 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePear: Pruning and Sharing Adapters in Visual Parameter-Efficient Fine-Tuning
Sep 29, 2024Adapters have been widely explored to alleviate computational and storage costs when fine-tuning pretrained foundation models. However, the adapter itself can exhibit redundancy, leading to unnecessary storage overhead and inferior performance. In this paper, we propose Prune and Share (Pear), a novel adapter-pruning framework for efficient fine-tuning of pretrained visual foundation models. Specifically, we prune certain adapters and share the more important unpruned ones with positions where adapters are pruned, allowing continual adaptation at these positions after pruning. Additionally, a knowledge checkpoint strategy is introduced, which preserves the information of the pruned adapters and further boosts performance. Experimental results on visual adaptation benchmark validate the effectiveness and efficiency of the proposed Pear comparing to other competitive methods. Code is in https://github.com/yibozhong/pear.
Low-Rank Interconnected Adaptation Across Layers
Jul 13, 2024Low-rank adaptation (LoRA), as one of the most well-known representative methods of parameter-efficient fine-tuning, freezes the backbone model and introduces parallel adapter modules to each layer of the model. These modules consist of two low-rank trainable matrices: a low-dimension projector (LP) and a high-dimension projector (HP) with their product approximating the change for updating the model weight. However, LoRA's paired LP and HP per layer limit learned weights to specific features, ignoring the varied information extracted by stacked layers in models like Transformers. By considering the differences between layers and establishing connections across them when learning the weights, we enhance the capture of relevant information for downstream tasks using this interconnected adaptation when fine-tuning. Meanwhile, preserving the unique characteristics of each layer and thus selectively mix the learning traits of various layers according to a specific ratio can also be crucial in certain tasks. In this paper, we propose Low-rank Interconnected adaptation across layers (Lily). Specifically, we retain layer-specific LPs (local LPs) for low-dimensional feature projection and unify all HPs into a model-wide global HP, thereby overcoming layer-specific constraints in LoRA. The global HP, layer-independent, supports multiple HP sub-modules, or inspired by Mixture of Experts (MoE), HP experts capturing learning traits across all layer depths. For the ratio to mix all the experts, we use a router inspired by MoE to selectively adapt the features of different layers, thus obtaining a unique expert distribution. We evaluated Lily on a wide range of downstream tasks and achieved state-of-the-art results, outperforming LoRA and a range of competitive methods. Code will be available at https://github.com/blameitonme1/lily.
HEAT: Head-level Parameter Efficient Adaptation of Vision Transformers with Taylor-expansion Importance Scores
Apr 13, 2024Prior computer vision research extensively explores adapting pre-trained vision transformers (ViT) to downstream tasks. However, the substantial number of parameters requiring adaptation has led to a focus on Parameter Efficient Transfer Learning (PETL) as an approach to efficiently adapt large pre-trained models by training only a subset of parameters, achieving both parameter and storage efficiency. Although the significantly reduced parameters have shown promising performance under transfer learning scenarios, the structural redundancy inherent in the model still leaves room for improvement, which warrants further investigation. In this paper, we propose Head-level Efficient Adaptation with Taylor-expansion importance score (HEAT): a simple method that efficiently fine-tuning ViTs at head levels. In particular, the first-order Taylor expansion is employed to calculate each head's importance score, termed Taylor-expansion Importance Score (TIS), indicating its contribution to specific tasks. Additionally, three strategies for calculating TIS have been employed to maximize the effectiveness of TIS. These strategies calculate TIS from different perspectives, reflecting varying contributions of parameters. Besides ViT, HEAT has also been applied to hierarchical transformers such as Swin Transformer, demonstrating its versatility across different transformer architectures. Through extensive experiments, HEAT has demonstrated superior performance over state-of-the-art PETL methods on the VTAB-1K benchmark.
Side Information-Driven Session-based Recommendation: A Survey
Feb 27, 2024


The session-based recommendation (SBR) garners increasing attention due to its ability to predict anonymous user intents within limited interactions. Emerging efforts incorporate various kinds of side information into their methods for enhancing task performance. In this survey, we thoroughly review the side information-driven session-based recommendation from a data-centric perspective. Our survey commences with an illustration of the motivation and necessity behind this research topic. This is followed by a detailed exploration of various benchmarks rich in side information, pivotal for advancing research in this field. Moreover, we delve into how these diverse types of side information enhance SBR, underscoring their characteristics and utility. A systematic review of research progress is then presented, offering an analysis of the most recent and representative developments within this topic. Finally, we present the future prospects of this vibrant topic.
MeKB-Rec: Personal Knowledge Graph Learning for Cross-Domain Recommendation
Oct 17, 2023It is a long-standing challenge in modern recommender systems to effectively make recommendations for new users, namely the cold-start problem. Cross-Domain Recommendation (CDR) has been proposed to address this challenge, but current ways to represent users' interests across systems are still severely limited. We introduce Personal Knowledge Graph (PKG) as a domain-invariant interest representation, and propose a novel CDR paradigm named MeKB-Rec. We first link users and entities in a knowledge base to construct a PKG of users' interests, named MeKB. Then we learn a semantic representation of MeKB for the cross-domain recommendation. To efficiently utilize limited training data in CDR, MeKB-Rec employs Pretrained Language Models to inject world knowledge into understanding users' interests. Beyond most existing systems, our approach builds a semantic mapping across domains which breaks the requirement for in-domain user behaviors, enabling zero-shot recommendations for new users in a low-resource domain. We experiment MeKB-Rec on well-established public CDR datasets, and demonstrate that the new formulation % is more powerful than previous approaches, achieves a new state-of-the-art that significantly improves HR@10 and NDCG@10 metrics over best previous approaches by 24\%--91\%, with a 105\% improvement for HR@10 of zero-shot users with no behavior in the target domain. We deploy MeKB-Rec in WeiXin recommendation scenarios and achieve significant gains in core online metrics. MeKB-Rec is now serving hundreds of millions of users in real-world products.
Retrieval-based Knowledge Augmented Vision Language Pre-training
Apr 27, 2023With recent progress in large-scale vision and language representation learning, Vision Language Pretraining (VLP) models have achieved promising improvements on various multi-modal downstream tasks. Albeit powerful, these pre-training models still do not take advantage of world knowledge, which is implicit in multi-modal data but comprises abundant and complementary information. In this work, we propose a REtrieval-based knowledge Augmented Vision Language Pre-training model (REAVL), which retrieves world knowledge from knowledge graphs (KGs) and incorporates them in vision-language pre-training. REAVL has two core components: a knowledge retriever that retrieves knowledge given multi-modal data, and a knowledge-augmented model that fuses multi-modal data and knowledge. By novelly unifying four knowledge-aware self-supervised tasks, REAVL promotes the mutual integration of multi-modal data and knowledge by fusing explicit knowledge with vision-language pairs for masked multi-modal data modeling and KG relational reasoning. Empirical experiments show that REAVL achieves new state-of-the-art performance uniformly on knowledge-based vision-language understanding and multimodal entity linking tasks, and competitive results on general vision-language tasks while only using 0.2% pre-training data of the best models.
Towards High-Order Complementary Recommendation via Logical Reasoning Network
Dec 09, 2022



Complementary recommendation gains increasing attention in e-commerce since it expedites the process of finding frequently-bought-with products for users in their shopping journey. Therefore, learning the product representation that can reflect this complementary relationship plays a central role in modern recommender systems. In this work, we propose a logical reasoning network, LOGIREC, to effectively learn embeddings of products as well as various transformations (projection, intersection, negation) between them. LOGIREC is capable of capturing the asymmetric complementary relationship between products and seamlessly extending to high-order recommendations where more comprehensive and meaningful complementary relationship is learned for a query set of products. Finally, we further propose a hybrid network that is jointly optimized for learning a more generic product representation. We demonstrate the effectiveness of our LOGIREC on multiple public real-world datasets in terms of various ranking-based metrics under both low-order and high-order recommendation scenarios.
A Neural Vocoder Based Packet Loss Concealment Algorithm
Mar 26, 2022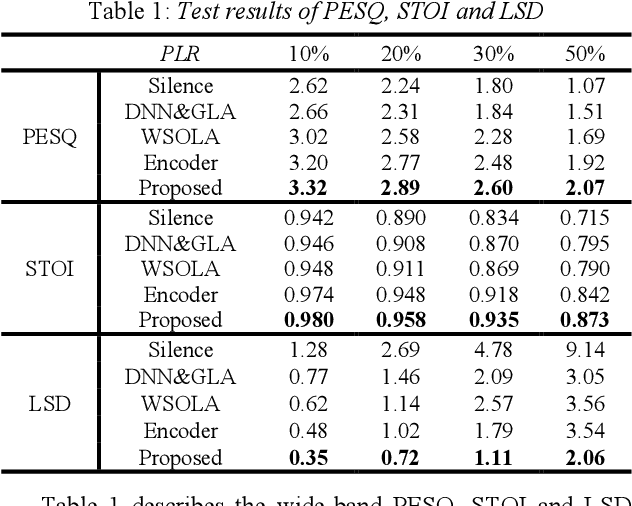
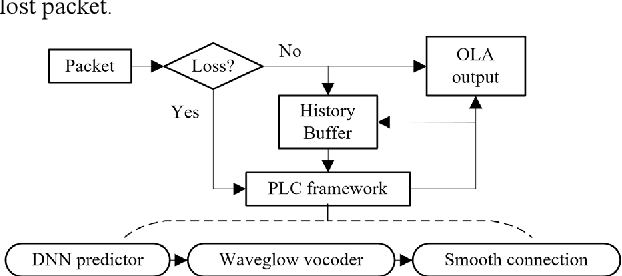
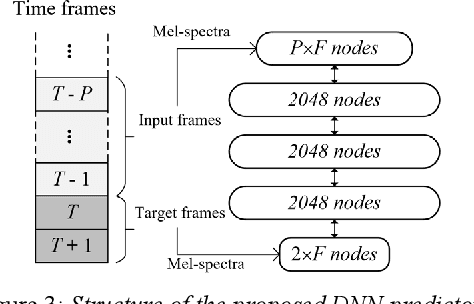
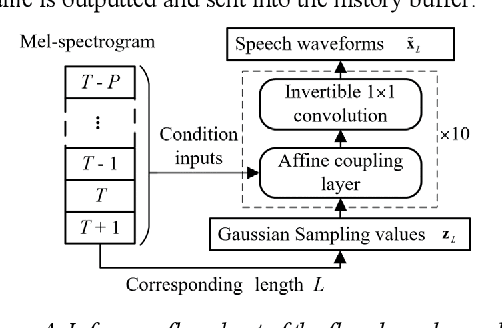
The packet loss problem seriously affects the quality of service in Voice over IP (VoIP) sceneries. In this paper, we investigated online receiver-based packet loss concealment which is much more portable and applicable. For ensuring the speech naturalness, rather than directly processing time-domain waveforms or separately reconstructing amplitudes and phases in frequency domain, a flow-based neural vocoder is adopted to generate the substitution waveform of lost packet from Mel-spectrogram which is generated from history contents by a well-designed neural predictor. Furthermore, a waveform similarity-based smoothing post-process is created to mitigate the discontinuity of speech and avoid the artifacts. The experimental results show the outstanding performance of the proposed method.
From Intrinsic to Counterfactual: On the Explainability of Contextualized Recommender Systems
Oct 28, 2021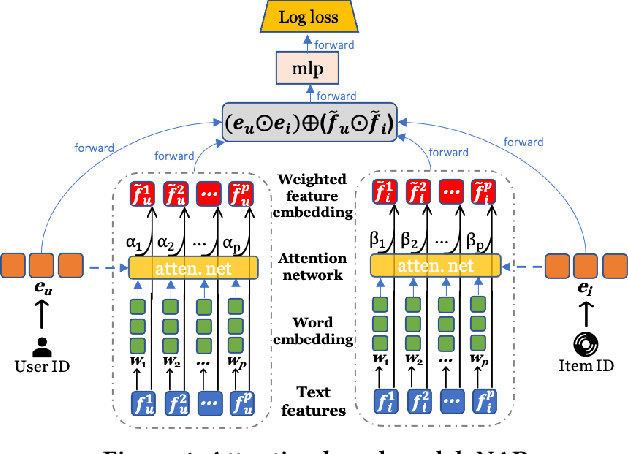

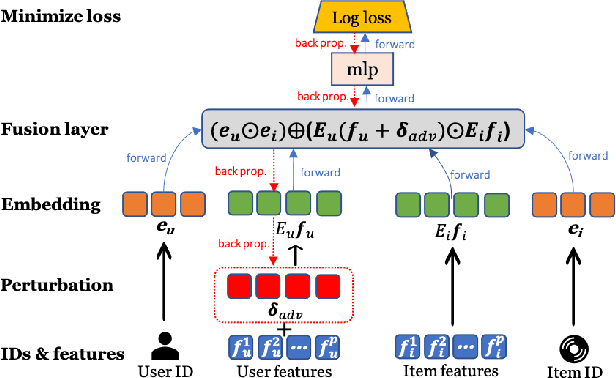
With the prevalence of deep learning based embedding approaches, recommender systems have become a proven and indispensable tool in various information filtering applications. However, many of them remain difficult to diagnose what aspects of the deep models' input drive the final ranking decision, thus, they cannot often be understood by human stakeholders. In this paper, we investigate the dilemma between recommendation and explainability, and show that by utilizing the contextual features (e.g., item reviews from users), we can design a series of explainable recommender systems without sacrificing their performance. In particular, we propose three types of explainable recommendation strategies with gradual change of model transparency: whitebox, graybox, and blackbox. Each strategy explains its ranking decisions via different mechanisms: attention weights, adversarial perturbations, and counterfactual perturbations. We apply these explainable models on five real-world data sets under the contextualized setting where users and items have explicit interactions. The empirical results show that our model achieves highly competitive ranking performance, and generates accurate and effective explanations in terms of numerous quantitative metrics and qualitative visualizations.
GAN-based Recommendation with Positive-Unlabeled Sampling
Dec 12, 2020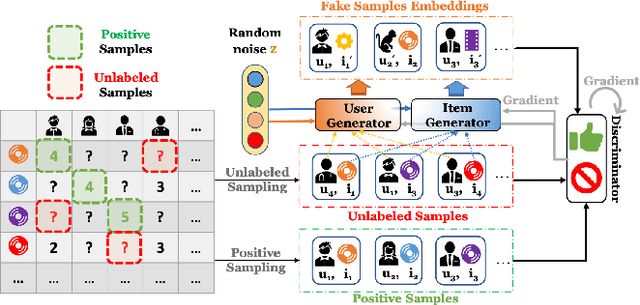
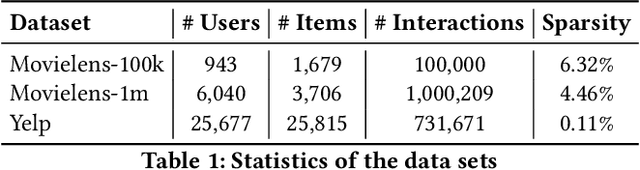
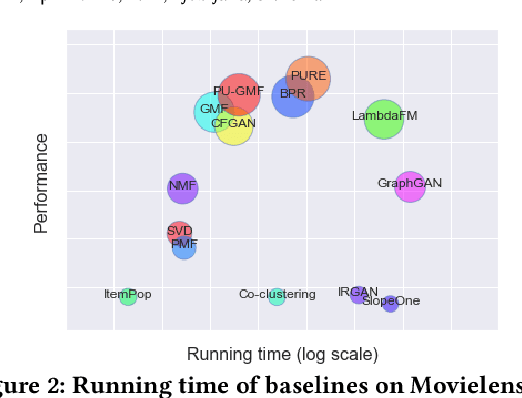
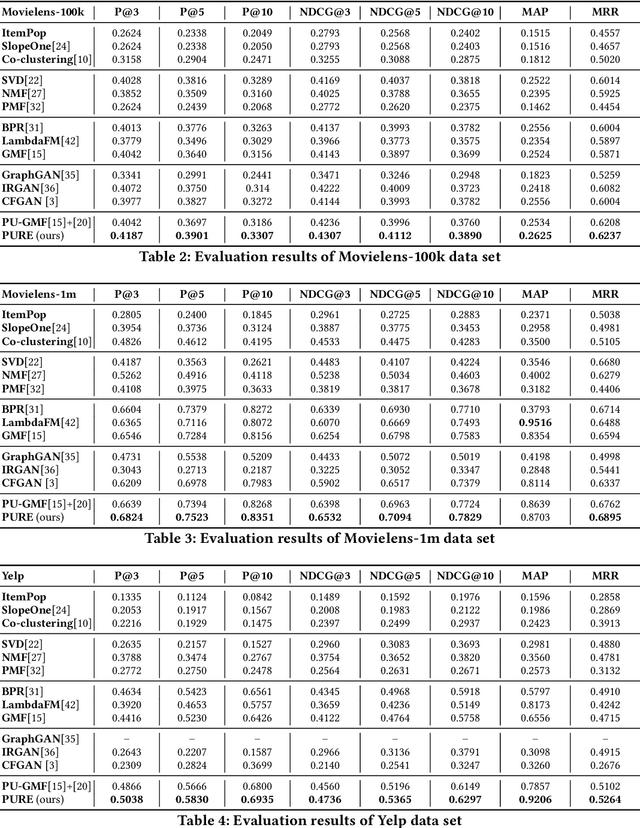
Recommender systems are popular tools for information retrieval tasks on a large variety of web applications and personalized products. In this work, we propose a Generative Adversarial Network based recommendation framework using a positive-unlabeled sampling strategy. Specifically, we utilize the generator to learn the continuous distribution of user-item tuples and design the discriminator to be a binary classifier that outputs the relevance score between each user and each item. Meanwhile, positive-unlabeled sampling is applied in the learning procedure of the discriminator. Theoretical bounds regarding positive-unlabeled sampling and optimalities of convergence for the discriminators and the generators are provided. We show the effectiveness and efficiency of our framework on three publicly accessible data sets with eight ranking-based evaluation metrics in comparison with thirteen popular baselines.