 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEFTune: Noisy Embeddings Improve Instruction Finetuning
Oct 10, 2023



We show that language model finetuning can be improved, sometimes dramatically, with a simple augmentation. NEFTune adds noise to the embedding vectors during training. Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
Universal Guidance for Diffusion Models
Feb 14, 2023



Typical diffusion models are trained to accept a particular form of conditioning, most commonly text, and cannot be conditioned on other modalities without retraining. In this work, we propose a universal guidance algorithm that enables diffusion models to be controlled by arbitrary guidance modalities without the need to retrain any use-specific components. We show that our algorithm successfully generates quality images with guidance functions including segmentation, face recognition, object detection, and classifier signals. Code is available at https://github.com/arpitbansal297/Universal-Guided-Diffusion.
Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise
Aug 19, 2022



Standard diffusion models involve an image transform -- adding Gaussian noise -- and an image restoration operator that inverts this degradation. We observe that the generative behavior of diffusion models is not strongly dependent on the choice of image degradation, and in fact an entire family of generative models can be constructed by varying this choice. Even when using completely deterministic degradations (e.g., blur, masking, and more), the training and test-time update rules that underlie diffusion models can be easily generalized to create generative models. The success of these fully deterministic models calls into question the community's understanding of diffusion models, which relies on noise in either gradient Langevin dynamics or variational inference, and paves the way for generalized diffusion models that invert arbitrary processes. Our code is available at https://github.com/arpitbansal297/Cold-Diffusion-Models
Active Learning at the ImageNet Scale
Nov 25, 2021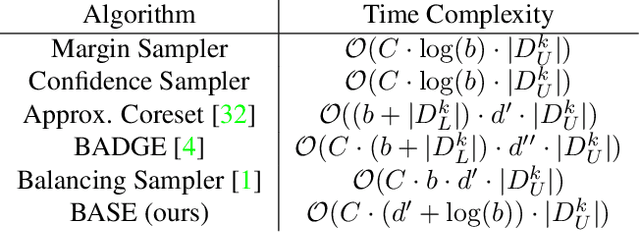
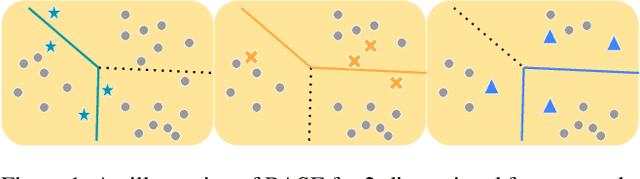

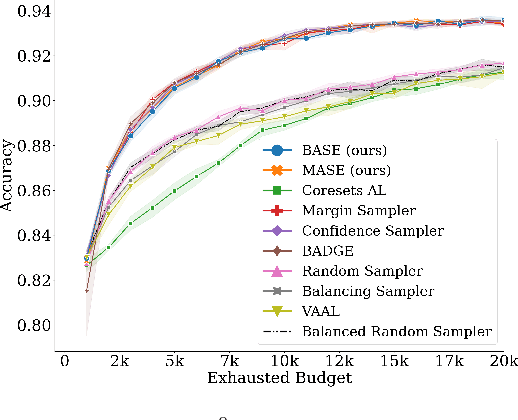
Active learning (AL) algorithms aim to identify an optimal subset of data for annotation, such that deep neural networks (DNN) can achieve better performance when trained on this labeled subset. AL is especially impactful in industrial scale settings where data labeling costs are high and practitioners use every tool at their disposal to improve model performance. The recent success of self-supervised pretraining (SSP) highlights the importance of harnessing abundant unlabeled data to boost model performance. By combining AL with SSP, we can make use of unlabeled data while simultaneously labeling and training on particularly informative samples. In this work, we study a combination of AL and SSP on ImageNet. We find that performance on small toy datasets -- the typical benchmark setting in the literature -- is not representative of performance on ImageNet due to the class imbalanced samples selected by an active learner. Among the existing baselines we test, popular AL algorithms across a variety of small and large scale settings fail to outperform random sampling. To remedy the class-imbalance problem, we propose Balanced Selection (BASE), a simple, scalable AL algorithm that outperforms random sampling consistently by selecting more balanced samples for annotation than existing methods. Our code is available at: https://github.com/zeyademam/active_learning .
Deep Learning with a Rethinking Structure for Multi-label Classification
Feb 05, 2018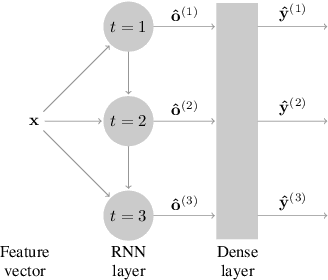

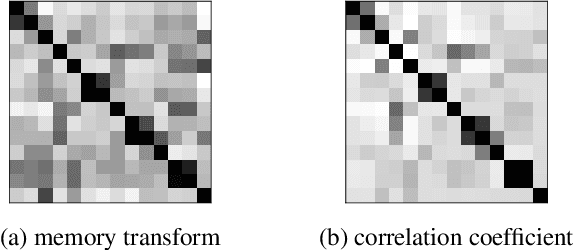
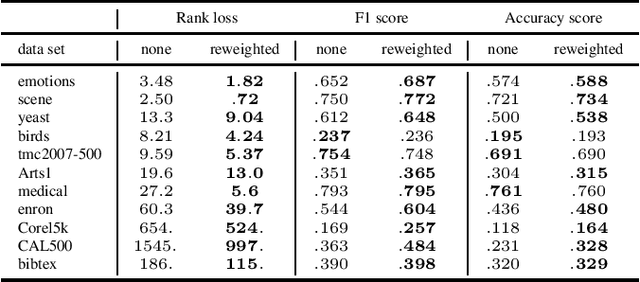
Multi-label classification (MLC) is an important learning problem that expects the learning algorithm to take the hidden correlation of the labels into account. Extracting the hidden correlation is generally a challenging task. In this work, we propose a novel deep learning framework to better extract the hidden correlation with the help of the memory structure within recurrent neural networks. The memory stores the temporary guesses on the labels and effectively allows the framework to rethink about the goodness and correlation of the guesses before making the final prediction. Furthermore, the rethinking process makes it easy to adapt to different evaluation criterion to match real-world application needs. Experimental results across many real-world data sets justify that the rethinking process indeed improves MLC performance across different evaluation criteria and leads to superior performance over state-of-the-art MLC algorithms.
Dynamic Principal Projection for Cost-Sensitive Online Multi-Label Classification
Nov 14, 2017
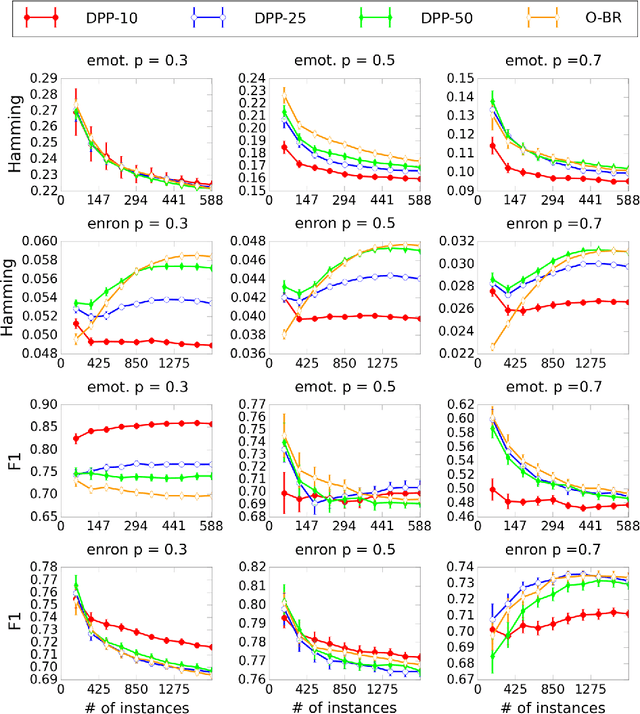
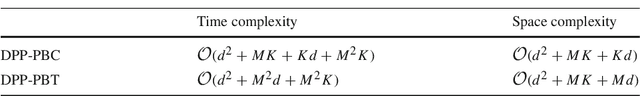
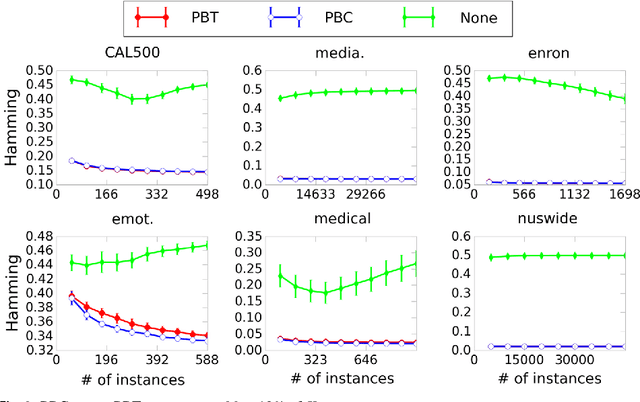
We study multi-label classification (MLC) with three important real-world issues: online updating, label space dimensional reduction (LSDR), and cost-sensitivity. Current MLC algorithms have not been designed to address these three issues simultaneously. In this paper, we propose a novel algorithm, cost-sensitive dynamic principal projection (CS-DPP) that resolves all three issues. The foundation of CS-DPP is an online LSDR framework derived from a leading LSDR algorithm. In particular, CS-DPP is equipped with an efficient online dimension reducer motivated by matrix stochastic gradient, and establishes its theoretical backbone when coupled with a carefully-designed online regression learner. In addition, CS-DPP embeds the cost information into label weights to achieve cost-sensitivity along with theoretical guarantees. Experimental results verify that CS-DPP achieves better practical performance than current MLC algorithms across different evaluation criteria, and demonstrate the importance of resolving the three issues simultaneously.
Can Active Learning Experience Be Transferred?
Aug 02, 2016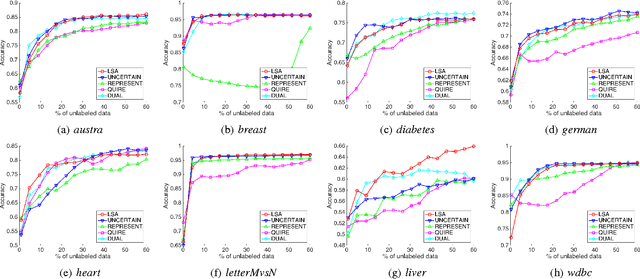
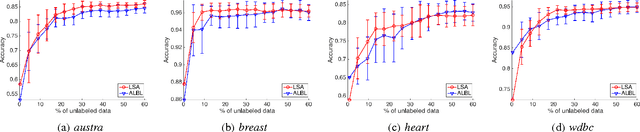
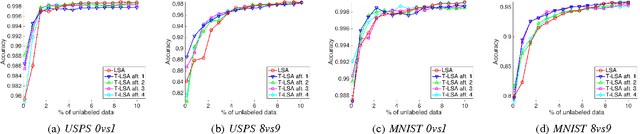
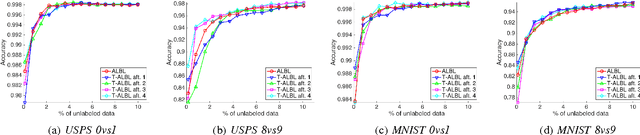
Active learning is an important machine learning problem in reducing the human labeling effort. Current active learning strategies are designed from human knowledge, and are applied on each dataset in an immutable manner. In other words, experience about the usefulness of strategies cannot be updated and transferred to improve active learning on other datasets. This paper initiates a pioneering study on whether active learning experience can be transferred. We first propose a novel active learning model that linearly aggregates existing strategies. The linear weights can then be used to represent the active learning experience. We equip the model with the popular linear upper- confidence-bound (LinUCB) algorithm for contextual bandit to update the weights. Finally, we extend our model to transfer the experience across datasets with the technique of biased regularization. Empirical studies demonstrate that the learned experience not only is competitive with existing strategies on most single datasets, but also can be transferred across datasets to improve the performance on future learning tasks.