 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopological Effects in Neural Network Field Theory
Apr 02, 2026Neural network field theory formulates field theory as a statistical ensemble of fields defined by a network architecture and a density on its parameters. We extend the construction to topological settings via the inclusion of discrete parameters that label the topological quantum number. We recover the Berezinskii--Kosterlitz--Thouless transition, including the spin-wave critical line and the proliferation of vortices at high temperatures. We also verify the T-duality of the bosonic string, showing invariance under the exchange of momentum and winding on $S^1$, the transformation of the sigma model couplings according to the Buscher rules on constant toroidal backgrounds, the enhancement of the current algebra at self-dual radius, and non-geometric T-fold transition functions.
Machine learning modularity
Jan 05, 2026Based on a transformer based sequence-to-sequence architecture combined with a dynamic batching algorithm, this work introduces a machine learning framework for automatically simplifying complex expressions involving multiple elliptic Gamma functions, including the $q$-$θ$ function and the elliptic Gamma function. The model learns to apply algebraic identities, particularly the SL$(2,\mathbb{Z})$ and SL$(3,\mathbb{Z})$ modular transformations, to reduce heavily scrambled expressions to their canonical forms. Experimental results show that the model achieves over 99\% accuracy on in-distribution tests and maintains robust performance (exceeding 90\% accuracy) under significant extrapolation, such as with deeper scrambling depths. This demonstrates that the model has internalized the underlying algebraic rules of modular transformations rather than merely memorizing training patterns. Our work presents the first successful application of machine learning to perform symbolic simplification using modular identities, offering a new automated tool for computations with special functions in quantum field theory and the string theory.
Machine learning automorphic forms for black holes
May 08, 2025Modular, Jacobi, and mock-modular forms serve as generating functions for BPS black hole degeneracies. By training feed-forward neural networks on Fourier coefficients of automorphic forms derived from the Dedekind eta function, Eisenstein series, and Jacobi theta functions, we demonstrate that machine learning techniques can accurately predict modular weights from truncated expansions. Our results reveal strong performance for negative weight modular and quasi-modular forms, particularly those arising in exact black hole counting formulae, with lower accuracy for positive weights and more complicated combinations of Jacobi theta functions. This study establishes a proof of concept for using machine learning to identify how data is organized in terms of modular symmetries in gravitational systems and suggests a pathway toward automated detection and verification of symmetries in quantum gravity.
Colored Jones Polynomials and the Volume Conjecture
Feb 25, 2025



Using the vertex model approach for braid representations, we compute polynomials for spin-1 placed on hyperbolic knots up to 15 crossings. These polynomials are referred to as 3-colored Jones polynomials or adjoint Jones polynomials. Training a subset of the data using a fully connected feedforward neural network, we predict the volume of the knot complement of hyperbolic knots from the adjoint Jones polynomial or its evaluations with 99.34% accuracy. A function of the adjoint Jones polynomial evaluated at the phase $q=e^{ 8 \pi i / 15 }$ predicts the volume with nearly the same accuracy as the neural network. From an analysis of 2-colored and 3-colored Jones polynomials, we conjecture the best phase for $n$-colored Jones polynomials, and use this hypothesis to motivate an improved statement of the volume conjecture. This is tested for knots for which closed form expressions for the $n$-colored Jones polynomial are known, and we show improved convergence to the volume.
cymyc -- Calabi-Yau Metrics, Yukawas, and Curvature
Oct 25, 2024We introduce \texttt{cymyc}, a high-performance Python library for numerical investigation of the geometry of a large class of string compactification manifolds and their associated moduli spaces. We develop a well-defined geometric ansatz to numerically model tensor fields of arbitrary degree on a large class of Calabi-Yau manifolds. \texttt{cymyc} includes a machine learning component which incorporates this ansatz to model tensor fields of interest on these spaces by finding an approximate solution to the system of partial differential equations they should satisfy.
Learning to be Simple
Dec 08, 2023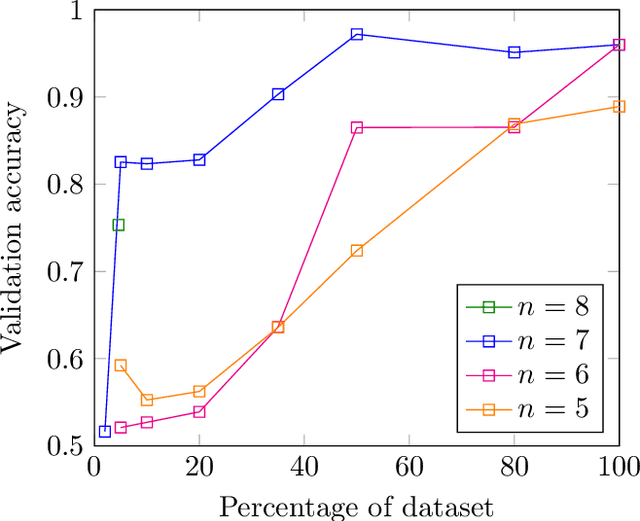
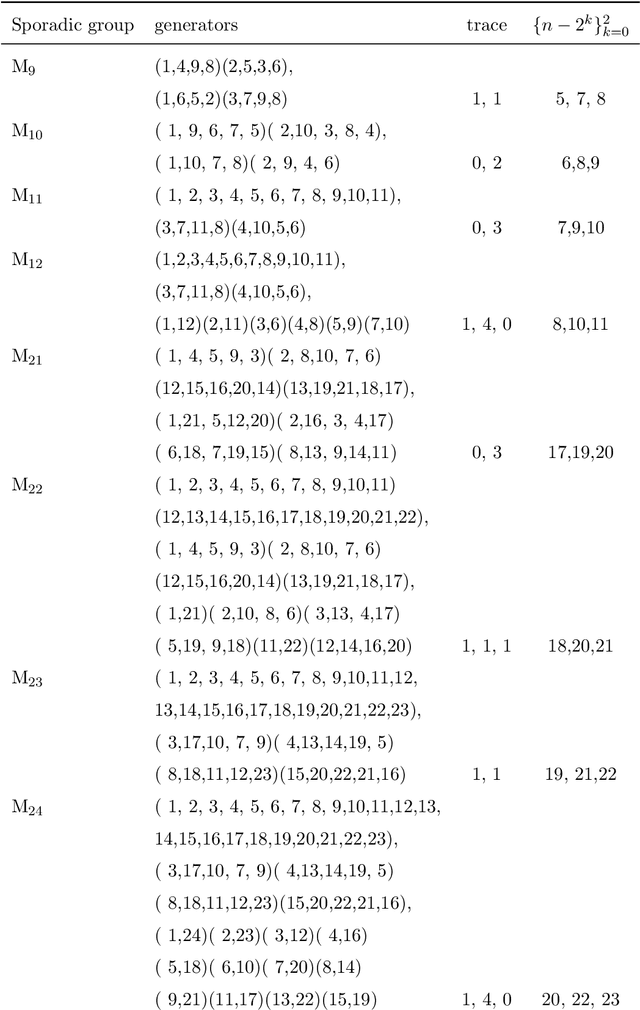
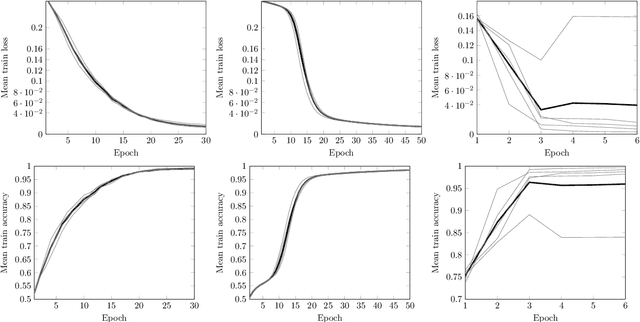
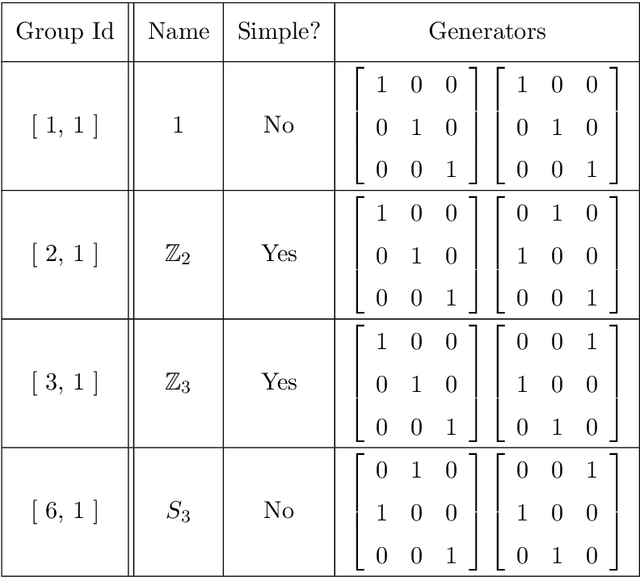
In this work we employ machine learning to understand structured mathematical data involving finite groups and derive a theorem about necessary properties of generators of finite simple groups. We create a database of all 2-generated subgroups of the symmetric group on n-objects and conduct a classification of finite simple groups among them using shallow feed-forward neural networks. We show that this neural network classifier can decipher the property of simplicity with varying accuracies depending on the features. Our neural network model leads to a natural conjecture concerning the generators of a finite simple group. We subsequently prove this conjecture. This new toy theorem comments on the necessary properties of generators of finite simple groups. We show this explicitly for a class of sporadic groups for which the result holds. Our work further makes the case for a machine motivated study of algebraic structures in pure mathematics and highlights the possibility of generating new conjectures and theorems in mathematics with the aid of machine learning.
Machine Learned Calabi--Yau Metrics and Curvature
Nov 17, 2022



Finding Ricci-flat (Calabi--Yau) metrics is a long standing problem in geometry with deep implications for string theory and phenomenology. A new attack on this problem uses neural networks to engineer approximations to the Calabi--Yau metric within a given K\"ahler class. In this paper we investigate numerical Ricci-flat metrics over smooth and singular K3 surfaces and Calabi--Yau threefolds. Using these Ricci-flat metric approximations for the Cefal\'u and Dwork family of quartic twofolds and the Dwork family of quintic threefolds, we study characteristic forms on these geometries. Using persistent homology, we show that high curvature regions of the manifolds form clusters near the singular points, but also elsewhere. For our neural network approximations, we observe a Bogomolov--Yau type inequality $3c_2 \geq c_1^2$ and observe an identity when our geometries have isolated $A_1$ type singularities. We sketch a proof that $\chi(X~\smallsetminus~\mathrm{Sing}\,{X}) + 2~|\mathrm{Sing}\,{X}| = 24$ also holds for our numerical approximations.
Towards Quantum Advantage on Noisy Quantum Computers
Sep 27, 2022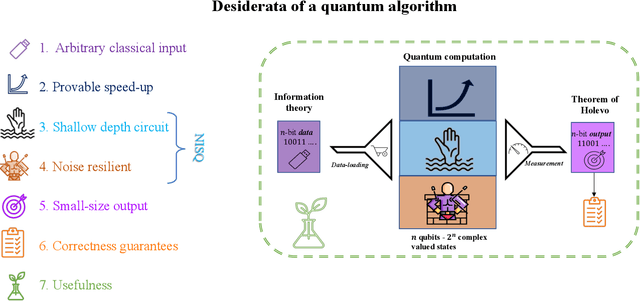

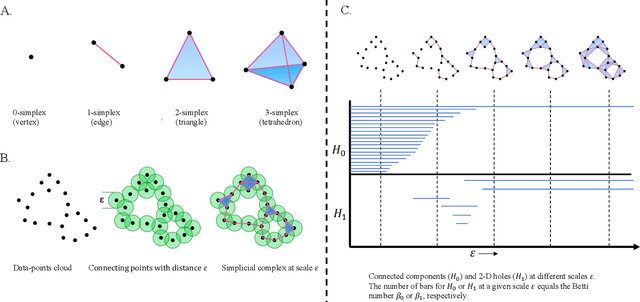
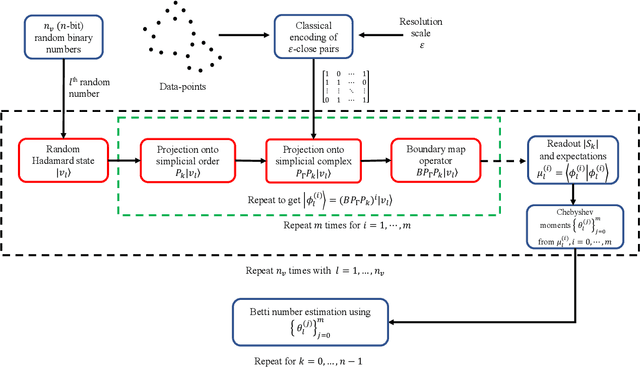
Topological data analysis (TDA) is a powerful technique for extracting complex and valuable shape-related summaries of high-dimensional data. However, the computational demands of classical TDA algorithms are exorbitant, and quickly become impractical for high-order characteristics. Quantum computing promises exponential speedup for certain problems. Yet, many existing quantum algorithms with notable asymptotic speedups require a degree of fault tolerance that is currently unavailable. In this paper, we present NISQ-TDA, the first fully implemented end-to-end quantum machine learning algorithm needing only a linear circuit-depth, that is applicable to non-handcrafted high-dimensional classical data, with potential speedup under stringent conditions. The algorithm neither suffers from the data-loading problem nor does it need to store the input data on the quantum computer explicitly. Our approach includes three key innovations: (a) an efficient realization of the full boundary operator as a sum of Pauli operators; (b) a quantum rejection sampling and projection approach to restrict a uniform superposition to the simplices of the desired order in the complex; and (c) a stochastic rank estimation method to estimate the topological features in the form of approximate Betti numbers. We present theoretical results that establish additive error guarantees for NISQ-TDA, and the circuit and computational time and depth complexities for exponentially scaled output estimates, up to the error tolerance. The algorithm was successfully executed on quantum computing devices, as well as on noisy quantum simulators, applied to small datasets. Preliminary empirical results suggest that the algorithm is robust to noise.
Identifying equivalent Calabi--Yau topologies: A discrete challenge from math and physics for machine learning
Feb 15, 2022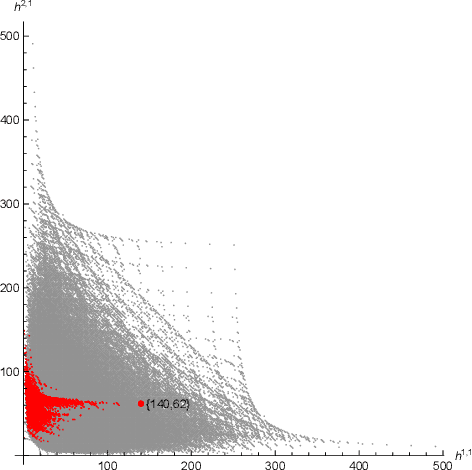
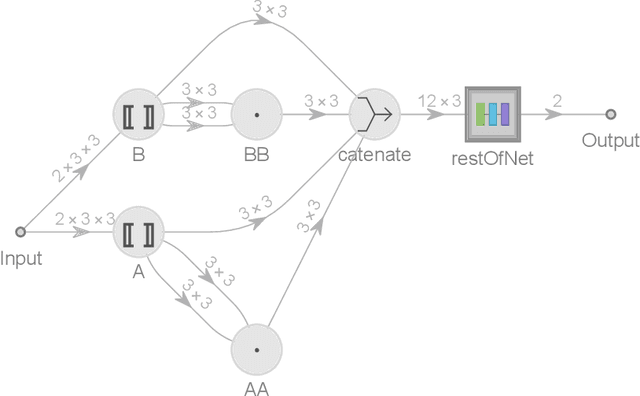
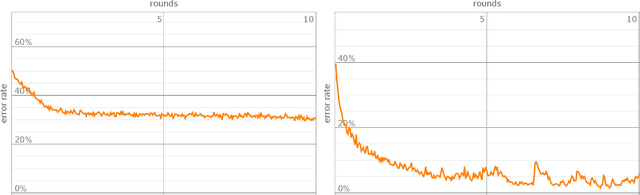
We review briefly the characteristic topological data of Calabi--Yau threefolds and focus on the question of when two threefolds are equivalent through related topological data. This provides an interesting test case for machine learning methodology in discrete mathematics problems motivated by physics.
Machine Learning Kreuzer--Skarke Calabi--Yau Threefolds
Dec 16, 2021Using a fully connected feedforward neural network we study topological invariants of a class of Calabi--Yau manifolds constructed as hypersurfaces in toric varieties associated with reflexive polytopes from the Kreuzer--Skarke database. In particular, we find the existence of a simple expression for the Euler number that can be learned in terms of limited data extracted from the polytope and its dual.