of Weight Correlations: Mean-field is a Less Restrictive Assumption for Deeper Networks
Feb 10, 2020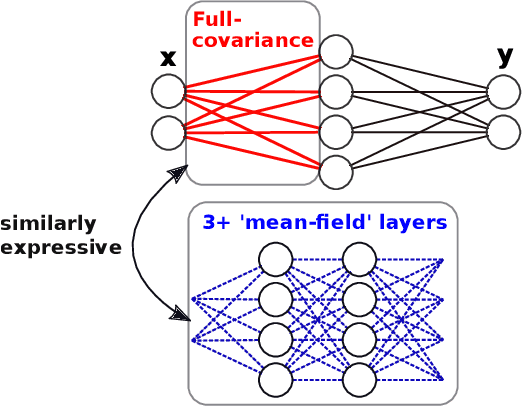
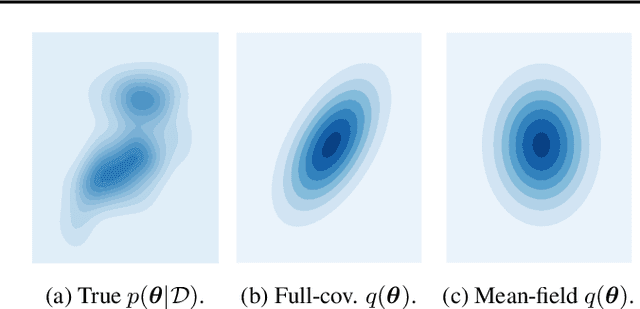
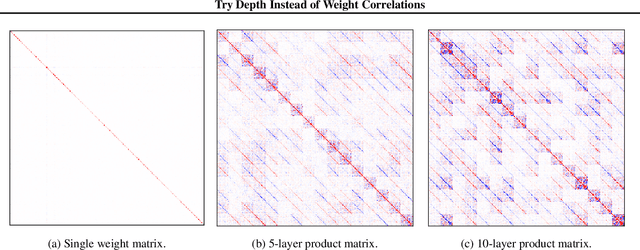
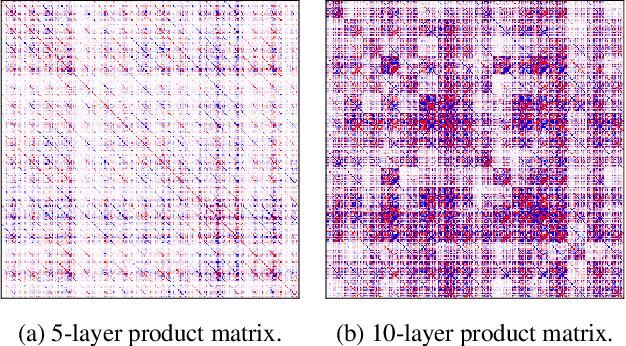
We challenge the longstanding assumption that the mean-field approximation for variational inference in Bayesian neural networks is severely restrictive. We argue mathematically that full-covariance approximations only improve the ELBO if they improve the expected log-likelihood. We further show that deeper mean-field networks are able to express predictive distributions approximately equivalent to shallower full-covariance networks. We validate these observations empirically, demonstrating that deeper models decrease the divergence between diagonal- and full-covariance Gaussian fits to the true posterior.
A Systematic Comparison of Bayesian Deep Learning Robustness in Diabetic Retinopathy Tasks
Dec 22, 2019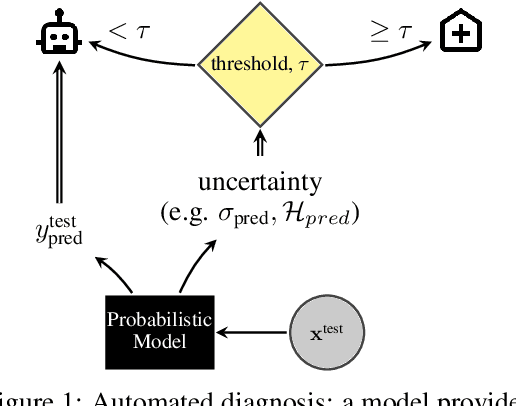
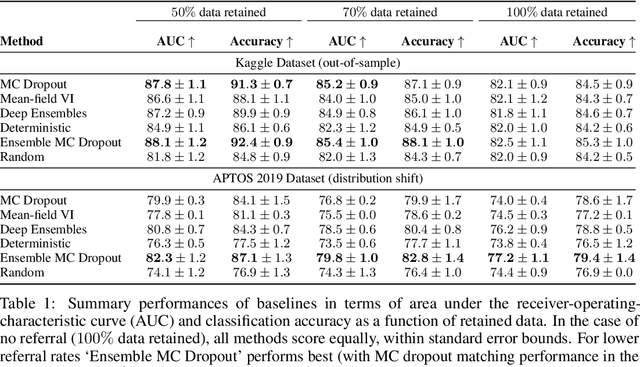
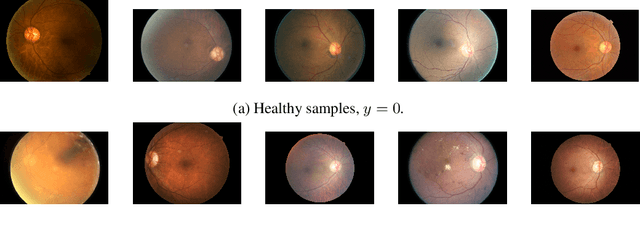
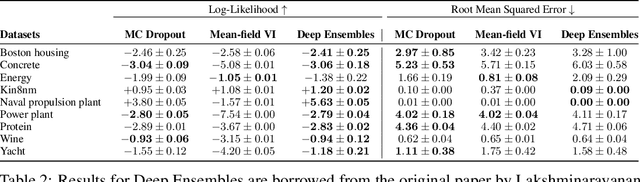
Evaluation of Bayesian deep learning (BDL) methods is challenging. We often seek to evaluate the methods' robustness and scalability, assessing whether new tools give `better' uncertainty estimates than old ones. These evaluations are paramount for practitioners when choosing BDL tools on-top of which they build their applications. Current popular evaluations of BDL methods, such as the UCI experiments, are lacking: Methods that excel with these experiments often fail when used in application such as medical or automotive, suggesting a pertinent need for new benchmarks in the field. We propose a new BDL benchmark with a diverse set of tasks, inspired by a real-world medical imaging application on \emph{diabetic retinopathy diagnosis}. Visual inputs (512x512 RGB images of retinas) are considered, where model uncertainty is used for medical pre-screening---i.e. to refer patients to an expert when model diagnosis is uncertain. Methods are then ranked according to metrics derived from expert-domain to reflect real-world use of model uncertainty in automated diagnosis. We develop multiple tasks that fall under this application, including out-of-distribution detection and robustness to distribution shift. We then perform a systematic comparison of well-tuned BDL techniques on the various tasks. From our comparison we conclude that some current techniques which solve benchmarks such as UCI `overfit' their uncertainty to the dataset---when evaluated on our benchmark these underperform in comparison to simpler baselines. The code for the benchmark, its baselines, and a simple API for evaluating new BDL tools are made available at https://github.com/oatml/bdl-benchmarks.
Adversarial recovery of agent rewards from latent spaces of the limit order book
Dec 09, 2019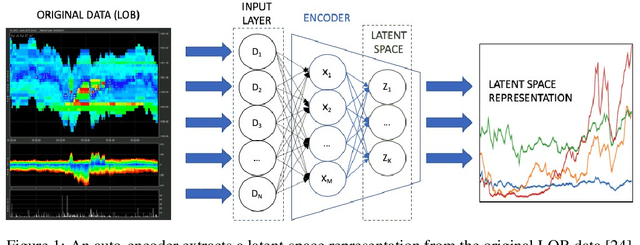
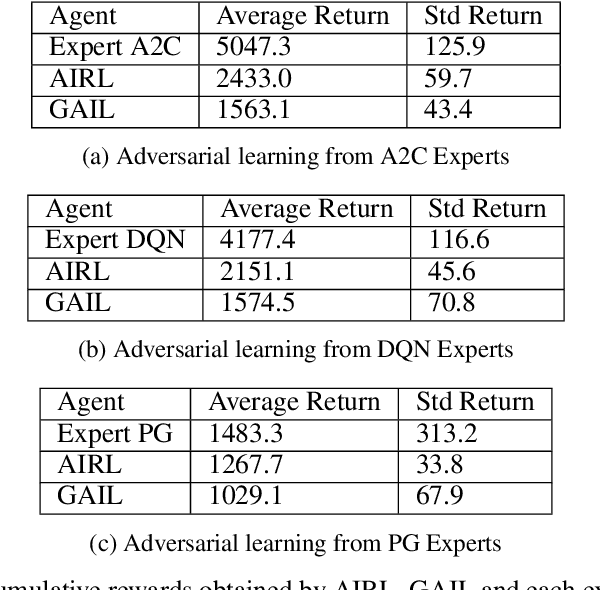
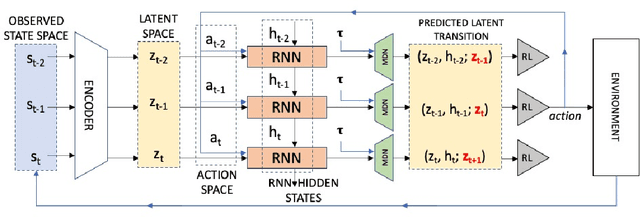
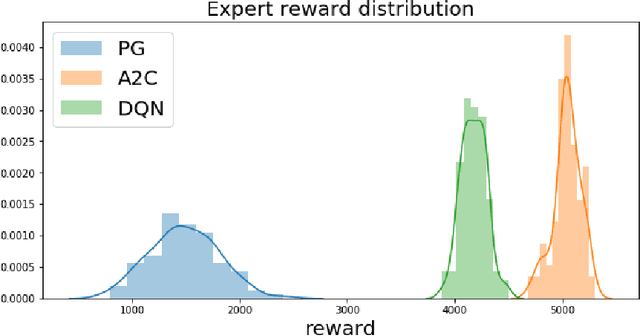
Inverse reinforcement learning has proved its ability to explain state-action trajectories of expert agents by recovering their underlying reward functions in increasingly challenging environments. Recent advances in adversarial learning have allowed extending inverse RL to applications with non-stationary environment dynamics unknown to the agents, arbitrary structures of reward functions and improved handling of the ambiguities inherent to the ill-posed nature of inverse RL. This is particularly relevant in real time applications on stochastic environments involving risk, like volatile financial markets. Moreover, recent work on simulation of complex environments enable learning algorithms to engage with real market data through simulations of its latent space representations, avoiding a costly exploration of the original environment. In this paper, we explore whether adversarial inverse RL algorithms can be adapted and trained within such latent space simulations from real market data, while maintaining their ability to recover agent rewards robust to variations in the underlying dynamics, and transfer them to new regimes of the original environment.
Auto-Calibration of Remote Sensing Solar Telescopes with Deep Learning
Nov 10, 2019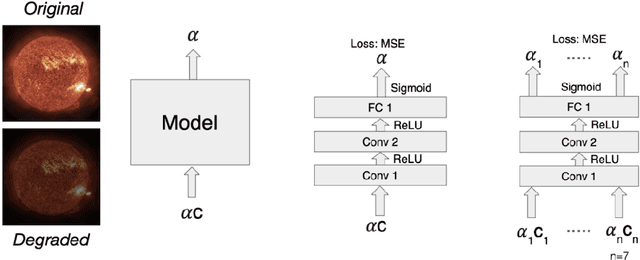
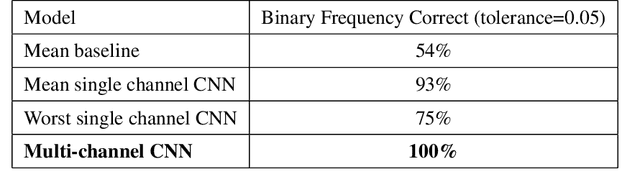

As a part of NASA's Heliophysics System Observatory (HSO) fleet of satellites,the Solar Dynamics Observatory (SDO) has continuously monitored the Sun since2010. Ultraviolet (UV) and Extreme UV (EUV) instruments in orbit, such asSDO's Atmospheric Imaging Assembly (AIA) instrument, suffer time-dependent degradation which reduces instrument sensitivity. Accurate calibration for (E)UV instruments currently depends on periodic sounding rockets, which are infrequent and not practical for heliophysics missions in deep space. In the present work, we develop a Convolutional Neural Network (CNN) that auto-calibrates SDO/AIA channels and corrects sensitivity degradation by exploiting spatial patterns in multi-wavelength observations to arrive at a self-calibration of (E)UV imaging instruments. Our results remove a major impediment to developing future HSOmissions of the same scientific caliber as SDO but in deep space, able to observe the Sun from more vantage points than just SDO's current geosynchronous orbit.This approach can be adopted to perform autocalibration of other imaging systems exhibiting similar forms of degradation
Using U-Nets to Create High-Fidelity Virtual Observations of the Solar Corona
Nov 10, 2019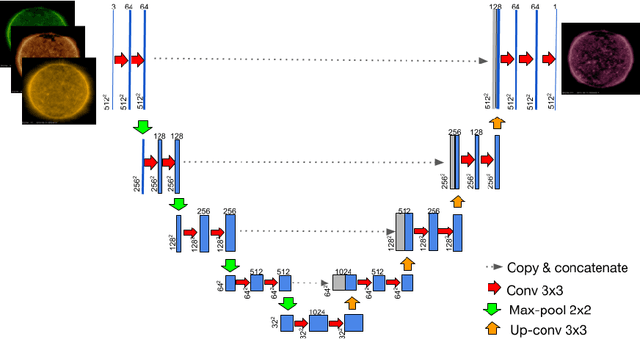

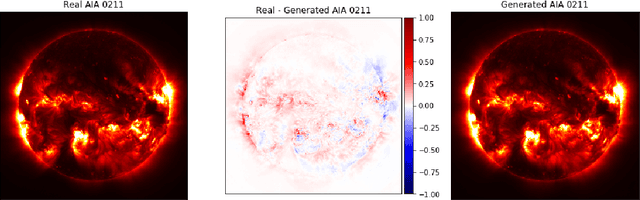
Understanding and monitoring the complex and dynamic processes of the Sun is important for a number of human activities on Earth and in space. For this reason, NASA's Solar Dynamics Observatory (SDO) has been continuously monitoring the multi-layered Sun's atmosphere in high-resolution since its launch in 2010, generating terabytes of observational data every day. The synergy between machine learning and this enormous amount of data has the potential, still largely unexploited, to advance our understanding of the Sun and extend the capabilities of heliophysics missions. In the present work, we show that deep learning applied to SDO data can be successfully used to create a high-fidelity virtual telescope that generates synthetic observations of the solar corona by image translation. Towards this end we developed a deep neural network, structured as an encoder-decoder with skip connections (U-Net), that reconstructs the Sun's image of one instrument channel given temporally aligned images in three other channels. The approach we present has the potential to reduce the telemetry needs of SDO, enhance the capabilities of missions that have less observing channels, and transform the concept development of future missions.
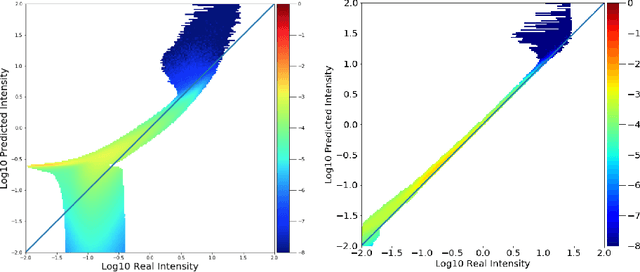
Single-Frame Super-Resolution of Solar Magnetograms: Investigating Physics-Based Metrics \& Losses
Nov 04, 2019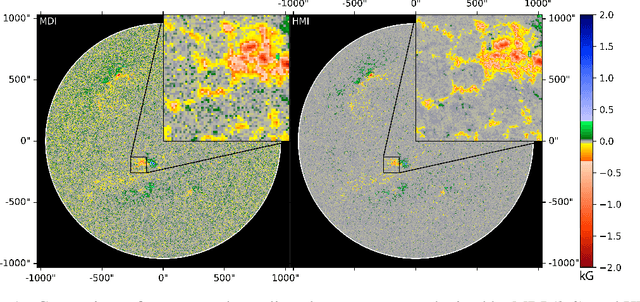
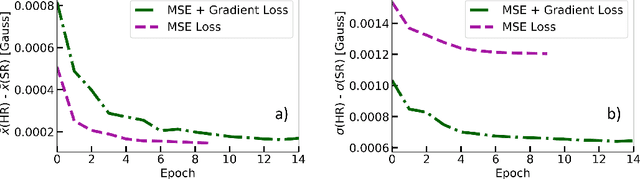
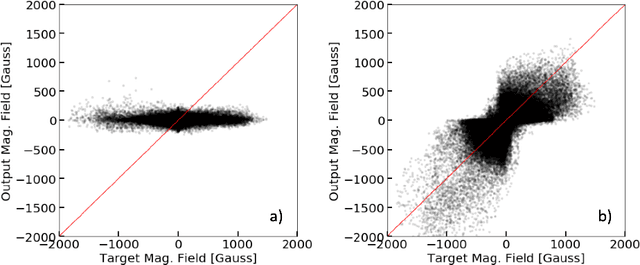
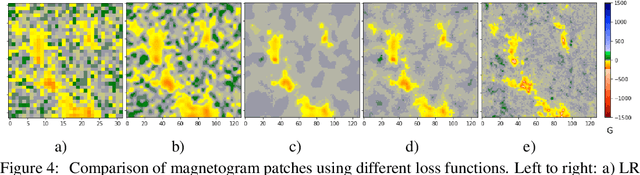
Breakthroughs in our understanding of physical phenomena have traditionally followed improvements in instrumentation. Studies of the magnetic field of the Sun, and its influence on the solar dynamo and space weather events, have benefited from improvements in resolution and measurement frequency of new instruments. However, in order to fully understand the solar cycle, high-quality data across time-scales longer than the typical lifespan of a solar instrument are required. At the moment, discrepancies between measurement surveys prevent the combined use of all available data. In this work, we show that machine learning can help bridge the gap between measurement surveys by learning to \textbf{super-resolve} low-resolution magnetic field images and \textbf{translate} between characteristics of contemporary instruments in orbit. We also introduce the notion of physics-based metrics and losses for super-resolution to preserve underlying physics and constrain the solution space of possible super-resolution outputs.